@genkuroki: #統計 「正規分布でなければt検定は使えない」というデマは、...
@genkuroki
25 views
May 30, 2025
1
#統計 「正規分布でなければt検定は使えない」というデマは、にせマナー講師的な制限のせいで方法選択が歪んでいる問題の1つ。
別のにせマナー講師的言説で有名なのは、「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使わなければいけない」です。これも結構猛威をふるっている感じ。続く
別のにせマナー講師的言説で有名なのは、「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使わなければいけない」です。これも結構猛威をふるっている感じ。続く
View Tweet
2
#統計 2×2の分割表での検定法(母比率の違いに関する検定法)について気になっている問題は2つ。
(1) 「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使うべきである」というデマの普及
(2) 検定仮説を「母比率は等しい」から「母比率の違いはθ=aである」に拡張しない悪しき流儀の普及
(1) 「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使うべきである」というデマの普及
(2) 検定仮説を「母比率は等しい」から「母比率の違いはθ=aである」に拡張しない悪しき流儀の普及
3
#統計 (2)補足
2つの母比率をp,qと書くとき、検定仮説をp=qに固定してしまうと、違いの程度を定量化できなくなります。検定仮説について以下のような拡張を行いたい。具体的数値aに関する
* 仮説p-q=a
* 仮説p/q=a
* オッズ比OR=(p/(1-p))/(q/(q-q))に関する仮説OR=a
2つの母比率をp,qと書くとき、検定仮説をp=qに固定してしまうと、違いの程度を定量化できなくなります。検定仮説について以下のような拡張を行いたい。具体的数値aに関する
* 仮説p-q=a
* 仮説p/q=a
* オッズ比OR=(p/(1-p))/(q/(q-q))に関する仮説OR=a
4
#統計 まず、
(1) 「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使うべきである」というデマの普及
について説明します。このデマは「コクランルール」と呼ばれ、広く普及しており、非常に残念なことに標準的な考え方扱いされています。続く
(1) 「期待度数が5未満ならばχ²検定ではなく、Fisher検定を使うべきである」というデマの普及
