Everything You Need to Know about Knowledge Distillation
One of the hottest foundational topics. Learn the core idea, its types, scaling laws, real-world cases and useful resources to dive deeper

In the previous episode, we discussed “Smol” family of models and their effective strategy for training small LMs through high-quality dataset mixing. Today we want to go further in exploring training techniques for smaller models, making it the perfect time to discuss knowledge distillation (KD). Proposed a decade ago, this method has continued to evolve. For example, DeepSeek’s advancements, particularly the effective distillation of DeepSeek-R1, have recently brought a wave of attention to this approach.
So, what is the key idea behind KD? It enables to transfer knowledge from larger model, called teacher, to smaller one, called student. This process allows smaller models to inherit the strong capabilities of larger ones, avoiding the need for training from scratch and making powerful models more accessible. Let’s explore how knowledge distillation has evolved over time, the different types of distillation that exist today, the key factors to consider for effective model distillation, and useful resources to master it.
When did knowledge distillation appear as a technique?
The ideas behind knowledge distillation (KD) date back to 2006, when Bucilă, Caruana, and Niculescu-Mizil in their work “Model Compression” showed that an ensemble of models could be compressed into a single smaller model without much loss in accuracy. They demonstrated that a cumbersome model (like an ensemble) could be effectively replaced by a lean model that was easier to deploy.
Later in 2015, Geoffrey Hinton, Oriol Vinyals, and Jeff Deancoined the term “distillation” in their “Distilling the Knowledge in a Neural Network” paper. This term was referred to the process of transferring knowledge from a large, complex AI model or ensemble to a smaller, faster AI model, called the distilled model. Instead of just training the smaller model on correct answers, researchers proposed to give it the probability distribution from the large model. This helps the smaller model learn not just what the right answer is, but also how confident the big model is about each option. This training concept is closely connected to the softmax function, so let's explore more precisely how this all works at the core.

A detailed explanation of knowledge distillation
Firstly, we need to clarify what is softmax.
It is a mathematical function used in machine learning, especially in neural networks, to convert raw scores, called logits, into probabilities. It helps a model decide which category, or class, an input belongs to by ensuring that the output values sum to 1, making them interpretable as probabilities.
The important parameter in softmax is a temperature (T) — it is a way to control how confident or uncertain a model’s predictions are. It adjusts the sharpness of the probability distribution – making it either more confident (sharp) or more uncertain (soft). If T = 1, it is the default setting referring to the normal softmax behavior, where only the correct answer receives 100% probability. In this case, softmax creates hard targets. When the temperature is increased (T > 1), softmax creates soft targets, meaning the probabilities are more spread out or softer.
Soft targets are useful for distillation and training, and the distillation process below shows why. It typically involves several steps:
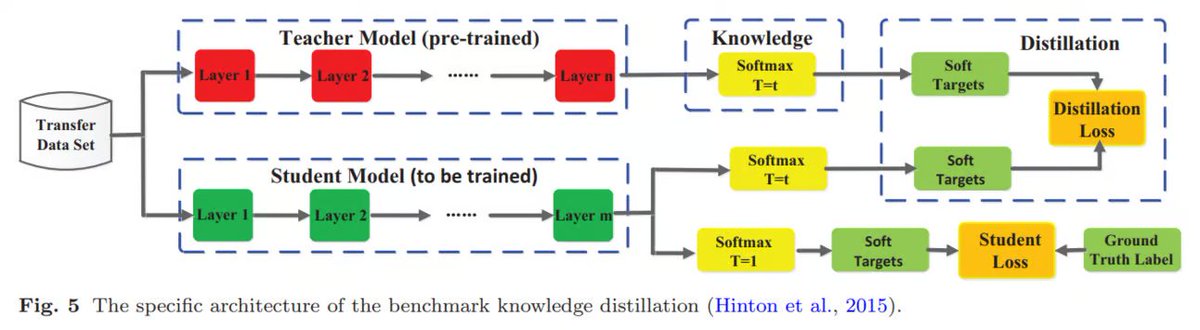
During this process the student learns to reproduce not just the correct answers, but also the teacher’s relative confidence in those answers and its mistakes. This knowledge about how the teacher distributes probability mass among the incorrect categories provides rich information that helps the student generalize better. By combining a standard training loss on true labels with a distillation loss on the teacher’s soft labels, the student can achieve accuracy close to the teacher model’s accuracy, despite having far fewer parameters.
