@genkuroki: #統計 森元良太『統計学再入門』(2024年9月30日)の信...
@genkuroki
26 views
Oct 09, 2024
1
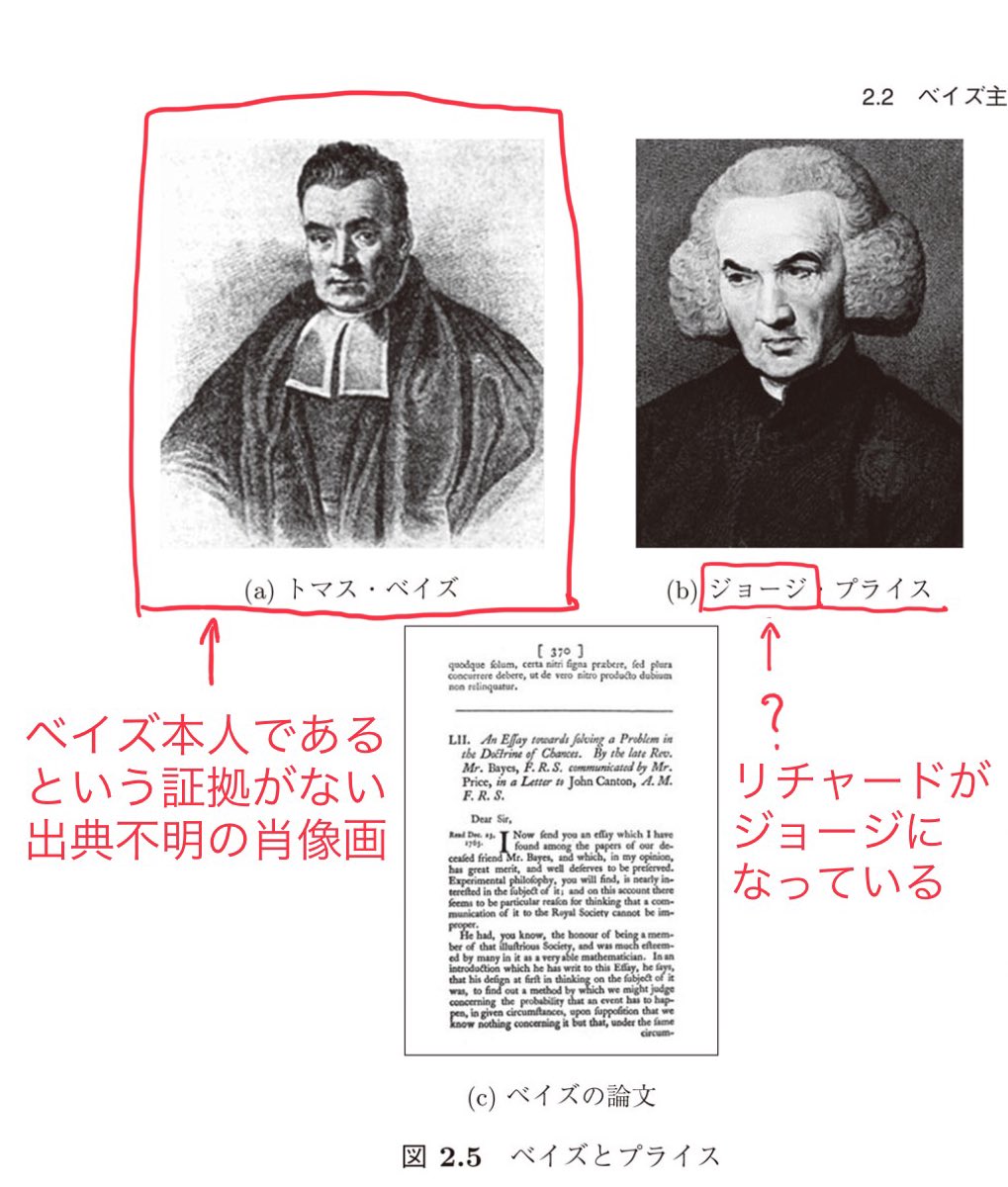
#統計 森元良太『統計学再入門』(2024年9月30日)の信頼度の簡易確認。
添付画像はその本のスクショに私が赤を入れたもの。
ベイズ本人であることの証拠が皆無の怪しげな肖像画が引用されている
だけではなく
リチャード・プライスがジョージ・プライスになっていた!
