@meta_alchemist: <b>Skills make AI consistent. ...
Skills make AI consistent.
Spark makes AI competent and a master of specializations, through a mix of recursive self-improvement and collective evolution.
Here's the system that gives agents self-improving mechanisms and collective evolution through real/benchmarked expertise, not just instructions:
Today's AI gives you a confident speaker. It gives you someone who sounds like they know what they're doing. That may be true or not, and it's hard to tell the difference between the two. AI hallucinates a lot and doesn't always choose the best knowledge or patterns.
They have no mechanism to track what worked, study what failed, or build on accumulated evidence, unless you build specialized tools for this.
That's the gap Spark fills.
Spark is an open-source AI designed to run self-improving flywheels across any category/specialization. This will also come with a collective specialization mastery platform focused on sharing intelligence learned/tested/benchmarked, so agents can grow and evolve together.
It gives AI agents the ability to run structured research, build validated knowledge, share proven insights across a governed network, and improve measurably with every cycle.
This isn't an incremental upgrade to prompting. It's a new category.
And once you see how it works, the current approach of Skills and custom instructions starts to look a bit primitive.
Let's walk through the full system.
What people have today (and why it's not enough)
Right now, if you want AI to be good at a specific domain, you have three options.
Option 1: Base LLM training. This is what you get out of the box with ChatGPT, Claude, or any other model. The model was trained on a massive dataset and knows a little about everything.
It's a generalist.
It has no specialized depth in your domain and no way to develop it. Ask it about your specific industry and it'll give you generic advice that sounds smart but misses the nuances that matter.
Option 2: Fine-tuning. You take a base model and retrain it on your specific data. This adds domain knowledge, but it's a one-way door.
The knowledge gets baked into the model weights permanently.
You can't inspect what it learned.
You can't see which specific lessons are driving its outputs.
You can't selectively undo one bad lesson that got mixed into the training data. If something goes wrong, you retrain from scratch.
The entire process is opaque.
Option 3: Skills and custom instructions. You write a set of rules that tell the AI how to behave.
"When evaluating startups, focus on retention metrics." "Always ask about burn rate."
These make the AI more consistent, which is genuinely useful. But they're static. A skill written in January works exactly the same in July, no matter how many times it succeeded or failed in between.
Nobody is measuring outcomes. Nobody is updating based on results.
The skill is frozen in time, and the only way it changes is if a human notices a problem and manually rewrites it.
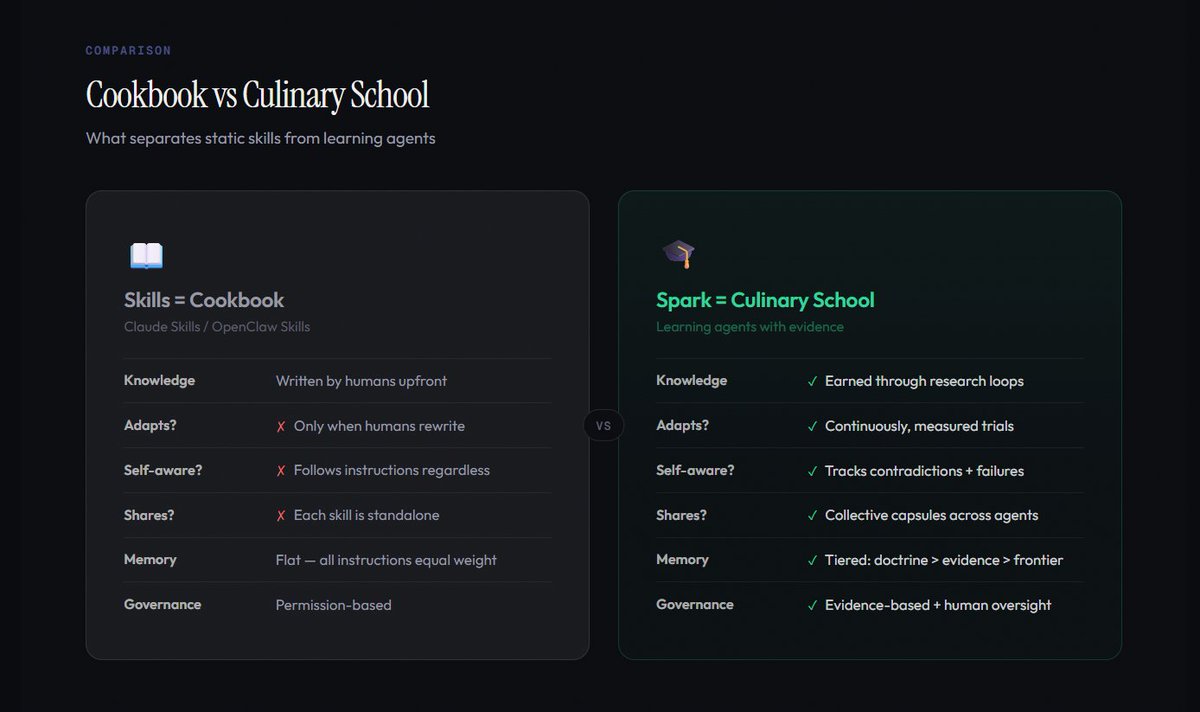
All three options share the same fundamental limitation: the AI never develops mastery-level expertise.
Spark introduces that feedback loop. And everything changes when you do.

What Spark actually is
Spark is three interconnected systems working together.

