@genkuroki: #統計 私のフォロワーなので、おそらく「どれだけ酷い本である...
@genkuroki
37 views
Oct 21, 2024
1
#統計 私のフォロワーなので、おそらく「どれだけ酷い本であるか」を確認して批判するために購入したのだと思いました。
豊田秀樹『瀕死の統計学を救え!』(以下、豊田瀕死本)によって瀕死なのは豊田さんの信用だと思います。
詳しくは続きを参照。続く
t.co/baxpg4GmBn
豊田秀樹『瀕死の統計学を救え!』(以下、豊田瀕死本)によって瀕死なのは豊田さんの信用だと思います。
詳しくは続きを参照。続く
t.co/baxpg4GmBn
2
#統計 豊田瀕死本関連の情報へのリンクを以下に貼り付けます。
私のツイッターでの発言で、豊田秀樹さんはベイズ統計学に関する最も有害な解説者扱いされています。
↓
twilog.org/genkuroki/sear…
私のツイッターでの発言で、豊田秀樹さんはベイズ統計学に関する最も有害な解説者扱いされています。
↓
twilog.org/genkuroki/sear…
3
#統計 豊田さんが例に出しているphc=「仮説が正しい確率」はP値そのものとみなして問題がないくらいP値をよく近似しているので、豊田さんは
P値の代わりにP値を使うべきである
と主張していることになります。
www
P値の代わりにP値を使うべきである
と主張していることになります。
www
View Tweet
4
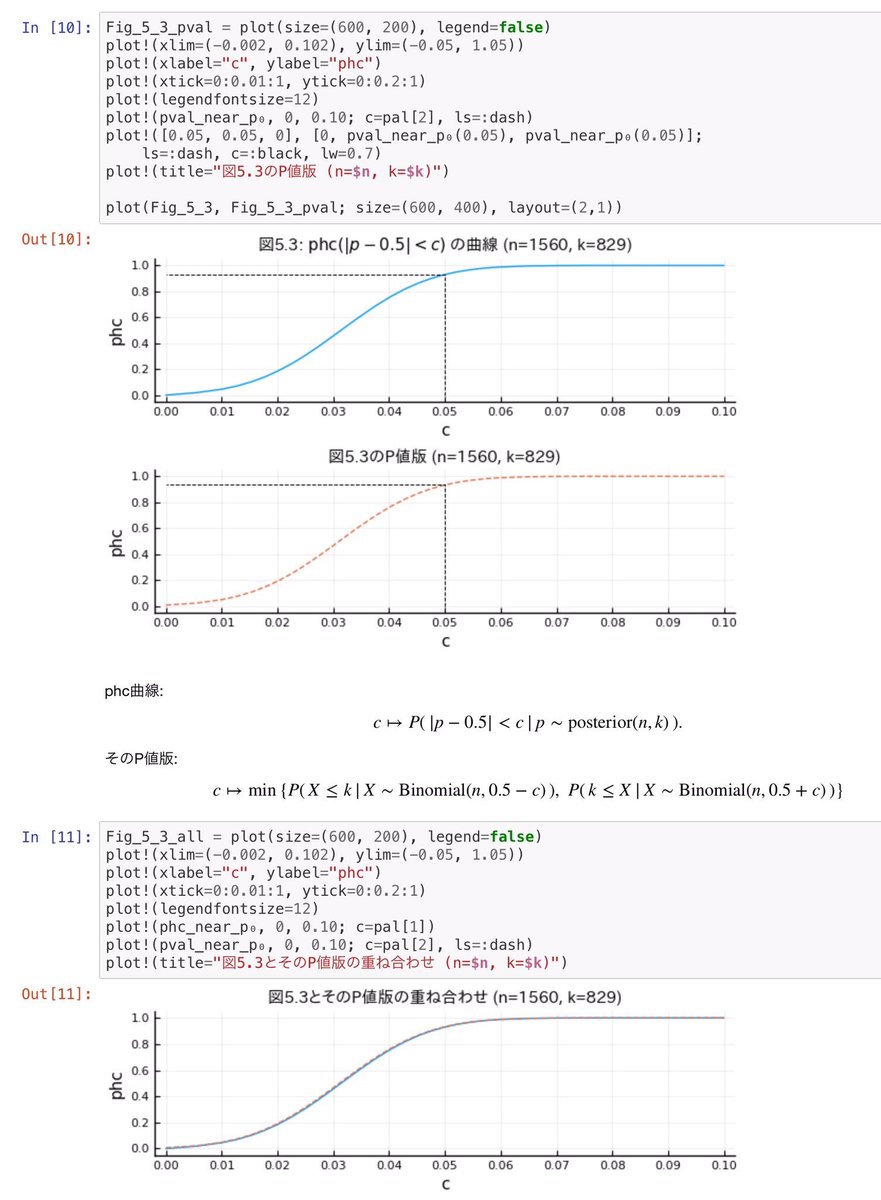
#統計 豊田『瀕死本』でのphcは実質的にP値になっている場合があり、そのことをコンピュータで確認すれば豊田さんのひどさをクリアに理解できます。
私による確認例
↓
nbviewer.org/gist/genkuroki…
豊田『瀕死本』の5.4節について
図5.2,5.3のphcは実質的にP値
私による確認例
↓
nbviewer.org/gist/genkuroki…
豊田『瀕死本』の5.4節について
図5.2,5.3のphcは実質的にP値
View Tweet

5
#統計 通常の統計学の教科書的にシンプルなモデルで検出力を十分に高めるように標本サイズを大きくした場合には、平坦事前分布またはそれに近い事前分布を使ったベイズ統計の結果と非ベイズ統計の結果は数値的に互いに相手をよく近似するようになり、実践的にはほぼ同じもの扱いすることが妥当になる。
6
#統計 豊田『瀕死本』でのphcは実質的にP値そのものになってしまっており、結果的に豊田『瀕死本』は「P値を使うのを止めて、phcという名前に付け直してP値を使うべきだ」と主張していることになります。
こういう極めて滑稽な話になってしまっている。
こういう極めて滑稽な話になってしまっている。
7
#統計 P値は多くの場合に(常にそうであるわけではない点に注意)、パラメータθを持つモデルにおける仮説θ=a(aは具体的な数値)とデータの数値の相性の良さになっています。
仮説θ=aの数値aを動かせることを忘れると、仮説θ=0や仮説θ=1のP値しか考えないというおかしなことになる。
仮説θ=aの数値aを動かせることを忘れると、仮説θ=0や仮説θ=1のP値しか考えないというおかしなことになる。
8
#統計 仮説θ=aのaにP値を対応させるP値函数を考えると、ベイズ統計におけるパラメータθの事後分布と比較できる情報が得られます。
最尤法が有効な場合には、漸近的に、P値函数と事後分布は同じ情報を持っていることを数学的に示せます。(超大雑把な説明なことに注意!)
最尤法が有効な場合には、漸近的に、P値函数と事後分布は同じ情報を持っていることを数学的に示せます。(超大雑把な説明なことに注意!)
9
#統計 そういう場合に「ベイズ vs 非ベイズ」という対立図式を立てても無意味。豊田さんがここ数年のあいだやっていることはまさにそれで、個人的な意見ではベイズ統計の日本語による解説者として最悪の行為をしていると思います。
10
#統計 「ベイズも非ベイズもどちらも有用な道具だよね」という穏健な立場を捨てて、非論理的で過激なスタイルでおかしなことを述べるのはやめた方がよいと思う。
11
