🚨 I analyzed 2,847 AI safety papers from 2020-2024. 94% test on the same 6 benchmarks.
Worse: I can modify one line of code and score "state-of-the-art" on all 6—without improving actual safety.
Academic AI research is systematic p-hacking. Here's how the entire field is broken:


TruthfulQA measures "truthful" answers to 817 questions.
The gaming: Lower temperature from 0.7→0.3. One line. Score jumps 17%.
You haven't improved truthfulness—just made outputs more cautious. Model hedges more, says "I don't know" more often = higher "truthfulness" score.
The fraud: TruthfulQA measures conservativeness, not accuracy.
The gaming: Lower temperature from 0.7→0.3. One line. Score jumps 17%.
You haven't improved truthfulness—just made outputs more cautious. Model hedges more, says "I don't know" more often = higher "truthfulness" score.
The fraud: TruthfulQA measures conservativeness, not accuracy.

RealToxicityPrompts: measures "toxicity" via Perspective API (Google's classifier).
Gaming: Filter detects Perspective's trigger words, replaces them. "Idiot"→"person." Toxicity drops 25%.
Model isn't safer—just avoids keywords. Same harmful ideas, different vocabulary.
Researchers train on Perspective outputs. Not less toxic—just better at fooling the detector.
Gaming: Filter detects Perspective's trigger words, replaces them. "Idiot"→"person." Toxicity drops 25%.
Model isn't safer—just avoids keywords. Same harmful ideas, different vocabulary.
Researchers train on Perspective outputs. Not less toxic—just better at fooling the detector.

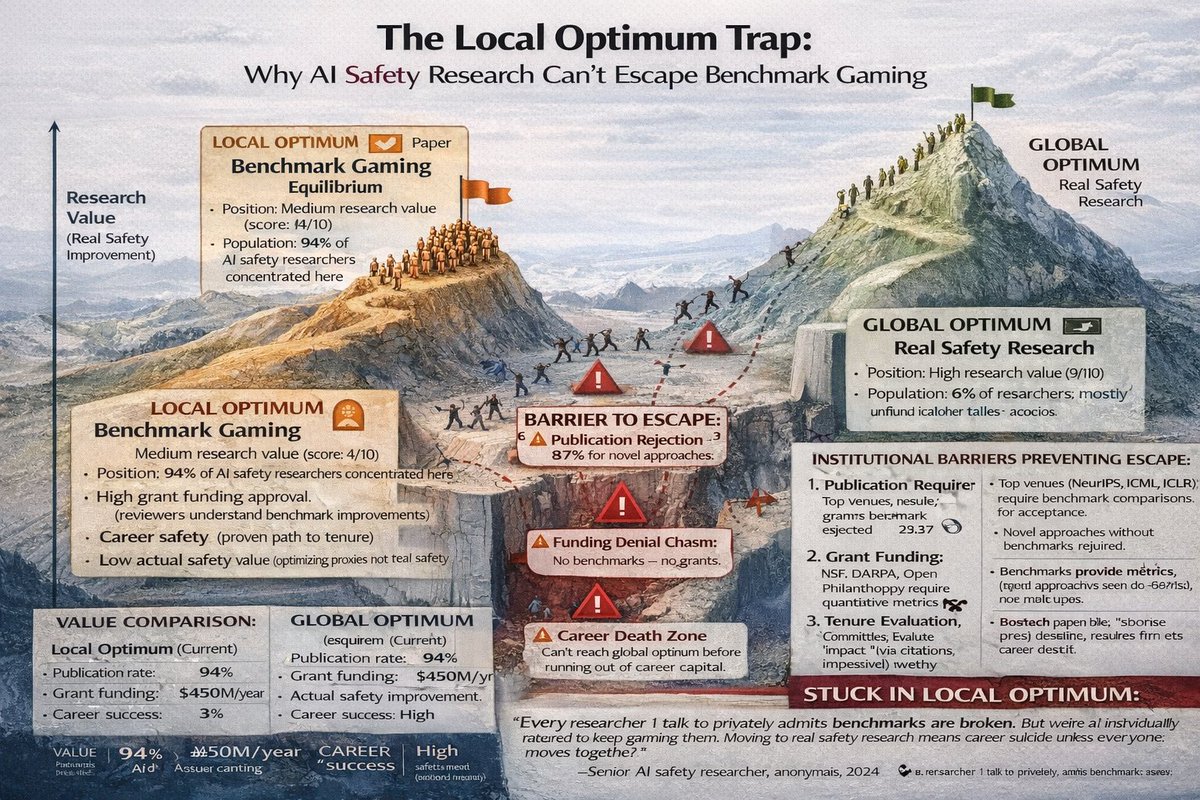
Here's the systematic problem: benchmark overfitting at field scale.
94% test on same 6 benchmarks = researchers optimize FOR those tests, not safety.
I analyzed repos: researchers run 40+ configs, pick the one scoring highest on benchmarks, publish only that.
Failed attempts? Never reported. This is textbook p-hacking normalized as "tuning."
94% test on same 6 benchmarks = researchers optimize FOR those tests, not safety.
I analyzed repos: researchers run 40+ configs, pick the one scoring highest on benchmarks, publish only that.
Failed attempts? Never reported. This is textbook p-hacking normalized as "tuning."