について説明します。このデマは「コクランルール」と呼ばれ、広く普及しており、非常に残念なことに標準的な考え方扱いされています。続く
5
#統計 しかし、小標本でのFisher検定には「保守的過ぎる」(P値が大きくなり過ぎる)という欠点があり、χ²検定とFisher検定の選択はトレードオフの問題になるので、小標本ではFisher検定の側を必ず選択しなければいけないという考え方は明瞭に間違っています。
6
#統計 トレードオフに基く正しい判断の仕方は以下の通り。
* 小標本での検出力の低下を受け入れて、αエラー率を確実にα以下にしたいならば、Fisher検定を使う。
* αエラー率が近似的にはαになるが、αを少し超える場合が出て来ることを受け入れて、検出力にも気を使いたいならばχ²検定を使う。
* 小標本での検出力の低下を受け入れて、αエラー率を確実にα以下にしたいならば、Fisher検定を使う。
* αエラー率が近似的にはαになるが、αを少し超える場合が出て来ることを受け入れて、検出力にも気を使いたいならばχ²検定を使う。
7
#統計 小標本であればあるほど、Fisher検定とχ²検定の違いは大きくなり、Fisher検定の過剰に保守的な傾向が強くなるので、小標本の場合には特にFisher検定の欠点の側も気にする必要があります。
「小標本ならば常にFisher検定の側を使え」と教えて来た人達は間違った教育をして来たことになります。
「小標本ならば常にFisher検定の側を使え」と教えて来た人達は間違った教育をして来たことになります。
8
#統計 理解不足を認めずに、論理と証拠ではなく、伝統的な権威に従う人達は、以上の指摘を苦々しく感じ、無視したいと感じるでしょうが、そのように感じている時点で、あなたは非科学的な考え方をしている人になってしまっています。
科学を大事にしたいなら、誤りを認めることから出発するべき。続く
科学を大事にしたいなら、誤りを認めることから出発するべき。続く
9
#統計 Fisher検定が小標本で過剰に保守的になること(P値が大きくなり過ぎること)は、コンピュータシミュレーションによって誰でも簡単に確認できます。
①テストサンプルをランダムに大量に生成してP値を計算する。
②P値≤αとなる割合を計算する。
たったこれだけ。誰でもできる。続く
①テストサンプルをランダムに大量に生成してP値を計算する。
②P値≤αとなる割合を計算する。
たったこれだけ。誰でもできる。続く
10
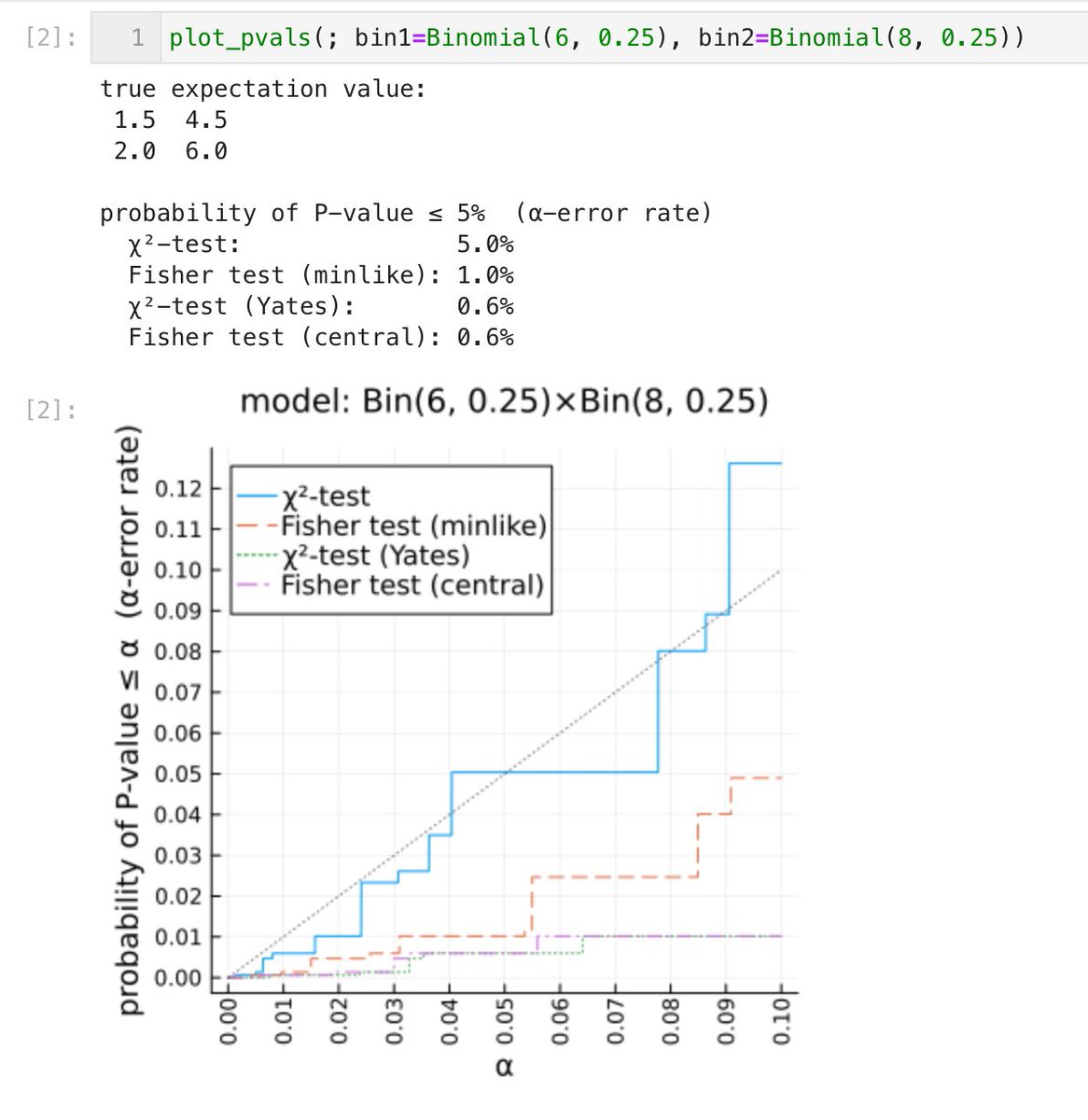
#統計 添付画像は、(a,c)をBin(6,0.25)×Bin(8,0.25)に従う乱数とし、b=6-a, d=8-cとして、分割表のデータ
a b
c d
をランダムに生成したときの、P値≤αとなる確率のグラフです。このとき分割表の期待値は