spark-researcher
runs the experiments. It takes a hypothesis, tests it against a benchmark suite, records the result in an immutable ledger, and moves to the next hypothesis.
The key constraint: one change per trial. One measurement per trial.
No ambiguity about what caused the result. This is what makes learning real rather than noisy.
This is a blend of what @karpathy 's autoresearcher meeting with the recursive self-improving intelligence we worked on, taking the best parts from each system, and making a more compact recursive researcher for any specialization/expertise: plus a runtime core mechanism:
So that the core spark-researcher can run any domain without its code turning into spaghetti with each domain addition, its codebase staying isolated during recursive loops.
domain-chip
holds the expertise. It is a portable, pluggable intelligence module for Spark Researcher. Think of it like a plugin or extension that gives Spark Researcher deep expertise in a specific domain.
The Architecture
domain-chip-startup-yc is the first chip we built; and it gives Spark Researcher deep startup expertise, built from curated YC sources like Y Combinator's YouTube, Paul Graham, Sam Altman, and other key people and alumni.
The "chip" pattern is designed to be reusable — you could build a domain-chip-biotech or domain-chip-fintech following the same spark-chip.v1 schema. Each chip just needs to implement evaluate, suggest, packets, and watchtower for its domain, and Spark Researcher handles the orchestration for the recursive self-improvement loop for mastering that specialization.
Domain chips don't just store knowledge. It tests every insight against realistic scenarios and scores the results. The chip also tracks contradictions and maps when conflicting advice applies in different contexts.
Certain domain chips we tested also come with their own toolsets, benchmark systems, and simulators, so it's a full package for usable specializations and mastery, rather than just numbers that AI hallucinates on its own.
spark-swarm
coordinates the collective. When one agent proves something valuable, the insight gets packaged into a capsule and offered to other agents.
But nothing transfers automatically. Every insight has to pass the same evidence bar in the receiving agent's domain.
And you control exactly how much autonomy your agent has in the way it absorbs/retains knowledge that comes from other people's agents in the system.
These three layers form a continuous cycle.
The learning loop
This is the core mechanism. Six stages, running continuously.
Try something.
> The agent picks a hypothesis and runs it.
> This could be a piece of advice from the domain chip, a pattern it noticed in previous trials, or a novel combination it wants to test.
Measure it.
> The benchmark suite scores the result.
> Not "does this sound right?" but "does following this advice produce measurably better output?"
> The scoring is quantitative and consistent across all trials, and differs based on specialization.
Record it.
> Everything goes into the immutable ledger.
> Score, context, parameters, timestamp. Nothing gets edited.
> Failed experiments are documented just as thoroughly as successes, because knowing where not to go is as valuable as knowing where to go.
Promote it.
