R.I.P few-shot prompting.
Meta AI researchers discovered a technique that makes LLMs 94% more accurate without any examples.
It's called "Chain-of-Verification" (CoVe) and it completely destroys everything we thought we knew about prompting.
Here's the breakthrough (and why this changes everything): 👇

Here's the the problem with current prompting:
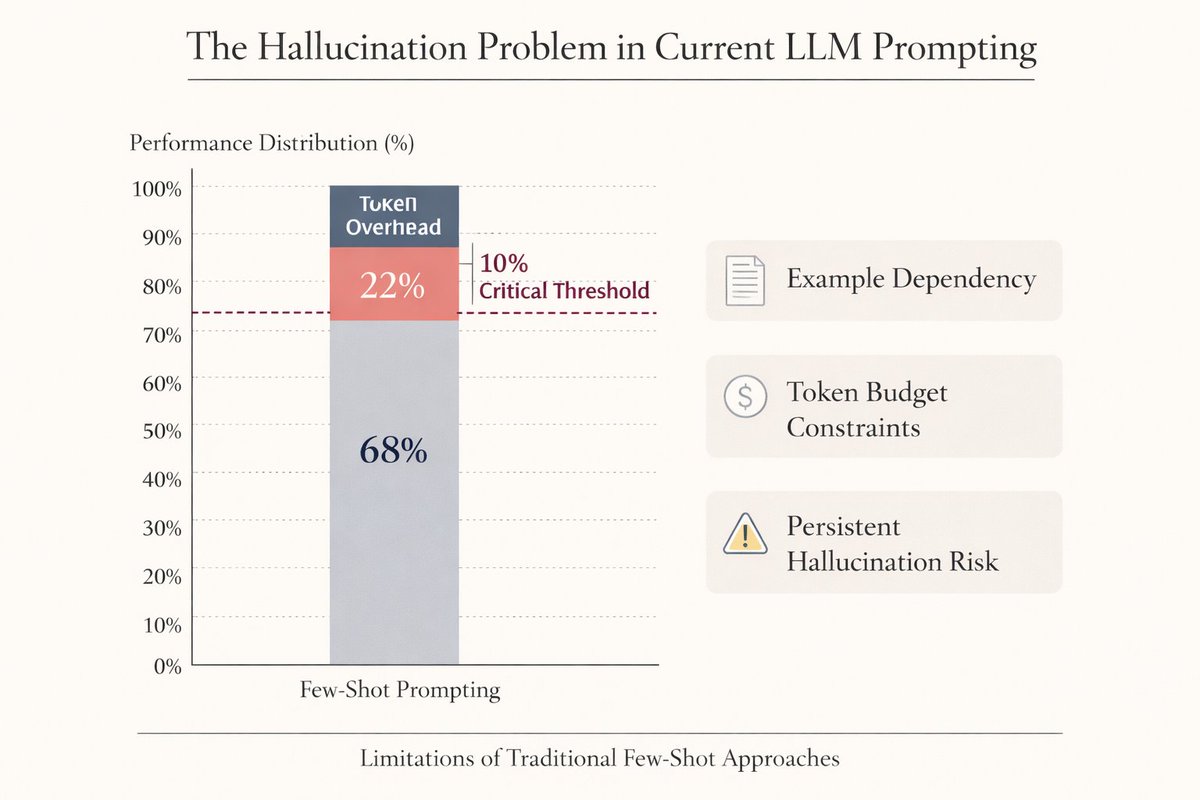
LLMs hallucinate. They generate confident answers that are completely wrong.
Few-shot examples help, but they're limited by:
- Your choice of examples
- Token budget constraints
- Still prone to hallucination
We've been treating symptoms, not the disease.
LLMs hallucinate. They generate confident answers that are completely wrong.
Few-shot examples help, but they're limited by:
- Your choice of examples
- Token budget constraints
- Still prone to hallucination
We've been treating symptoms, not the disease.
