🚨 This is wild.
A new paper from the Ling team just dropped "Every Attention Matters" and it quietly rewrites how long-context reasoning works in LLMs.
Their new Ring-linear architecture mixes Softmax and Linear Attention, cutting inference cost by 10x while keeping SOTA accuracy up to 128K tokens.
Even crazier:
• Training efficiency +50%
• Inference speed +90%
• Stable RL optimization over ultra-long sequences
Basically, they solved long-context scaling without trillion-parameter overkill.
The future isn’t bigger models. It’s smarter attention.

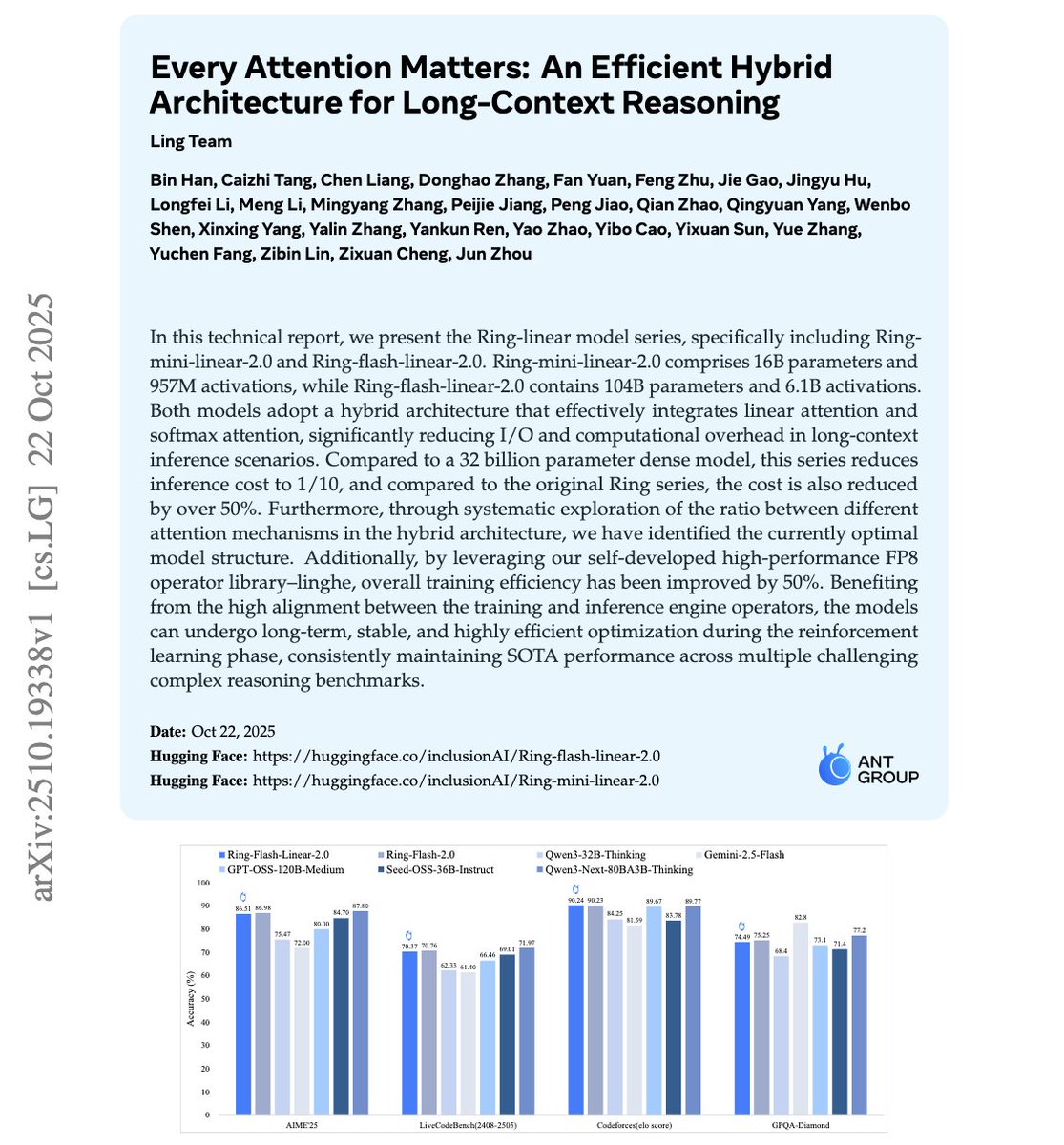
This chart blew my mind.
Ring-flash-linear-2.0 doesn’t just match 100B+ reasoning models it beats them across AIME’25, GPQA, and Codeforces while costing 10x less to run.
Efficiency has officially overtaken scale.
Ring-flash-linear-2.0 doesn’t just match 100B+ reasoning models it beats them across AIME’25, GPQA, and Codeforces while costing 10x less to run.
Efficiency has officially overtaken scale.
The secret is its hybrid design.
Instead of choosing between Softmax and Linear Attention, it uses both stacking multiple linear layers for speed and a single softmax layer for expressiveness. It’s like giving transformers short-term memory and long-term focus.
Instead of choosing between Softmax and Linear Attention, it uses both stacking multiple linear layers for speed and a single softmax layer for expressiveness. It’s like giving transformers short-term memory and long-term focus.