#統計 こういう話題と、natureに掲載された「800人以上の科学者達が統計的有意性に反対した」という有名な記事などとの関係については以下のリンク先スレッドを参照。
その記事の共著者3名のうちの2名がP値函数の使い方の解説を書いていることに注目!
その記事の共著者3名のうちの2名がP値函数の使い方の解説を書いていることに注目!
View Tweet
12
#統計 「800人以上の科学者達が統計的有意性に反対した」という有名な記事そのものを見ても、その記事を書いた人達が書いた別の論文を見ても、P値の利用に反対するどころか、P値函数の使い方に関する最良の解説を書いていたりするわけです。
そういう大きな流れから豊田さんは隔絶されています。
そういう大きな流れから豊田さんは隔絶されています。
13
#統計 「統計的有意性」と「P値」の使用を同じだと誤解している人達は最近の論文
journals.sagepub.com/doi/10.1177/02…
のタイトルに "not only on point estimates and null p-values" とあることに注目するとよいと思います。続く
journals.sagepub.com/doi/10.1177/02…
のタイトルに "not only on point estimates and null p-values" とあることに注目するとよいと思います。続く
14
#統計 一般に、統計学的には点推定の結果だけを報告してはダメで、必ずその誤差の大きさの見積もりも報告しなければいけないことになっています。
だから、"not only on point estimates" の部分は常識の範囲内だと思います。続く
だから、"not only on point estimates" の部分は常識の範囲内だと思います。続く
15
#統計 "not only on ~ null P-values"におけるnull P値は「違いがない」や「効果なし」を意味する特殊な帰無仮説単独のP値のことです。
「違いはaである」(aは数値)のような仮説各々のP値をすべて考慮することと、null P値だけしか考慮しないことの違いは大きい。続く
「違いはaである」(aは数値)のような仮説各々のP値をすべて考慮することと、null P値だけしか考慮しないことの違いは大きい。続く
16
#統計 続き。null P値しか考えないことと、仮説θ=a達のP値をすべて考えることの違いが結構重要なことに気付けば、null P値しか使わない「統計的有意性」に反対してかつ「P値」の使用を積極的に進めることの整合性を理解できます。
17
#統計 そして、仮説θ=aの数値aにP値を対応させるP値函数とベイズ統計における事後分布の漸近的な関係を理解していれば、ベイズ統計が漸近的に通常のP値を使う方法の漸近的な上位互換(ただし計算量的にトレードオフがある)だと理解できます。
これはベイズ統計好きの人にとってうれしいボーナス。
これはベイズ統計好きの人にとってうれしいボーナス。
18
#統計 そして、通常のP値を使う統計学の手法を実践的に役立てて来た人達にとって、ベイズ統計を「異なる思想哲学主義に基く、全く別の統計学」だと誤解することなく、普段使っている統計学的手法の延長として正常に理解する道も開けます。
こういう道を潰そうとする行為が横行している。
こういう道を潰そうとする行為が横行している。
19
#統計 「心理学や生物学など p値が 0.05 を下回るか否かで論文の採否が決まりがちな分野において、p値よりもPHCを示す方向に改革すべし」という豊田さんの主張中のphcは実質p値なので、その豊田さんの主張は滑稽な主張扱いが妥当です。
View Tweet
20
#統計 結構、統計学入門レベルの話(例えば二項分布モデルでの各種のP値の定義とその基本性質)について全然理解できていない状態で、豊田『瀕死本』を読むと、phcがもろにP値と一致している場合が扱われていることに気付かずに騙されてしまいます。
結構基本を理解できていない人は多い。
結構基本を理解できていない人は多い。
21
#統計 二項分布モデルの統計学の基本の1つにClopper-Pearsonの信頼区間をベータ分布を使って計算できるという話があります。そのベータ分布はimproper事前分布の事後分布とみなされるので、ベイズ統計と非ベイズ統計の関係を扱っていることになります。
