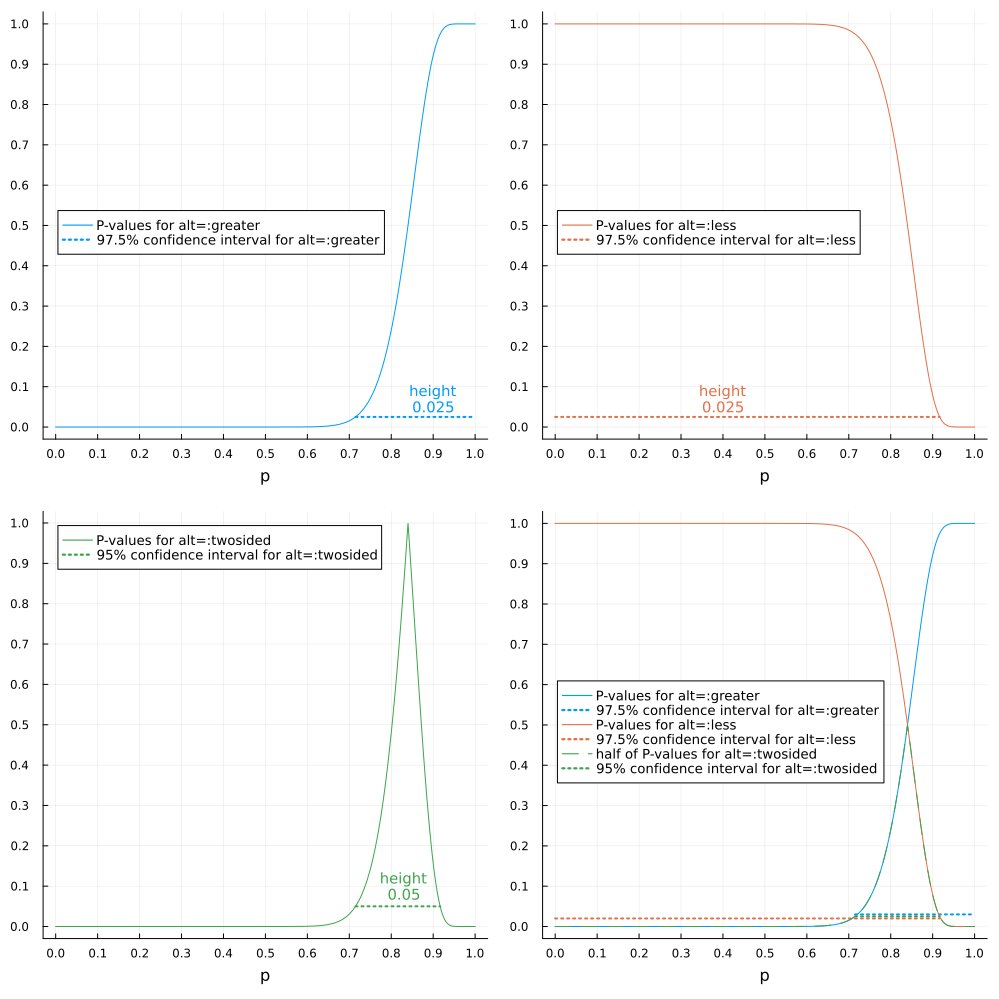
統計学の講義でP値関数について解説する仲間が増えた。
その場合を #Julia言語 で視覚化してみました。信頼区間はP値がα以上になるモデルのパラメータの範囲になる。
誰でも実行して遊べるColabノートブック
↓
colab.research.google.com/drive/1she_BKS…
View Tweet

View Tweet


View Tweet

View Tweet
View Tweet
View Tweet

View Tweet

View Tweet

View Tweet

View Tweet

View Tweet
View Tweet
Image exported!
Pro export renders embedded tweets & media at 2x Retina resolution.
Upgrade — $5 for 30 days