1.5 4.5
2.0 6.0
で5未満の値が3つもある。続く
github.com/genkuroki/publ…
a b
c d
をランダムに生成したときの、P値≤αとなる確率のグラフです。このとき分割表の期待値は
1.5 4.5
2.0 6.0
で5未満の値が3つもある。続く
github.com/genkuroki/publ…
11
#統計 P値は4種類の方法で計算しました。
* 補正無しχ²検定
* Fisher検定(minlike法、Rのfisher.testの方法)
* Yatesの連続補正版のχ²検定
* Fisher検定(central法、片側確率の2倍でP値を計算)
グラフは「P値≤αとなる確率」のグラフです。続く
github.com/genkuroki/publ…
* 補正無しχ²検定
* Fisher検定(minlike法、Rのfisher.testの方法)
* Yatesの連続補正版のχ²検定
* Fisher検定(central法、片側確率の2倍でP値を計算)
グラフは「P値≤αとなる確率」のグラフです。続く
github.com/genkuroki/publ…

12
#統計 Bin(6, 0.25)×Bin(8, 0.25)は2つの母比率が0.25で等しい場合なので、
* P値≤αとなる確率はα以下であって欲しい
という保守的な要求と、
* P値≤αとなる確率はαで近似されていて欲しい
という検出力も気にする要求の2通りの要求が考えられます。
github.com/genkuroki/publ…
* P値≤αとなる確率はα以下であって欲しい
という保守的な要求と、
* P値≤αとなる確率はαで近似されていて欲しい
という検出力も気にする要求の2通りの要求が考えられます。
github.com/genkuroki/publ…
13
#統計 保守的な要求は、Fisher検定(minlike)とFisher検定(central)では常に満たされていることを数学的に容易に証明できます。
Yates版のχ²検定は保守的度合いが強いFisher検定(central)の良い近似になっているので、実践的には保守的要求を満たすと考えて良いです。続く
github.com/genkuroki/publ…
Yates版のχ²検定は保守的度合いが強いFisher検定(central)の良い近似になっているので、実践的には保守的要求を満たすと考えて良いです。続く
github.com/genkuroki/publ…

14
#統計 数値実験を沢山すれば、補正無しのχ²検定は「帰無仮説下のモデルの確率分布についてP値≤αとなる確率はαで近似されて欲しい」という要求をかなりよく満たしていることが分かります。
