@genkuroki: #統計 誤植発見。不変→不偏言葉の使い方として、モデルの...
@genkuroki
24 views
Mar 03, 2025
1
#統計 誤植発見。不変→不偏
言葉の使い方として、モデルのパラメータをモデルと呼ばずに、素直にパラメータと呼んだ方が分かり易かったかも。
あと、推定用のモデルと現実を混同しているので、これを聴いたユーザーは、推定用のモデルが妥当でないとき、酷い目に遭うリスクがあると思いました。続く
言葉の使い方として、モデルのパラメータをモデルと呼ばずに、素直にパラメータと呼んだ方が分かり易かったかも。
あと、推定用のモデルと現実を混同しているので、これを聴いたユーザーは、推定用のモデルが妥当でないとき、酷い目に遭うリスクがあると思いました。続く
View Tweet

2
#統計 線形回帰は、データから、モデルのパラメータβ,σを最尤法で決めることだと解釈できます。モデルは式で書くと、
p(y|X,β,σ) = (1/(2πσ²)ⁿᐟ²) exp(-||y - Xβ||²/(2σ²))
ここでy∈ℝⁿでXは計画行列。
続く
p(y|X,β,σ) = (1/(2πσ²)ⁿᐟ²) exp(-||y - Xβ||²/(2σ²))
ここでy∈ℝⁿでXは計画行列。
続く
3
#統計 パラメータ値がβ₀,σ₀(多くの場合に₀は略すがここではあえて書く)のモデルの確率分布にしたがってランダムにデータが生成されているという仮定の下で、どうなるかをよく考えます。
これを、現実におけるデータの取得の話であるかのように説明するのは自明に誤りです。続く
これを、現実におけるデータの取得の話であるかのように説明するのは自明に誤りです。続く
4
#統計 なぜならば、パラメータ値がβ₀,σ₀のモデルと現実のデータの生成のされ方は当たり前に別物だからです。
そこは厳密に区別しないとまずい。
モデルと現実の混同は典型的に非科学的な考え方であり、「あらゆるモデルは正しくない」という統計分析における最重要の原則を忘れさせてしまいます。
そこは厳密に区別しないとまずい。
モデルと現実の混同は典型的に非科学的な考え方であり、「あらゆるモデルは正しくない」という統計分析における最重要の原則を忘れさせてしまいます。
5
#統計 現実でのデータ取得はコストがかかるので、無数にデータ取得を繰り返すことはできません。
だから、信頼区間の説明のために、現実においてデータ取得を繰り返すように聞こえる話をする人達は極めて二重の意味で奇妙な考え方をしているように見える。
だから、信頼区間の説明のために、現実においてデータ取得を繰り返すように聞こえる話をする人達は極めて二重の意味で奇妙な考え方をしているように見える。
6
#統計 二重にダメな点
(1) 現実においてデータを100回取り直すという設定が恐ろしく非現実的に響くことをなぜか気にしない。常識に欠けている?
(2) 信頼区間の説明では、モデル内での確率分布で測った確率を考えればば十分なので、データを何度も取り直さずに、和を取ったり積分するだけでよい。
(1) 現実においてデータを100回取り直すという設定が恐ろしく非現実的に響くことをなぜか気にしない。常識に欠けている?
(2) 信頼区間の説明では、モデル内での確率分布で測った確率を考えればば十分なので、データを何度も取り直さずに、和を取ったり積分するだけでよい。
7
#統計 この二重におかしな信頼区間の解説がひどく普及してしまっているせいで、それを騙る人達は自分がどれだけおかしなことを言っているのか全然認識できなくなっている場合が多いようだ。
教科書にもおかしな説明の方が書いてあることが普通。
どうして誰もこの件を指摘しないのか?
教科書にもおかしな説明の方が書いてあることが普通。
どうして誰もこの件を指摘しないのか?