If we were to summarize the key idea in one sentence, it would be this: The student is optimized to mimic the teacher’s behavior, not just outputs.
There is another approach to distillation proposed in the “Distilling the Knowledge in a Neural Network” paper, and it is matching logits. Instead of just copying probabilities, this method directly makes the small model's logits resemble the large model’s logits. In high-temperature settings, this method becomes mathematically equivalent to standard distillation, and both approaches lead to similar benefits.
Types of knowledge distillation
What we have explored are just two options for the technique, but KD can be applied in various ways depending on whatknowledge is transferred from teacher to student. These types of distillation were perfectly illustrated in the paper “Knowledge Distillation: A Survey”by researchers from the University of Sydney and the University of London. So common techniques include:
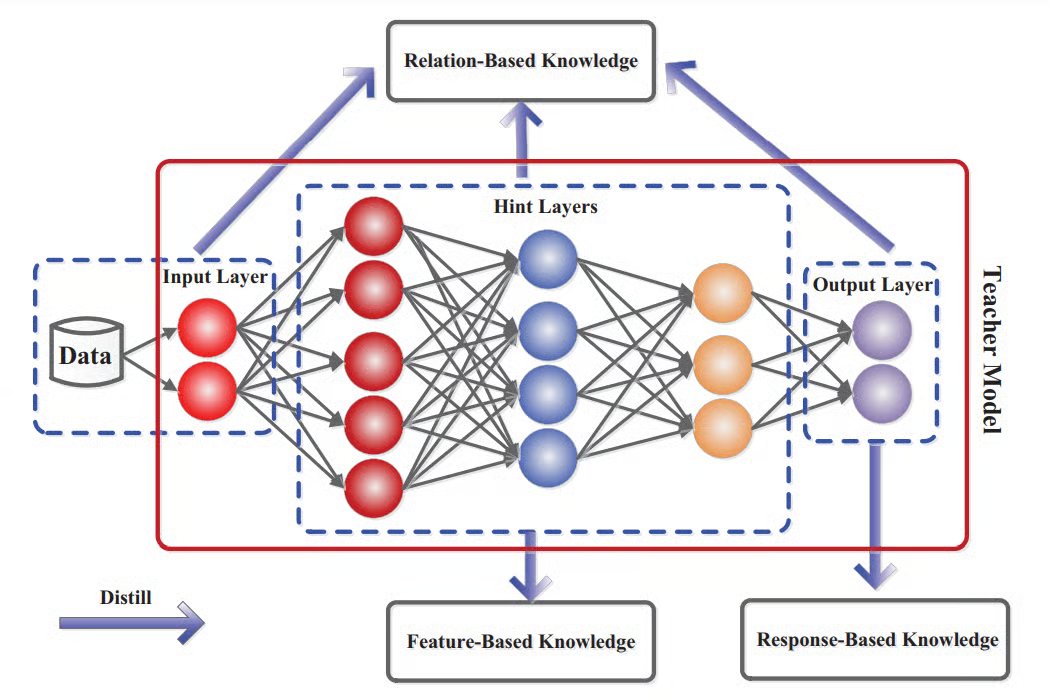

3. Relation-based distillation (relationships as knowledge): The student model learns to mimic relationships between different parts of the teacher model – either between layers or between different data samples. For example, the students compares multiple samples and learns their similarities. This method is more complex but can work with multiple teacher models, merging their knowledge.
