Thread Truncated (Cap Enforced)
Only the first 20 tweets are unrolled into slides to ensure reliable PDF exporting and high server performance.
Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

One of the hottest foundational topics. Learn the core idea, its types, scaling laws, real-world cases and useful resources to dive deeper

In the previous episode, we discussed<a target="_blank" href="https://www.turingpost.com/p/insidesmol" color="blue"> “Smol” family of models</a> and their effective strategy for training small LMs through high-quality dataset mixing. Today we want to go further in exploring training techniques for smaller models, making it the perfect time to discuss <b>knowledge distillation (KD)</b>. Proposed a decade ago, this method has continued to evolve. For example, DeepSeek’s advancements, particularly the effective distillation of DeepSeek-R1, have recently brought a wave of attention to this approach.
So, what is the key idea behind KD? It enables to transfer knowledge from larger model, called teacher, to smaller one, called student. This process allows smaller models to inherit the strong capabilities of larger ones, avoiding the need for training from scratch and making powerful models more accessible. Let’s explore how knowledge distillation has evolved over time, the different types of distillation that exist today, the key factors to consider for effective model distillation, and useful resources to master it.
## When did knowledge distillation appear as a technique?
The ideas behind knowledge distillation (KD) date back to 2006, when <b>Bucilă, Caruana, and Niculescu-Mizil</b> in their work <b><i>“Model Compression”</i></b><i></i> showed that an ensemble of models could be compressed into a single smaller model without much loss in accuracy. They demonstrated that a cumbersome model (like an ensemble) could be effectively replaced by a lean model that was easier to deploy.
Later <b>in 2015</b>, <b>Geoffrey Hinton, Oriol Vinyals, and Jeff Dean</b> <b>coined the term “distillation”</b> in their <b><i>“Distilling the Knowledge in a Neural Network”</i></b><i></i> paper. This term was referred to the process of transferring knowledge from a large, complex AI model or ensemble to a smaller, faster AI model, called the distilled model. Instead of just training the smaller model on correct answers, researchers proposed to give it the probability distribution from the large model. This helps the smaller model learn not just what the right answer is, but also how confident the big model is about each option. This training concept is closely connected to the softmax function, so let's explore more precisely how this all works at the core.

## A detailed explanation of knowledge distillation
Firstly, we need to clarify what is <b>softmax</b>.
It is a mathematical function used in machine learning, especially in neural networks, to <b>convert raw scores, called logits, into probabilities</b>. It helps a model decide which category, or class, an input belongs to by ensuring that the output values sum to 1, making them interpretable as probabilities.
The important parameter in softmax is a <b>temperature (T)</b> — it is a way to control how confident or uncertain a model’s predictions are. It adjusts the sharpness of the probability distribution – making it either more confident (sharp) or more uncertain (soft). If T = 1, it is the default setting referring to the normal softmax behavior, where only the correct answer receives 100% probability. In this case, softmax creates <b>hard targets</b>. When the temperature is increased (T > 1), softmax creates <b>soft targets</b>, meaning the probabilities are more spread out or softer.
<b>Soft targets are useful for distillation and training, and the distillation process below shows why.</b> It typically involves several steps:
1. First, the teacher model is trained on the original task and dataset.
1. Next, the teacher model produces logits. These logits are converted into soft targets using a softmax function with a higher temperature to make the probability distribution softer.
1. The student model is then trained on these soft targets often alongside the hard targets (true labels) by minimizing the difference between the student’s output distribution and the teacher’s output distribution.
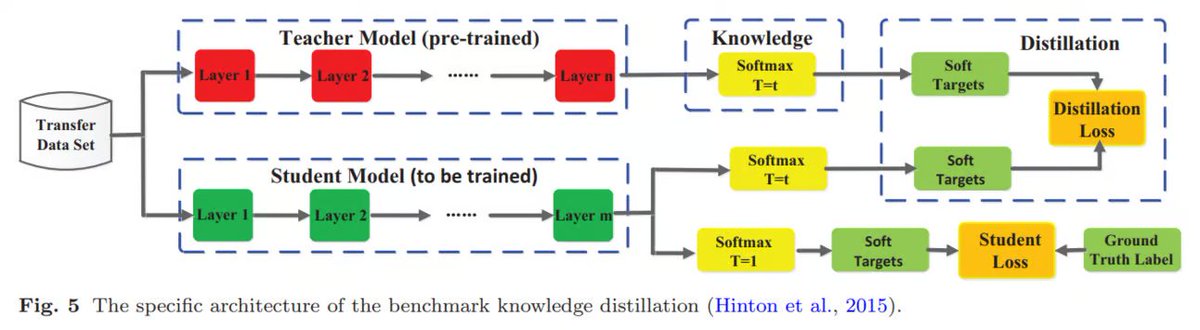
During this process the student learns to reproduce not just the correct answers, but also the teacher’s relative confidence in those answers and its mistakes. This knowledge about how the teacher distributes probability mass among the incorrect categories provides rich information that helps the student generalize better. By combining a standard training loss on true labels with a distillation loss on the teacher’s soft labels, the student can achieve accuracy close to the teacher model’s accuracy, despite having far fewer parameters.
If we were to summarize the key idea in one sentence, it would be this: <b>The student is optimized to mimic the teacher’s behavior, not just outputs.</b>
There is another approach to distillation proposed in the <i>“Distilling the Knowledge in a Neural Network”</i> paper, and it is <b>matching logits</b>. Instead of just copying probabilities, this method directly makes the small model's logits resemble the large model’s logits. In high-temperature settings, this method becomes mathematically equivalent to standard distillation, and both approaches lead to similar benefits.
## Types of knowledge distillation