ただし、P値≤αとなる確率のグラフが45度線を上側に超える部分も生じてしまいます。
github.com/genkuroki/publ…
ただし、P値≤αとなる確率のグラフが45度線を上側に超える部分も生じてしまいます。
github.com/genkuroki/publ…

15
#統計 印象的なのは、Fisher検定達とYates版χ²検定が小標本で過剰に保守的なことです。添付画像の場合にそれらは、P値≤5%となる確率が、好ましい5%よりも大幅に小さい1%や0.6%になってしまっています。続く
github.com/genkuroki/publ…
github.com/genkuroki/publ…

16
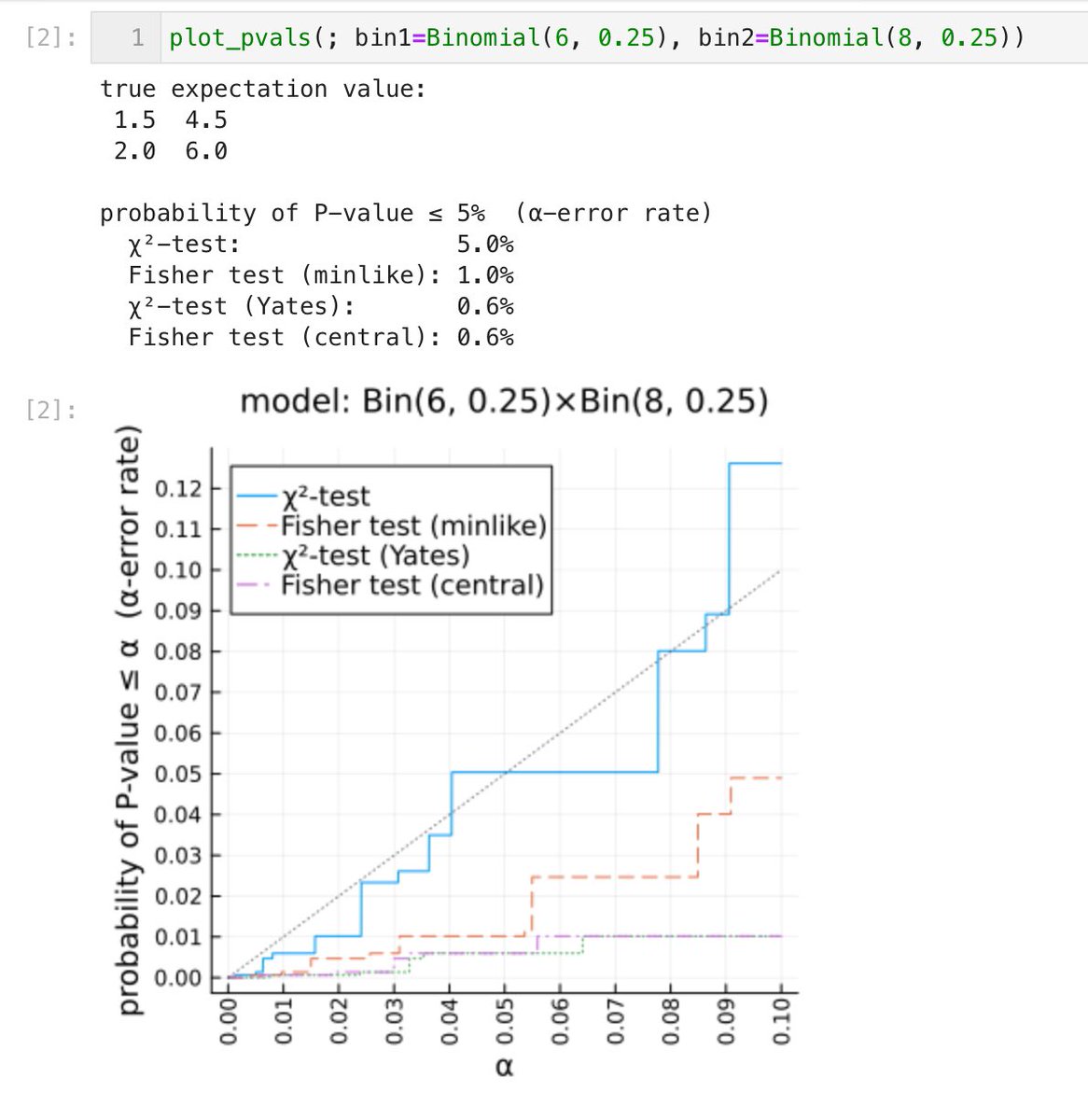
#統計 添付画像は、帰無仮説が満たされていない
Bin(6,0.25)×Bin(8,0.8)
の場合。母比率が0.25と0.8で大幅に違う。
P値≤5%となる確率(検出力)は大きい方がよい。補正無しχ²検定では63%なのに、Fisher検定達とYates版χ²検定では40%未満になっています。
github.com/genkuroki/publ…
Bin(6,0.25)×Bin(8,0.8)
の場合。母比率が0.25と0.8で大幅に違う。
P値≤5%となる確率(検出力)は大きい方がよい。補正無しχ²検定では63%なのに、Fisher検定達とYates版χ²検定では40%未満になっています。
github.com/genkuroki/publ…

17
#統計 このように、小標本においては、Fisher検定達やその保守的な側の良い近似になっているYatesの連続性補正版χ²検定は、補正無しχ²検定との比較で検出力が大幅に低下するという欠点を持ちます。
この事実は古くから知られており、繰り返し指摘されて来ました。続く
github.com/genkuroki/publ…
この事実は古くから知られており、繰り返し指摘されて来ました。続く
github.com/genkuroki/publ…

18
#統計 Fisher検定は、帰無仮説下のモデルの確率分布Bin(m,q)×Bin(n,q)そのものでの正確な確率を計算する方法ではありません。マージンをすべて固定して得られるその条件付き確率分布(超幾何分布になる)における確率を計算する方法になっています。続く
19
#統計 一般に、離散分布モデルにおいて確率を正確に計算することによって構成されたP値は、出て来る確率の値の離散性によって、過剰に大きな値になり易い。
Fisher検定では条件付き確率分布への移行で可能な場合の数が大幅に減り、その問題が悪化することになります。続く