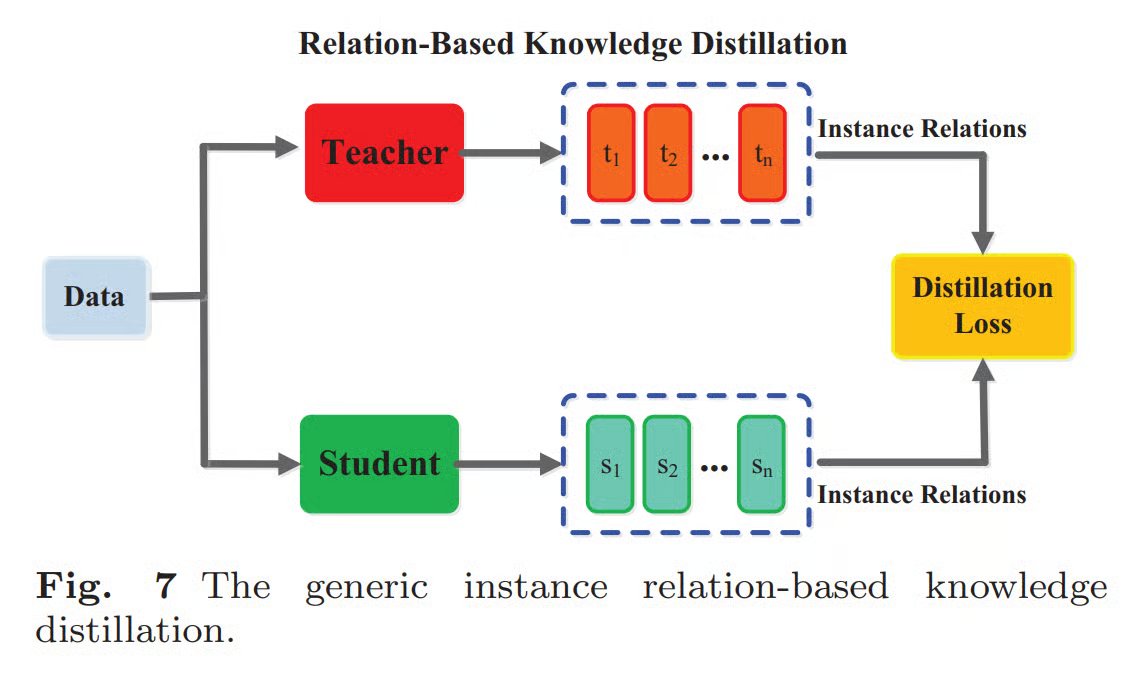
It is a classification of the three concepts used for knowledge distillation based on what to distill. But how exactly can we transfer the knowledge during training? There are three main ways:
Here is what you need to know about these training schemes:
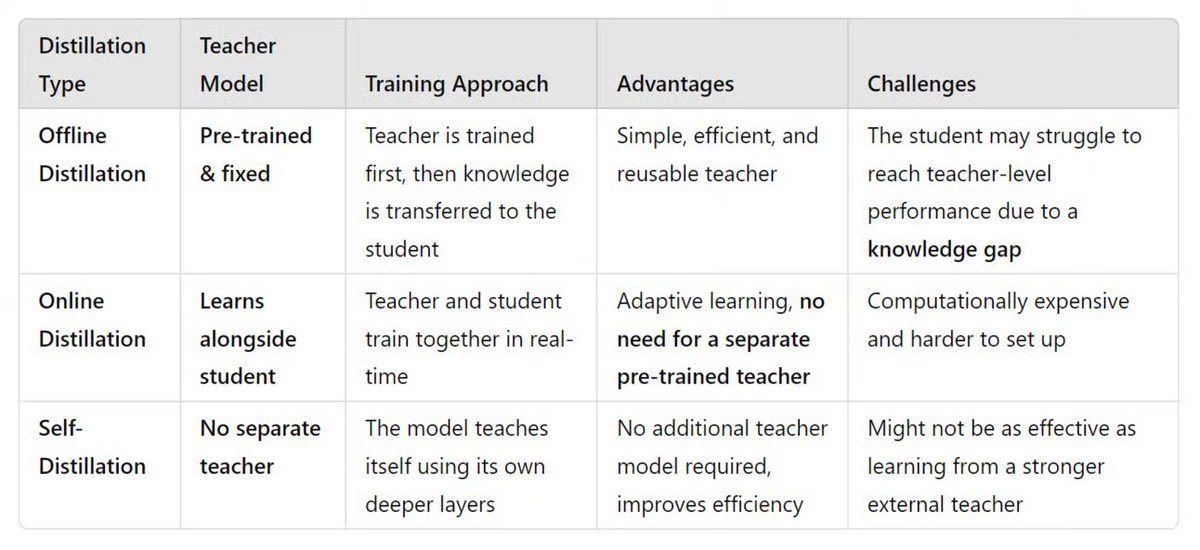
But that’s not all. Since the emergence of the knowledge distillation concept, many different approaches have been developed to improve knowledge transfer.
Improved algorithms...
Read the full article here → https://www.turingpost.com/p/kd to learn about most interesting advanced algorithms, scaling laws, and benefits vs. limitations of knowledge distillation.
We're doing in-depth explanations of concepts and methods every week. Follow to be the first to see the latest AI breakthroughs and learn basics that matter most: https://www.turingpost.com/upgrade