添付画像はその本のスクショに私が赤を入れたもの。
ベイズ本人であることの証拠が皆無の怪しげな肖像画が引用されている
だけではなく
リチャード・プライスがジョージ・プライスになっていた!
View Tweet
2
#統計 その本の副題は「科学哲学から探る統計思考の原点」。「統計学」の文脈で「哲学」という言葉を見たら要注意。
添付画像はその本のp.90より。
モーメントE((X-μ)ʳ)が(Σ(Xᵢ-μ)ʳ)/nであることになってしまっている。(Σ(Xᵢ-μ)ʳ)/nはXのモーメントそのものではなく、その推定量です。
添付画像はその本のp.90より。
モーメントE((X-μ)ʳ)が(Σ(Xᵢ-μ)ʳ)/nであることになってしまっている。(Σ(Xᵢ-μ)ʳ)/nはXのモーメントそのものではなく、その推定量です。
View Tweet

3
#統計 確率変数が従う分布のパラメータそのものとパラメータの推定量を厳密に区別することは、統計学入門で最初に学ばなければいけない基本中の基本であり、その本の著者がそのレベルをクリアできていない可能性を疑ってしまいました。
4
#統計 数学に弱くても、歴史的な文献を地道に読んでそのまとめを本に書いてくれることはとてもありがたいことなので、数学に弱いことが原因で生じる初歩的な事柄に関する誤解の確認についてはもっと数学が強い人を頼った方が良いと思いました。
5
#統計 森元『統計学再入門』p.92
n個の観測値でのPearsonのχ²統計量
と
自由度nのχ²分布でのP値
で同じ記号nが使われている。
段落間で記号を共有していないなら誤りではないが、こういう説明の仕方はやめた方がよい。
新たに出てきた記号には説明をつけて、直前の記号との関係にも触れるべき。
n個の観測値でのPearsonのχ²統計量
と
自由度nのχ²分布でのP値
で同じ記号nが使われている。
段落間で記号を共有していないなら誤りではないが、こういう説明の仕方はやめた方がよい。
新たに出てきた記号には説明をつけて、直前の記号との関係にも触れるべき。

6
#統計 【標本と母集団の隔たり】の「母集団」の意味が曖昧に見える。正しい意味は「数学的フィクションであるモデル内での仮想的な母集団」です。確率変数としてのK. Pearsonのχ²統計量は数学的フィクション内の確率変数。
「母集団」と言われると現実の母集団をイメージする人が多いので要注意。
「母集団」と言われると現実の母集団をイメージする人が多いので要注意。

7
#統計 χ²検定のP値は
①現実の母集団に関する数学的なモデルを設定する。
②そのモデル内でχ²分布に(近似的に従う)χ²統計量を定義する。
③そのχ²統計量の値が現実の観察で得た標本の値(データの数値)から計算される値よりも大きくなる確率を(近似的に)求める。
という手続きで得られます。続く
①現実の母集団に関する数学的なモデルを設定する。
②そのモデル内でχ²分布に(近似的に従う)χ²統計量を定義する。
③そのχ²統計量の値が現実の観察で得た標本の値(データの数値)から計算される値よりも大きくなる確率を(近似的に)求める。
という手続きで得られます。続く
8
#統計 その確率(P値)は、①で設定したモデル(数学的フィクション)と現実の観察で得たデータの数値の相性の良さ(compatibility)もしくは整合性や適合度の指標として使われます。
どこからどこまでが数学的フィクション(=モデル)の中での話なのかを明瞭に説明しないと、モデルと現実を混同します。
どこからどこまでが数学的フィクション(=モデル)の中での話なのかを明瞭に説明しないと、モデルと現実を混同します。
9
#統計 『統計学再入門』p.127
帰無仮説有意性検定でも、Neyman-Pearson的な複合対立仮説を考えることが普通です。
例えばモデルのパラメータθに関する
帰無仮説「θ=a」の両側検定の対立仮説「θ≠a」
の実体は
{ 仮説「θ=b」| b≠a }
という無数の仮説達の集合(複合仮説)です。
帰無仮説有意性検定でも、Neyman-Pearson的な複合対立仮説を考えることが普通です。
例えばモデルのパラメータθに関する
帰無仮説「θ=a」の両側検定の対立仮説「θ≠a」
の実体は
{ 仮説「θ=b」| b≠a }
という無数の仮説達の集合(複合仮説)です。

10
#統計 母平均μに関する
帰無仮説「μ=15」
の両側検定での対立仮説は
対立仮説「μ≠15」