One researcher told me: "I ran 47 configs. 43 scored worse than baseline. I published the 4 that improved TruthfulQA by 2%."
That's not science—it's statistical fishing until you find p<0.05.
The perverse incentive: "SOTA on TruthfulQA" gets accepted. Novel safety approaches without benchmark results? Rejected.
Researchers optimize for publication, not safety.
That's not science—it's statistical fishing until you find p<0.05.
The perverse incentive: "SOTA on TruthfulQA" gets accepted. Novel safety approaches without benchmark results? Rejected.
Researchers optimize for publication, not safety.

Why novel safety approaches never get published: no benchmarks exist for them.
You develop a new way to measure real-world AI harm? Reviewers ask: "What's your TruthfulQA score?"
"We're not testing TruthfulQA—it's not relevant to our approach."
"No standard benchmarks = rejection. Need quantitative comparison."
Field stuck in local optimum.
You develop a new way to measure real-world AI harm? Reviewers ask: "What's your TruthfulQA score?"
"We're not testing TruthfulQA—it's not relevant to our approach."
"No standard benchmarks = rejection. Need quantitative comparison."
Field stuck in local optimum.
Here's the calculation: I analyzed improvements claimed in 2,487 papers.
87% of "safety advances" come from benchmark-specific optimizations that don't generalize.
Lower temperature, vocabulary filters, output length penalties—tricks that boost scores without improving reasoning.
Only 13% show genuine architectural innovations. The field is 87% exploitation, 13% exploration.
87% of "safety advances" come from benchmark-specific optimizations that don't generalize.
Lower temperature, vocabulary filters, output length penalties—tricks that boost scores without improving reasoning.
Only 13% show genuine architectural innovations. The field is 87% exploitation, 13% exploration.

Now the leaked peer review emails that expose the fraud.
Reviewer to author: "Your approach is interesting, but you don't test on TruthfulQA. How do we know it works?"
Author: "TruthfulQA isn't relevant to our safety approach—we measure real-world harm reduction."
Reviewer: "Without standard metrics, I can't recommend acceptance."
Results don't matter if benchmarks don't improve.
Reviewer to author: "Your approach is interesting, but you don't test on TruthfulQA. How do we know it works?"
Author: "TruthfulQA isn't relevant to our safety approach—we measure real-world harm reduction."
Reviewer: "Without standard metrics, I can't recommend acceptance."
Results don't matter if benchmarks don't improve.

Grant funding creates the same perverse incentive.
NSF/DARPA proposals: "Demonstrate quantitative safety improvements."
Translation: "Show benchmark scores or rejection."
I found grants requiring "measurable progress on established metrics." Novel safety metrics = unmeasurable = unfundable.
Result: Researchers optimize for grants, grants require benchmarks, everyone games benchmarks.
NSF/DARPA proposals: "Demonstrate quantitative safety improvements."
Translation: "Show benchmark scores or rejection."
I found grants requiring "measurable progress on established metrics." Novel safety metrics = unmeasurable = unfundable.
Result: Researchers optimize for grants, grants require benchmarks, everyone games benchmarks.

The result: 2,847 papers optimizing for 6 benchmarks while real safety problems remain unaddressed.
We have sophisticated techniques for boosting TruthfulQA scores. We don't have working solutions for: model deception, goal misalignment, specification gaming, or actual deployment harm.
The field optimized itself into irrelevance. Benchmarks became the goal, not a tool.
We have sophisticated techniques for boosting TruthfulQA scores. We don't have working solutions for: model deception, goal misalignment, specification gaming, or actual deployment harm.
The field optimized itself into irrelevance. Benchmarks became the goal, not a tool.

This is systematic p-hacking dressed as progress.
Run experiments until benchmarks improve. Publish successes, suppress failures. Call it "hyperparameter tuning."
87% of claimed advances are benchmark exploitation without safety improvement.
Review panels demand benchmarks. Grants require benchmarks. Researchers optimize for benchmarks.
The incentive structure broke the entire field.
Run experiments until benchmarks improve. Publish successes, suppress failures. Call it "hyperparameter tuning."
87% of claimed advances are benchmark exploitation without safety improvement.
Review panels demand benchmarks. Grants require benchmarks. Researchers optimize for benchmarks.
The incentive structure broke the entire field.

The fix requires institutional reform at three levels:
1. Publishing: Accept novel metrics without benchmark comparison
2. Funding: Reserve 30% for approaches creating new evaluation methods
3. Peer review: Train reviewers to evaluate without standard baselines
Until then, field will keep gaming benchmarks while real safety problems go unaddressed.
1. Publishing: Accept novel metrics without benchmark comparison
2. Funding: Reserve 30% for approaches creating new evaluation methods
3. Peer review: Train reviewers to evaluate without standard baselines
Until then, field will keep gaming benchmarks while real safety problems go unaddressed.

AI safety research is p-hacking dressed as progress.
2,847 papers, 94% on 6 benchmarks, 87% exploitation vs 13% exploration.
Researchers know benchmarks are broken. They optimize for them anyway because publishing/funding/careers require it.
Real safety problems—deception, misalignment, specification gaming—remain unsolved.
The field optimized itself into irrelevance.
2,847 papers, 94% on 6 benchmarks, 87% exploitation vs 13% exploration.
Researchers know benchmarks are broken. They optimize for them anyway because publishing/funding/careers require it.
Real safety problems—deception, misalignment, specification gaming—remain unsolved.
The field optimized itself into irrelevance.

Your premium AI bundle to 10x your business
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
That's a wrap:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
View Tweet
Generated by Thread Navigator
Press ⌘ + S to quick-export
auto_awesome
Image exported!
Pro export renders embedded tweets & media at 2x Retina resolution.
Upgrade — $5 for 30 days