Fisher検定では条件付き確率分布への移行で可能な場合の数が大幅に減り、その問題が悪化することになります。続く
20
#統計 補正無しのχ²検定ではその問題が大幅に緩和されており、帰無仮説下のモデルの確率分布でP値≤αとなる確率はαでうまいこと近似されるようになっています。
ただし、その確率がαを少し超える場合が出て来ることは受け入れる必要がある。続く
ただし、その確率がαを少し超える場合が出て来ることは受け入れる必要がある。続く
21
#統計 現代においてはコンピュータ資源が十分に使えるので、補正無しのχ²検定の利点を捨てて、特に保守的な片側確率の2倍版のFisher検定の良い近似になるYatesの連続性補正を使う意味はないと思います。そうするくらいなら最初から片側確率の2倍版のFisher検定を使えばよい。
22
#統計 Fisher検定達やYates版χ²検定の過剰に保守的な傾向は標本サイズを結構大きくしても残ります。
添付画像は帰無仮説を満たすBin(120,0.25)×Bin(160,0.25)の場合。P値≤αとなる確率のグラフは45度線に近い方がよいのだが、Fisher検定達やYates版χ²検定は45度線より下。
github.com/genkuroki/publ…
添付画像は帰無仮説を満たすBin(120,0.25)×Bin(160,0.25)の場合。P値≤αとなる確率のグラフは45度線に近い方がよいのだが、Fisher検定達やYates版χ²検定は45度線より下。
github.com/genkuroki/publ…

23
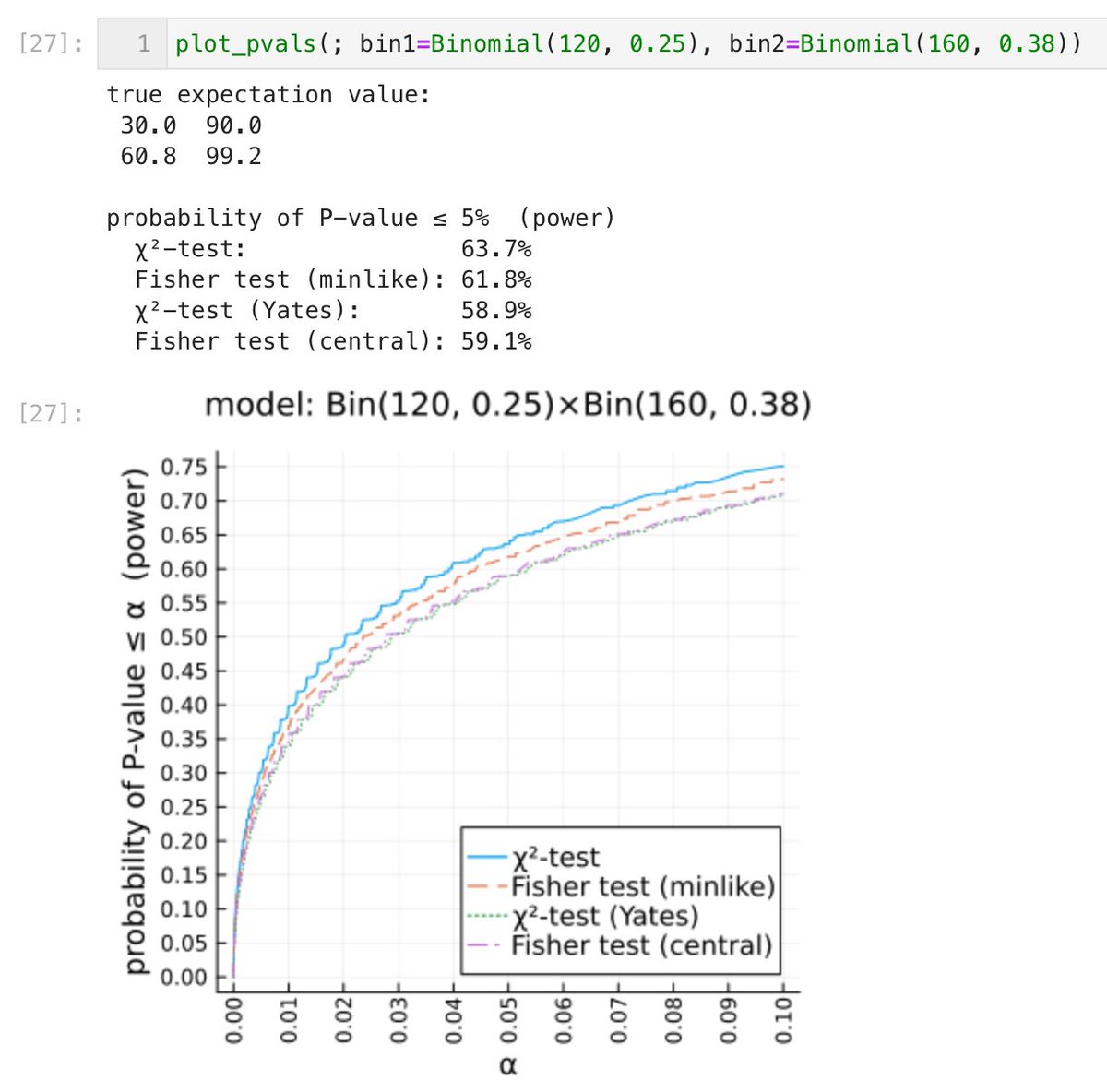
#統計 帰無仮説を満たさないBin(120, 0.25)×Bin(160,0.38)の場合の検出力でも差がグラフで容易に確認できます。
(((まあこの程度の違いなら気にする必要はないとおもいますが)))
github.com/genkuroki/publ…
(((まあこの程度の違いなら気にする必要はないとおもいますが)))
github.com/genkuroki/publ…
24
#統計 帰無仮説を満たすBin(120,0.025)×Bin(160,0.025)の場合。分割表の期待値は
3 117
4 156
でコクランルールならχ²検定の使用が(不当にも)禁止される場合。
やはり、Fisher検定達とYates版χ²検定の過剰な保守性が目立ちます。
github.com/genkuroki/publ…
3 117
4 156
でコクランルールならχ²検定の使用が(不当にも)禁止される場合。
やはり、Fisher検定達とYates版χ²検定の過剰な保守性が目立ちます。
github.com/genkuroki/publ…

25