8
#統計 『数理統計学』と題された有名な教科書達を読めば、信頼度1-αの信頼区間(信頼領域)の定義は
データの数値によって有意水準αで棄却されないよう
モデルのパラメータ値全体の集合
になります。
線形回帰での信頼区間でも同様です。
データの数値によって有意水準αで棄却されないよう
モデルのパラメータ値全体の集合
になります。
線形回帰での信頼区間でも同様です。
9
#統計 パラメータ値がθ=θ₀であるという仮説が、有意水準αで棄却されることはP値がα未満になることを意味し、P値はデータの数値と仮説θ=θ₀の下での統計モデルの整合性の指標です。(P値に関するASA声明を参照)
10
#統計 回帰直線の信頼区間の場合には、x=x_*でのモデル内回帰直線上の値(モデルのパラメータとみなされる)がy̅_*であるというモデルのパラメータ値に関する仮説がデータの数値によって棄却されないようなy̅_*の範囲になります。
モデル内回帰直線上の値の範囲なので、残差による揺らぎは考慮外。
モデル内回帰直線上の値の範囲なので、残差による揺らぎは考慮外。
11
#統計 重要なポイントは、信頼区間は現実における何かの値の範囲ではないことです。
数学的フィクションである統計モデルのパラメータ値の範囲でしかない。
だから、使用した統計モデルの現実での使用が妥当であるという証拠がない場合には、その信頼区間は現実では信頼できない区間になります。
数学的フィクションである統計モデルのパラメータ値の範囲でしかない。
だから、使用した統計モデルの現実での使用が妥当であるという証拠がない場合には、その信頼区間は現実では信頼できない区間になります。
12
#統計 専門用語を日常的な意味で解釈するというよく見る初歩的な誤りは普遍的です。
例えば「信頼区間」を「信頼できる区間」の意味だと思いたくなってしまう初歩的な誤解は普遍的だと思われます。
だからこそ、そのような安易な解釈は誤解だと言い続ける必要があると思います。
例えば「信頼区間」を「信頼できる区間」の意味だと思いたくなってしまう初歩的な誤解は普遍的だと思われます。
だからこそ、そのような安易な解釈は誤解だと言い続ける必要があると思います。
13
#統計 信頼区間は数学的フィクションであるモデルのパラメータの範囲(データの数値で棄却されなかった値の範囲)なので、モデルの設定を変えれば、同じデータの数値が与える信頼区間が大きく変わってしまうこともあるわけです。
14
#統計 こういうことを知っているのに、信頼区間が現実の何かの値の区間であるかのように説明する人達を放置しておくと、専門家は誤解していないが、理系高学歴者も含む多くの一般市民は誤解したままになるという、社会的に非常によろしくない状況が維持され続けることになると思いました。
15
#統計
添付画像は youtu.be/VZ-84t2U1oQ にあった図にコメントを書き込んだもの。
コメントのように「検定で棄却されないモデルの回帰直線全体が含まれる範囲」が信頼区間だと説明すれば、データを無数に取り直す様子を想定する方向(極めて不適切)に進みようがなくなるので、よいと思いました。
添付画像は youtu.be/VZ-84t2U1oQ にあった図にコメントを書き込んだもの。
コメントのように「検定で棄却されないモデルの回帰直線全体が含まれる範囲」が信頼区間だと説明すれば、データを無数に取り直す様子を想定する方向(極めて不適切)に進みようがなくなるので、よいと思いました。

16
#統計 「95%信頼区間に真の値が含まれる確率」という発想をする方にいきなり進むと色々穴ぼこにハマりやすいと思います。
「データを何度も取り直して信頼区間を計算し直す」という奇妙でミスリーディングな説明も、「95%信頼区間に真の値が含まれる確率」という発想との関連で不幸にも生まれた。