まずは信頼区間について勉強することが大事。
まずは信頼区間について勉強することが大事。
22
#統計 通常の信頼区間について理解せずに、「ベイズ vs. 頻度論」の悪しき図式を描いて大恥をかいているように見えるケースにJaynes 1976があります。
へたに対立図式を描くと大恥をかくことがあるので、「ベイズも非ベイズも有用な道具だよね」で通した方が無難(笑)
へたに対立図式を描くと大恥をかくことがあるので、「ベイズも非ベイズも有用な道具だよね」で通した方が無難(笑)
View Tweet
23
#統計 豊田さんは特に疫学方面の人達が発展させて来たP値函数の使い方などについて全く無知な様子が見られます。
「800人以上の科学者が統計的有意性に反対した」というnarureの有名な記事の共著者のうちの2人が書いた journals.sagepub.com/doi/10.1177/02… を読んだ方がよいです。
「800人以上の科学者が統計的有意性に反対した」というnarureの有名な記事の共著者のうちの2人が書いた journals.sagepub.com/doi/10.1177/02… を読んだ方がよいです。
View Tweet
24
#統計 「違いはない」の型の特殊な帰無仮説のP値が5%を切ったかどうかで勝負を決しようとする行為が科学的にバカげていることは当たり前の話で、まともな人であればみんな否定しています。否定できない人は非科学的であると断じて問題ない。
それとP値の使用に反対することは全然別の話になります。
それとP値の使用に反対することは全然別の話になります。
25
#統計 「違いはない」の型の特殊な帰無仮説のP値が5%を切ったかどうかで勝負を決しようとする行為がまともだとみなされていた分野が仮に存在するとすれば、その分野を構成している人達の知的レベルに問題があることになります。
知的レベルが低い人達の問題をP値の問題にしてしまうのは非常にまずい。
知的レベルが低い人達の問題をP値の問題にしてしまうのは非常にまずい。
26
#統計 Clopper-Pearsonの信頼区間がimproper事前分布に対応する事後分布として現れるベータ分布を使って計算できることについては私のツイログ検索を参照
↓
twilog.org/genkuroki/sear…
解説
↓
nbviewer.org/github/genkuro…
ツイログ検索で見つけた
↓
↓
twilog.org/genkuroki/sear…
解説
↓
nbviewer.org/github/genkuro…
ツイログ検索で見つけた
↓
View Tweet
27
#統計 お勧めの論文 journals.sagepub.com/doi/10.1177/02… に登場するP値函数については、二項分布モデルの場合の定義とグラフが(既出の) nbviewer.org/github/genkuro… にあります。易しい内容なので、これを読んでおけば、論文の内容もすぐに理解できると思います。論文も分かり易く平易に書かれています。
28
#統計 豊田さんの本で扱っているようなシンプルなモデルでは漸近的に違いがなくなることを証明可能。
標本サイズが小さい場合には、信頼区間が広くなり過ぎてダメな場合が多く、ベイズでは事前分布を狭くすれば信用区間も狭くできるが、豊田さんはそういう話はしていない。
標本サイズが小さい場合には、信頼区間が広くなり過ぎてダメな場合が多く、ベイズでは事前分布を狭くすれば信用区間も狭くできるが、豊田さんはそういう話はしていない。
View Tweet
29
#統計 シンプルなモデル+おとなしめの事前分布という豊田さんも採用している設定で、ベイズと非ベイズの結果が数値的によく一致することは昔からよく知られていることです。
わざわざそういう場合を選んで豊田さんはP値の使用を否定しているわけ。
わざわざそういう場合を選んで豊田さんはP値の使用を否定しているわけ。
View Tweet
30
#統計 数学の利用時に注意しなければいけないことは、定義が違っていても、数値的にぴったりまたは近似的(漸近的)に一致することを証明できてしまう場合が珍しくないこと。
定義が違うことにこだわり過ぎると容易にはまる。
定義が違うことにこだわり過ぎると容易にはまる。