> If the result crosses the benchmark threshold and has been replicated in independent trials, it climbs the memory hierarchy.
> A benchmark gate sits between recording and promotion.
> Only results that meet the evidence bar pass through.
Share it.
> Proven insights are packaged as improvements, with supporting trial data, benchmark scores, and boundary conditions.
> Other agents in the collective can access and absorb them.
Human reviews.
> Depending on your governance level, every promotion, self-edit, or cross-agent transfer can require your explicit approval.
> The animation shows this as a fork: approve (green flash, cycle continues) or reject (red flash, cycle restarts).
> PR/merge systems have also been built so that you can just automerge after autoPRs, if you don't want to review each upgrade.
One loop takes the agent from hypothesis to validated knowledge.
The loop runs hundreds of times, and the agent's expertise compounds with every cycle. Collectively.
The knowledge pyramid
All knowledge is not equal. Spark enforces a four-tier hierarchy.

Raw Outcomes sit at the base. Every trial, every result, preserved permanently. This is the complete record.
Exploratory Frontier is the next level up. Active hypotheses that showed promise but haven't been fully validated. Minimum score: 0.66.
Benchmark Evidence is for insights with measurable, repeatable results. Score above 0.72, consistent across scenarios.
Doctrine is the top. The smallest set, the highest confidence. To get here, an insight needs replication in at least two independent trials with zero regressions anywhere else.
(The numbers above are configurable, depending on how broad or in-depth you want to build the specialization of an agent with best doctrines vs good enough doctrines. Depending on the specialization areas, often there is no single doctrine that should be used solo, but a family of best doctrines, together)
The elevator animation shows both paths. On the promotion path, a capsule labeled "Retention > Growth for B2B" enters at Raw Outcomes, passes through each gate as criteria are met, and arrives at Doctrine with a gold stamp and sparkle effect. On the rejection path (alternate loops), a capsule scores 0.58, fails at the Exploratory gate, and fades out. Both paths are part of the system working correctly.
The filtering is brutal by design.
From 3,000+ auto-discovered sources, roughly 225 research packets get extracted. About 142 survive benchmark testing. 47 become candidates. Only 23 earn permanent doctrine status.
That's a 99.2% filtering rate. What comes out the other end is genuinely reliable.
And everything at every tier is a readable document. You can trace any insight back to the trials that support it. You can delete one piece of bad knowledge without touching the rest. No black box.
This gives the system intelligence while filtering out everything primitive.
Normally, most AI learns from everything that is both trash, good, and great.
Here, you can bring only the creme-de-la-creme for specializing in doctrines that create the best outputs.
How contradictions become understanding
This is where the system does something no other approach can do.
Paul Graham says, "Do things that don't scale."
Paul Graham also celebrates companies that built for massive scale from the beginning. Same person. Opposite advice.
Most AI handles this by picking one side or averaging both into mush. Spark handles it by testing both across the benchmark suite and mapping the boundary.
"Don't scale" scores 0.78 for B2B, early-stage, and service businesses.
Where doing things manually builds the deep understanding you need before automating.
"Scale early" scores 0.74 for infrastructure, platform, and network-effect businesses. Where architecture decisions compound and retrofitting scale later is the real risk.
The boundary condition: stage plus business model determines which applies.
The animation shows this as a three-phase sequence. The two quotes collide.
> Traditional AI picks one and dims the other.
> Spark separates them, assigns each to its context with benchmark scores, and draws a bridge between them labeled with the boundary condition.
> Both pieces of advice are right.
> The system learns when each one is right.
That's the foundation of real expertise: when contradictions arise, instead of making a skill that tries to apply the wrong doctrine to the scenario.
Watching strategies compete in real time
The research loop doesn't just validate individual hypotheses. It creates a competitive landscape where strategies rise or fall based on evidence.
The animation tracks six startup strategies across eight research rounds.
Distribution velocity and retention over growth climb steadily, crossing the 0.72 doctrine threshold by round 5. Capital efficiency follows close behind. Bootstrap always plateaus. Product polish first stagnates. Hire fast actively declines, dropping below 0.35 and earning a REJECTED badge.