「データを何度も取り直して信頼区間を計算し直す」という奇妙でミスリーディングな説明も、「95%信頼区間に真の値が含まれる確率」という発想との関連で不幸にも生まれた。
17
#統計 95%信頼区間の95%が有意水準5%を100%から引いた値になっている理由がわかる説明の仕方の方が適切かつ奇妙な考え方にトラップされずにすむ道だと思う。
18
#統計 有意水準αでは第一種の過誤が起こる確率で、信頼度1-αの信頼区間の信頼度は第一種の過誤が起こらない確率になっています。
95%信頼区間の95%は有意水準5%で第一種の過誤が起こらない確率という意味での確率になっている。
95%信頼区間の95%は有意水準5%で第一種の過誤が起こらない確率という意味での確率になっている。
19
#統計 仮説θ=θ₀に関する第一種の過誤が起こる確率の定義は、
パラメータ値がθ=θ₀の統計モデル内の確率分布で
データを生成したとき
そのデータによって仮説θ=θ₀が棄却される確率
です。数学的フィクションである統計モデル内での確率になります。
パラメータ値がθ=θ₀の統計モデル内の確率分布で
データを生成したとき
そのデータによって仮説θ=θ₀が棄却される確率
です。数学的フィクションである統計モデル内での確率になります。
20
#統計 与えられたデータから決まるパラメータθに関する信頼区間の定義は、
データの数値によって仮説θ=θ₀棄却されないような
パラメータ値θ₀全体の集合
です。信頼区間の計算は、概念的には、無数のパラメータ値θ₀について仮説θ=θ₀の検定を実行することと同じ。
データの数値によって仮説θ=θ₀棄却されないような
パラメータ値θ₀全体の集合
です。信頼区間の計算は、概念的には、無数のパラメータ値θ₀について仮説θ=θ₀の検定を実行することと同じ。
21
#統計 P値の使い方について広まっているダメな考え方(特に主義に基くダメなベイズ統計推しの困った人がしている考え方)は、
帰無仮説「治療の効果無し」vs.対立仮説「治療効果有り」
のような仮説検定しか考えないことです。
NHSTという四文字を使う人たちのP値批判でよく見る。
帰無仮説「治療の効果無し」vs.対立仮説「治療効果有り」
のような仮説検定しか考えないことです。
NHSTという四文字を使う人たちのP値批判でよく見る。
22
#統計 しかし、教科書には
帰無仮説「治療効果=θ₀」vs.対立仮説「治療効果≠θ₀」
の型の検定を値θ₀をオールオーバー動かす話が普通に書いてあります。検定される仮説は固定されていない。
そしてその方法を使って信頼区間も得られることが説明されています。
帰無仮説「治療効果=θ₀」vs.対立仮説「治療効果≠θ₀」
の型の検定を値θ₀をオールオーバー動かす話が普通に書いてあります。検定される仮説は固定されていない。
そしてその方法を使って信頼区間も得られることが説明されています。
23
#統計 そういう方向での最先端はおそらくRothmanさん達の疫学の教科書で、
帰無仮説「効果=θ₀」vs.対立仮説「効果≠θ₀」
の型の検定のP値を値θ₀をオールオーバーに動かしてプロットして利用することを提案しています。
P値函数のグラフを描くためには、有意水準の設定は必要ない。
帰無仮説「効果=θ₀」vs.対立仮説「効果≠θ₀」
の型の検定のP値を値θ₀をオールオーバーに動かしてプロットして利用することを提案しています。
P値函数のグラフを描くためには、有意水準の設定は必要ない。
24
#統計 ツイッター上でもRothmanさんは持ちネタを炸裂させていて面白いです。検索して見つけてフォローしておくといいかも。
その持ちネタとは、有意水準という人為的な閾値の設定に心を支配されてしまって、間違った判断をしてしまうことへの批判。