とよく書かれますが、対立仮説の実体は「μ=11」「μ=19」…のような無数の対立仮説達の集合
{ 仮説「μ=b」| b≠15 }
で、これを略して「μ≠15」と書いています。
帰無仮説「μ=15」
の両側検定での対立仮説は
対立仮説「μ≠15」
とよく書かれますが、対立仮説の実体は「μ=11」「μ=19」…のような無数の対立仮説達の集合
{ 仮説「μ=b」| b≠15 }
で、これを略して「μ≠15」と書いています。
View Tweet
11
#統計 Neyman-Pearsonの基本問題は、検定法Mをうまく取って、対立仮説の集合に含まれる仮説Kの検出力
power_M(K)=仮説Kの下で帰無仮説が棄却される確率
をKについて一様にできるだけ大きくすることです。
無数の単純対立仮説達を同時に考える点が数学的にややこしい。NPの補題一発で解決しない。
power_M(K)=仮説Kの下で帰無仮説が棄却される確率
をKについて一様にできるだけ大きくすることです。
無数の単純対立仮説達を同時に考える点が数学的にややこしい。NPの補題一発で解決しない。
12
#統計 帰無仮説有意性検定の典型例は、帰無仮説「差はゼロである」と対立仮説「差はゼロでない」の検定です。そのとき、
Neyman-Pearsonの理論と違って
その場合の対立仮説は「差はゼロでない」の1つだけである
と考えてしまう人は
対立仮説の概念をまるっきり何も理解していない
ことになります。
Neyman-Pearsonの理論と違って
その場合の対立仮説は「差はゼロでない」の1つだけである
と考えてしまう人は
対立仮説の概念をまるっきり何も理解していない
ことになります。
13
#統計 『統計学再入門』p.157から、Pearson (1955)の翻訳引用部分を孫引き
Pearsonの主張を素直に受け取れば、Neyman-Pearsonの仮説検定が、帰無仮説と対立仮説の片方の採択を強制するかのような解釈は全くのナンセンスで議論する必要がないということになる。しかし、この本では延々と議論している。
Pearsonの主張を素直に受け取れば、Neyman-Pearsonの仮説検定が、帰無仮説と対立仮説の片方の採択を強制するかのような解釈は全くのナンセンスで議論する必要がないということになる。しかし、この本では延々と議論している。
View Tweet

14
#統計 Neyman-Pearsonの仮説検定の結果が帰無仮説と対立仮説の片方の採択を強制するかのような解説がもしも正しいなら、Neyman-Pearsonの仮説検定の考え方は科学的にクズであることは議論しなくても明らかです。
ところが、わざわざ長々と議論したがる人達がいる。続く
ところが、わざわざ長々と議論したがる人達がいる。続く
15
#統計 そして、Neyman-PearsonのPearsonの論文(1955)を見ると、Neyman-Pearsonの仮説検定の結果は最終的な判断を与えるものではなく、ユーザーの意思決定を助ける道具に過ぎないという常識的に見える考え方が書いてあります。
こういう常識的で合理的な考え方を深掘りして行く方が建設的でしょう。
こういう常識的で合理的な考え方を深掘りして行く方が建設的でしょう。
View Tweet
16
#統計 NPの仮説検定のまともな使い方を示唆しているPearson (1955) やそれを引用しているNeymanの高弟のLehmannの論文(1993)には、固定された水準での二分法の結果だけではなく、P値を報告する方が良いと書いてあることなどから、「NP vs. Fisher」の不毛な対立図式を語る必要はもうないと思います。
View Tweet
17
#統計 大体において、「哲学」という用語が出て来る統計学の解説は、ASA声明(2016) scholar.google.co.jp/scholar?cluste… やnature誌(2019)の統計的有意性に反対する記事 scholar.google.co.jp/scholar?cluste… (およびその共著者達の他の論文)で否定されている考え方を取り上げ直して延々と議論しているという印象がある。
18
#統計 nature(2019)の統計的有意性に反対する非常に穏健で常識的な内容の記事の出版を主導したのは、超大物のSander Greenlandさんです。検索すればツイッターでも署名を募っていたことが分かります。すごいパワー!