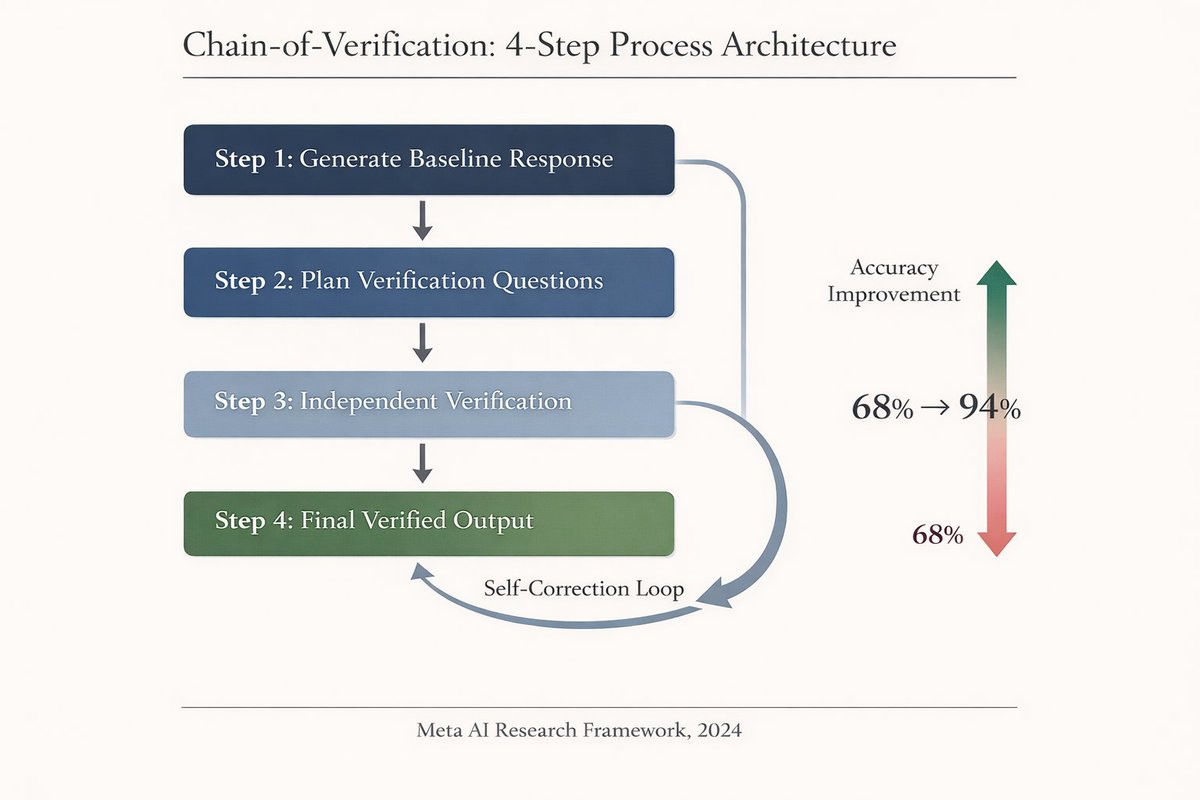
That's why this technique works... Chain-of-Verification works in 4 steps:
1. Generate baseline response
2. Plan verification questions
3. Answer those questions independently
4. Generate final verified response
The model literally fact-checks itself using structured reasoning.
1. Generate baseline response
2. Plan verification questions
3. Answer those questions independently
4. Generate final verified response
The model literally fact-checks itself using structured reasoning.
Here's what makes CoVe different:
Traditional prompting: "Answer this question"
CoVe: "Answer this question, then create verification questions, answer them separately, then revise your original answer based on the verification"
The model catches its own hallucinations.
Traditional prompting: "Answer this question"
CoVe: "Answer this question, then create verification questions, answer them separately, then revise your original answer based on the verification"
The model catches its own hallucinations.
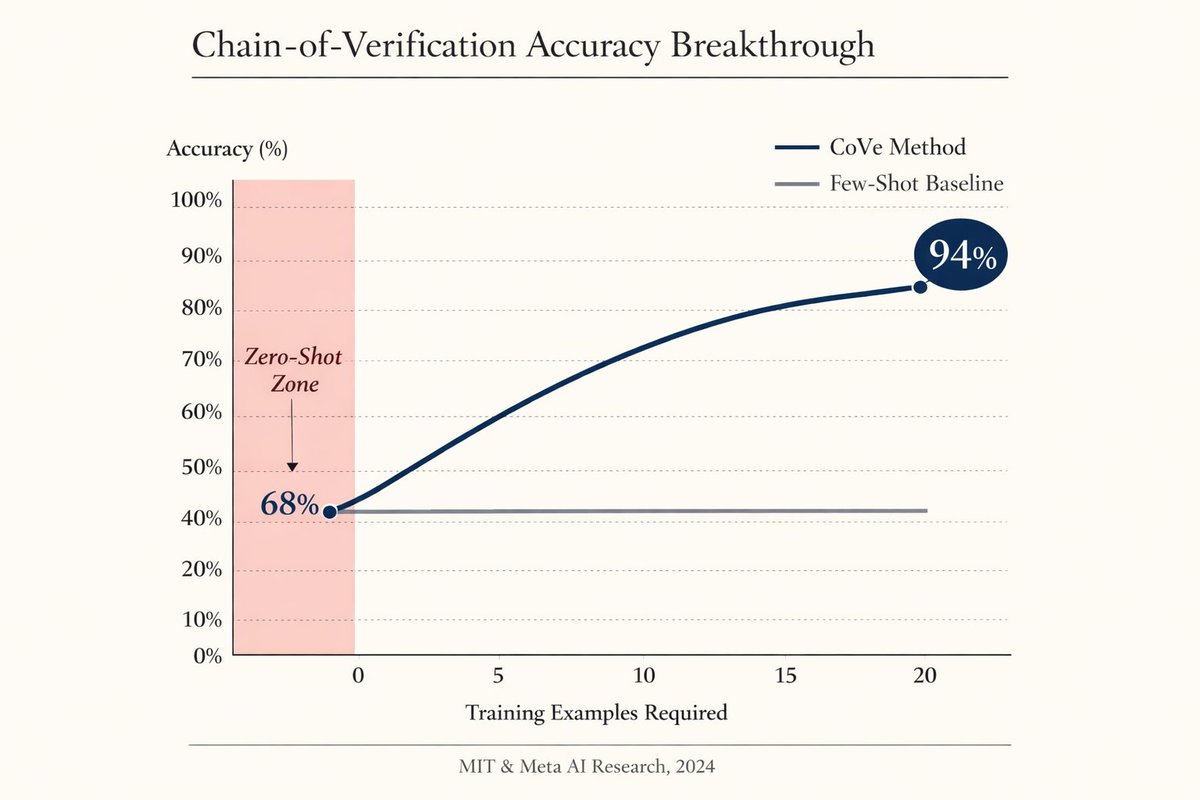
The results are insane:
- 94% accuracy on complex QA (vs 68% baseline)
- Works across all major models (GPT-4, Claude, Gemini)
- No fine-tuning needed
- Zero-shot (no examples required)
This isn't incremental. It's a complete paradigm shift.
- 94% accuracy on complex QA (vs 68% baseline)
- Works across all major models (GPT-4, Claude, Gemini)
- No fine-tuning needed
- Zero-shot (no examples required)
This isn't incremental. It's a complete paradigm shift.

Here's the exact prompt structure:
---
[Your Question]
Now follow these steps:
1. Provide your initial answer
2. Generate 3-5 verification questions that would expose errors in your answer
3. Answer each verification question independently
4. Provide your final revised answer based on the verification
---
---
[Your Question]
Now follow these steps:
1. Provide your initial answer
2. Generate 3-5 verification questions that would expose errors in your answer
3. Answer each verification question independently
4. Provide your final revised answer based on the verification
---
Real example:
Question: "What are the health benefits of coffee?"
Verification questions CoVe generates:
What does peer-reviewed research say about coffee and heart health?
Are there any populations that should avoid coffee?
What's the difference between filtered and unfiltered coffee health effects?