その持ちネタとは、有意水準という人為的な閾値の設定に心を支配されてしまって、間違った判断をしてしまうことへの批判。
25
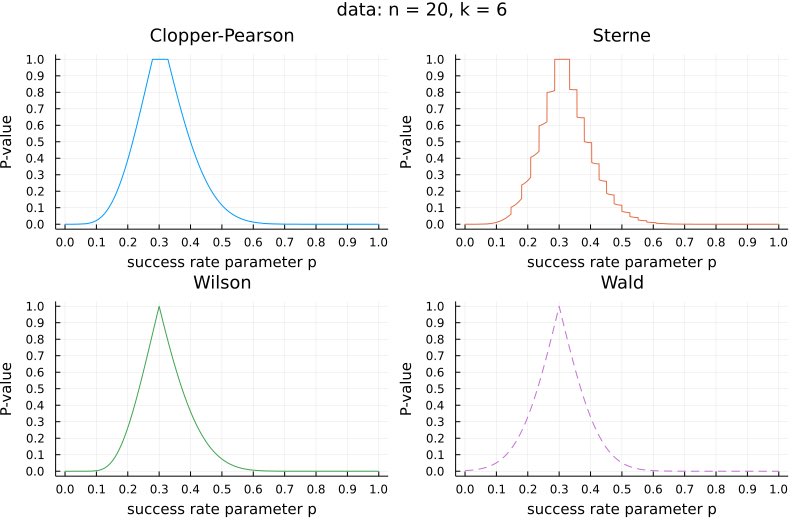
#統計 二項分布モデルのP値函数の例
「n=20回中k=6回成功」というデータが得られたときの、二項分布モデルの成功確率パラメータのP値達のグラフ。適当に見繕って4種類の信頼区間を与えるP値を別々にプロットしました。
nが増えるとP値函数のグラフの幅は狭くなります(次のツイートの例を参照)。
「n=20回中k=6回成功」というデータが得られたときの、二項分布モデルの成功確率パラメータのP値達のグラフ。適当に見繕って4種類の信頼区間を与えるP値を別々にプロットしました。
nが増えるとP値函数のグラフの幅は狭くなります(次のツイートの例を参照)。
26
#統計
「n=100回中k=30回成功」というデータが得られたときの、二項分布モデルの成功確率パラメータのP値達のグラフ。
n=20, k=6の場合よりも、P値函数のグラフの幅が狭くなっている。
P値函数は信頼度を固定して得られる信頼区間よりもずっと豊富な情報を持っている。
「n=100回中k=30回成功」というデータが得られたときの、二項分布モデルの成功確率パラメータのP値達のグラフ。
n=20, k=6の場合よりも、P値函数のグラフの幅が狭くなっている。
P値函数は信頼度を固定して得られる信頼区間よりもずっと豊富な情報を持っている。

27
#統計 P値函数と95%信頼区間の関係
P値函数経由での信頼区間の視覚的把握は極めて易しい。
これを理解した人が信頼区間について誤解することは難しいように思われる。
信頼区間の上には「とんがり帽子」がのっかっています(笑)
Rothmanさん達の教科書経由で普及すると良いと思う。
P値函数経由での信頼区間の視覚的把握は極めて易しい。
これを理解した人が信頼区間について誤解することは難しいように思われる。
信頼区間の上には「とんがり帽子」がのっかっています(笑)
Rothmanさん達の教科書経由で普及すると良いと思う。
28
#統計 線形回帰における(回帰直線上の値の)信頼区間は各xごとに決まっており、各xごとの(回帰直線上の値の)信頼区間の上に「とんがり帽子」が乗っかっている(笑)
とんがり帽子自体には信頼度の指定は必要ない。
誰かこれを視覚化すると面白いかも。
とんがり帽子自体には信頼度の指定は必要ない。
誰かこれを視覚化すると面白いかも。
29
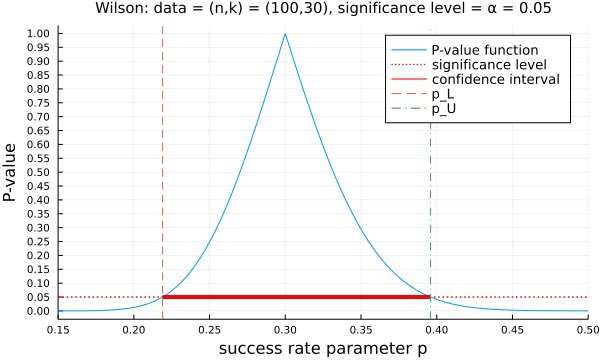
#統計
この図は、データ「n=100回中k=30回成功」から得られる仮説p=p₀達のP値達をプロットしたもので、その高さ=有意水準での切断が信頼区間になっていることを示しています。
この図から、逆にすべての有意水準での信頼区間が与えられれば、そこから逆にP値函数を作れることも分かります。続く
この図は、データ「n=100回中k=30回成功」から得られる仮説p=p₀達のP値達をプロットしたもので、その高さ=有意水準での切断が信頼区間になっていることを示しています。
この図から、逆にすべての有意水準での信頼区間が与えられれば、そこから逆にP値函数を作れることも分かります。続く

30
#統計 続き。P値函数のグラフで信頼区間について理解すると、
任意のP値函数 ↔ 任意の区間推定法
という一対一の対応が自明にあることを理解できる。
どんな方法であっても、区間推定法を1つ決めてそれを使うことは、P値函数を使っていることにも自動的になってしまうのです。続く
任意のP値函数 ↔ 任意の区間推定法
という一対一の対応が自明にあることを理解できる。
どんな方法であっても、区間推定法を1つ決めてそれを使うことは、P値函数を使っていることにも自動的になってしまうのです。続く