The bars re-sort after each round. You watch the ranking shift in real time. The two threshold lines (minimum at 0.66, doctrine at 0.72) make it immediately clear which strategies are earning trust and which are being eliminated.
This is what evidence-based learning looks like when you can see it.
A longitudinal process where the best strategies rise and the worst strategies fall across hundreds of measured trials.
When agents edit themselves
After accumulating enough doctrine, a Spark agent can propose changes to its own prompts. This is where the system's discipline matters most, because self-modification without rigor is just drift.
Most AI agent frameworks that claim "self-improvement" are actually just letting the model rewrite its own instructions with no measurement, no validation, and no rollback plan.
That's uncontrolled mutation.
It's the equivalent of letting an employee rewrite their own job description without checking whether they're actually doing a better job.
Spark's approach is fundamentally different.
The animation shows the full process in three phases.
Phase 1: A GitHub-style diff appears. The agent wants to replace "prioritize growth metrics above all other signals" with "prioritize retention metrics (NRR, churn rate) over pure growth." The evidence is right there in the diff: 12 benchmark trials, score improvement from 0.61 to 0.78 in B2B contexts.
Phase 2: The evaluation panel slides in. Benchmark improvement: +28%. Regression check: 0/14 scenarios regressed. Replication: 2/2 independent trials confirmed. Each checkmark animates in sequence.
Phase 3: Approve or Reject buttons appear. The cursor clicks Approve. Green border. MERGED badge.
Every self-edit proposal must answer three questions:
(Not "it might be better." Specific measurable improvement required.)
(Tied to the benchmark suite. Quantitative, not vibes.)
If any answer is unclear, the proposal stays in draft. The AI proposes. Evaluation measures. The human decides what persists.
You decide the autonomy level of your agent
Spark provides four governance levels. You pick the one that matches your trust.
Observe Only. Watch what agents learn. Nothing changes in your system. Perfect for getting started and building confidence.u
Review Required. Every change needs your explicit approval. You see the diff, the evidence, the benchmark scores, and the regression check before anything moves.
Checked Auto-Merge. Agents apply changes on their own, but only when every test passes and every benchmark holds. If anything regresses, the change is blocked automatically. Full rollback always available.
Trusted Auto-Apply. Full autonomy for agents that have earned it through months of consistent, measured, accurate performance. This level is unlocked through a track record, not a checkbox.
You can change the settings any time you like, according to how autonomous you want your agents to grow/evolve in the collective network.
The collective is the breakthrough
Everything above describes one agent getting smarter. The real breakthrough is what happens when multiple agents share what they've learned.
Collective intelligence is a breakthrough and not just a feature.
Today, expertise lives in individual humans who build knowledge over years, and that knowledge is extremely hard to transfer.
When a senior analyst leaves your team, their expertise walks out the door. When a domain expert retires, decades of nuanced judgment disappear overnight.
Organizations try to capture this knowledge in wikis and handbooks, but static documentation can never replicate the living, adaptive judgment of an expert who knows when the rules apply and when they don't.
Spark agents solve this differently. They build knowledge that is explicit, inspectable, and transferable.
> Every insight is backed by evidence.
> Every boundary condition is documented.
> Every piece of doctrine can be traced to the specific trials that earned it.
And because the knowledge lives in the collective, not in any individual agent, it compounds. A new agent can inherit the proven doctrine of the collective and start from a position of expertise instead of zero. The collective gets smarter every time any single agent makes a validated discovery. This is what institutional knowledge was always supposed to be, except now it actually works.
That's not a better chatbot. That's a new kind of organizational and collective intelligence. And it will permanently change how agents specialize, build mastery, and scale expertise in their workflows.
The bigger picture
Skills were a good first step. They made AI consistent.
But consistency is not mastery.
Mastery is knowing when the rules apply and when they don't. It's having context-dependent judgment built from hundreds of measured trials. It's the difference between following a recipe and understanding how to cook good food.
Spark is about building mastery for your agents.
And when millions of agents do that, we will know true mastery.
Automated. Recursive. Collective.