#統計 帰無仮説を満たさないBin(120,0.025)×Bin(160, 0.090)の場合。Fisher検定達とYates版χ²検定の過剰な保守性による検出力低下が目立つ。
この場合にはYatesの連続補正版のχ²検定の検出力低下が著しい。やはり、Yatesの連続補正版のχ²検定は使わない方がよいだろう。
github.com/genkuroki/publ…
この場合にはYatesの連続補正版のχ²検定の検出力低下が著しい。やはり、Yatesの連続補正版のχ²検定は使わない方がよいだろう。
github.com/genkuroki/publ…

26
#統計 「期待度数が5未満ならばχ²検定を使うな」というルールはよく「コクランルール」と呼ばれており、Cochran (1954)) scholar.google.co.jp/scholar?cluste… がよく引用されています。しかし、その論文でCochran先生自身はそのルールは過剰に保守的過ぎると正しい意見を述べています。
View Tweet

27
#統計 つまり、Cochran (1954)) scholar.google.co.jp/scholar?cluste… を引用しながら、「期待度数が5未満ならばχ²検定を使うな」というルールを「コクランルール」と呼ぶ輩は、コクラン生成自身が「過剰に保守的」と評しているルールにコクラン生成の名前を付けていることになります。
これは酷いと思います。
これは酷いと思います。
View Tweet
28
#統計 関連スレッド
View Tweet
29
#統計 Haviland 1990では片側確率の2倍版のFisher検定を近似するYatesの連続補正版のχ²検定の過剰な保守性を指摘しているのですが、それに対する批判が教科書を読めていないレベルで間違っていたという話については以下のリンク先を参照。
そういうレベルの批判は編集者レベルでブロックして欲しい。
そういうレベルの批判は編集者レベルでブロックして欲しい。
View Tweet
30
#統計 Fisher検定にも欠点があることを
jstage.jst.go.jp/article/dds/30…
連載 第3回
医学データの統計解析の基本 2つの割合の比較
朝倉こう子・濱﨑俊光
も指摘しています。こういう文献で学ぶ人が増えて、伝統的な誤り(所謂「コクランルール」のこと)を訂正して行くようになると良いと思います。
jstage.jst.go.jp/article/dds/30…
連載 第3回
医学データの統計解析の基本 2つの割合の比較
朝倉こう子・濱﨑俊光
も指摘しています。こういう文献で学ぶ人が増えて、伝統的な誤り(所謂「コクランルール」のこと)を訂正して行くようになると良いと思います。
View Tweet