そのGreenlandさんの考え方については講演スライド(2022)が非常にわかりやすい。
そのGreenlandさんの考え方については講演スライド(2022)が非常にわかりやすい。
View Tweet
19
#統計 nature(2019)の統計的有意性に反対する記事の共著者の一人であるGreenlandさんは自分が関与した論文では「有意」(significant)という用語を決して使わないように気を付けて来たと言っています。
「有意」の語を避けたければGreenlandさんの論文を参考にすれば良いでしょう。
「有意」の語を避けたければGreenlandさんの論文を参考にすれば良いでしょう。
View Tweet
20
#統計 「有意」(significant)という語の使用を避けるべきだと言っているGreenlandさんはP値がどのような意味で有用な道具であるかについても非常に詳しく説明しており、非常に建設的です。
View Tweet
21
22
#統計 基本的に一発の統計分析には再現性を確率的に保証するだけの力はないという当たり前の話を当然の前提にした上で「再現性の危機」について考える必要があることも多くの場合に見逃されています。
Amrhein-Trafimow-Greenland 2019が非常に良いです。
Amrhein-Trafimow-Greenland 2019が非常に良いです。
View Tweet
23
#統計 「3つの問い」で有名なRoyall氏の著作についてもGreenlandさんが正しいと思います。
常識的に否定されて当然の考え方をビッグネームを持ち出して引っ張り出して議論したりせずに、Greenlandさん達のように科学的な常識に沿った議論を行うべきだと思います。
常識的に否定されて当然の考え方をビッグネームを持ち出して引っ張り出して議論したりせずに、Greenlandさん達のように科学的な常識に沿った議論を行うべきだと思います。
View Tweet
24
#統計 Greenland-Hofman 2019 link.springer.com/article/10.100… より(MC=多重比較)
【頻度主義とベイズの区別は技術的な違いであり、哲学的な違いではない】
【「統計の哲学」は健全な方法の探求というよりも神学に似ている】
【頻度主義とベイズの区別は技術的な違いであり、哲学的な違いではない】
【「統計の哲学」は健全な方法の探求というよりも神学に似ている】
View Tweet

25
#統計 21世紀における統計学の健全な使い方に関する議論を眺めると、鉤括弧付きの「統計学の哲学」的な言説の悪影響を払拭しなければいけないという問題があることが分かります。
真の「統計学再入門」にはそういう視点も必要だと思います。
真の「統計学再入門」にはそういう視点も必要だと思います。
26
#統計 補足
P値が有用な道具であること
と
「統計的有意」と言うことが有害であること
はシンプルに整合的な主張になることにも注意が必要なのですが大丈夫か?
P値が帰無仮説有意性検定のための道具だと信じている人はP値に関する理解度が低すぎる。
P値が有用な道具であること
と
「統計的有意」と言うことが有害であること
はシンプルに整合的な主張になることにも注意が必要なのですが大丈夫か?
P値が帰無仮説有意性検定のための道具だと信じている人はP値に関する理解度が低すぎる。
27
#統計 P値はモデルとデータの数値の相性の良さ(compatibility)を測る指標の1つなので、P値を使う話題で使用するモデルの話(多くの場合にモデルの妥当性は保証されない)もしないと何も説明したことにならない。
そして、検定する仮説はモデルのパラメータの値の設定に関する仮説になります。
そして、検定する仮説はモデルのパラメータの値の設定に関する仮説になります。
28
#統計 閾値のαを設けて、仮説θ=aの(両側)P値がα未満かどうかを見ることは、特定のモデルの下で、仮説θ=aはデータの数値と(閾値αで)相性が悪いとみなされるかどうかを見ていることになります。
相性の良し悪しについての二分法に過ぎないので、仮説自体は肯定も否定もされない。
相性の良し悪しについての二分法に過ぎないので、仮説自体は肯定も否定もされない。
29
#統計 続き。しかし、使用した特定のモデルが他での経験から十分に役に立つものだと分かっているなら、そのモデルの下で、仮説θ=aの各々とデータの数値の間の相性の良さの様子の定量化のまとめの報告はさらなる研究の発展に貢献する可能性が高くなります。
これがP値の無難な使い方です。
これがP値の無難な使い方です。
30
#統計
統計学を科学的お墨付きが得られる道具であるかのように扱うことはやめるべき。
P値がどういう道具であるかについて語るときにも、確率的なお墨付きが得られる道具であるかのように誤解させないように注意するべき。
統計学を科学的お墨付きが得られる道具であるかのように扱うことはやめるべき。
P値がどういう道具であるかについて語るときにも、確率的なお墨付きが得られる道具であるかのように誤解させないように注意するべき。