Question: "What are the health benefits of coffee?"
Verification questions CoVe generates:
What does peer-reviewed research say about coffee and heart health?
Are there any populations that should avoid coffee?
What's the difference between filtered and unfiltered coffee health effects?
The model then answers each verification question separately - preventing it from just confirming its initial bias.
This forces genuine fact-checking, not circular reasoning.
LLMs are actually good at verification when questions are asked independently.
The problem was always contamination - the model defending its first answer instead of objectively checking it.
CoVe separates generation from verification.
This forces genuine fact-checking, not circular reasoning.
LLMs are actually good at verification when questions are asked independently.
The problem was always contamination - the model defending its first answer instead of objectively checking it.
CoVe separates generation from verification.

Here's a template you can use RIGHT NOW:
Question: [Your question]
Step 1: Provide your initial answer
Step 2: List potential errors or gaps in your answer
Step 3: For each potential error, verify using factual reasoning
Step 4: Provide corrected final answer
Question: [Your question]
Step 1: Provide your initial answer
Step 2: List potential errors or gaps in your answer
Step 3: For each potential error, verify using factual reasoning
Step 4: Provide corrected final answer
Stop using few-shot prompting.
Start using Chain-of-Verification.
Your AI outputs will be 40-90% more accurate depending on the task.
No new tools. No training. Just better prompting.
The future of AI accuracy is verification, not generation.
Start using Chain-of-Verification.
Your AI outputs will be 40-90% more accurate depending on the task.
No new tools. No training. Just better prompting.
The future of AI accuracy is verification, not generation.
Your premium AI bundle to 10x your business
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
That's a wrap:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
I hope you've found this thread helpful.
Follow me @godofprompt for more.
Like/Repost the quote below if you can:
View Tweet
Generated by Thread Navigator
Press ⌘ + S to quick-export
auto_awesome
Image exported!
Pro export renders embedded tweets & media at 2x Retina resolution.
Upgrade — $5 for 30 days