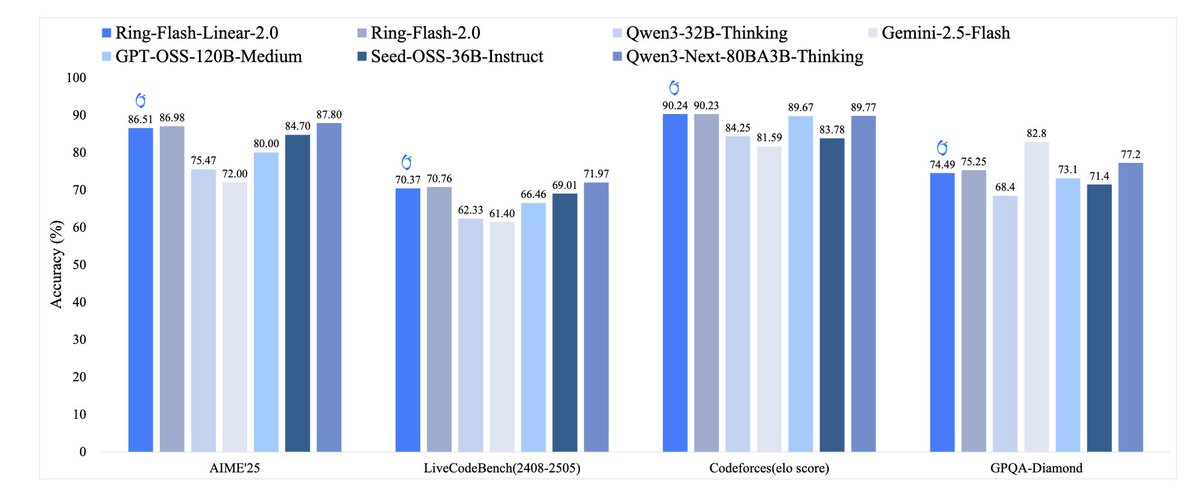
When they plotted performance vs compute, the line just… broke physics.
Hybrid linear models achieve lower loss with fewer FLOPs outpacing traditional scaling laws entirely.
This is the first time efficiency scales better than brute force.
Hybrid linear models achieve lower loss with fewer FLOPs outpacing traditional scaling laws entirely.
This is the first time efficiency scales better than brute force.
Memory usage barely moves as context length grows.
While normal transformers choke on 128K tokens, Ring-linear’s KV-cache stays flat. That means no I/O bottleneck, no decode lag, just smooth long-context reasoning.
While normal transformers choke on 128K tokens, Ring-linear’s KV-cache stays flat. That means no I/O bottleneck, no decode lag, just smooth long-context reasoning.

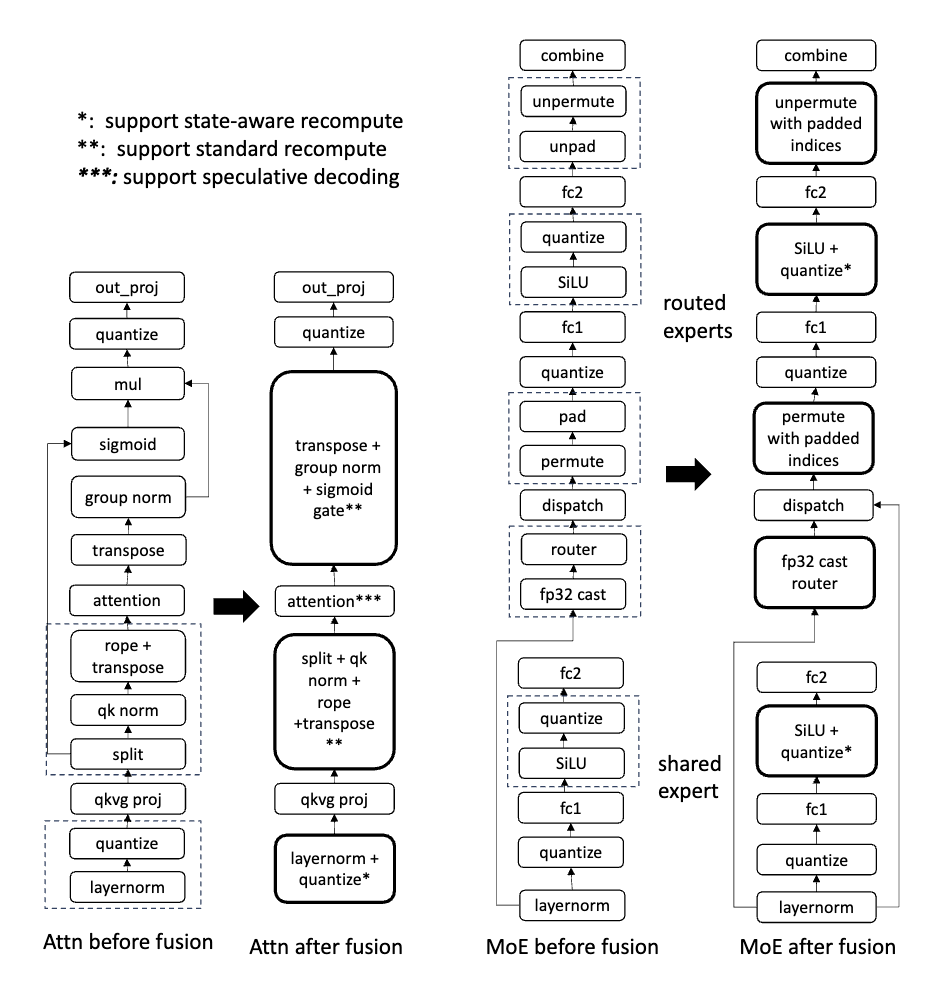
They rebuilt the whole compute stack.
Every operation normalization, gating, routing, projection fused into single GPU kernels. Less memory traffic, less latency, more throughput.
It’s how you turn math into raw performance.
Every operation normalization, gating, routing, projection fused into single GPU kernels. Less memory traffic, less latency, more throughput.
It’s how you turn math into raw performance.
The payoff? 77% faster training on Ring-mini-linear. 57% faster on Ring-flash-linear.
Same GPUs, same precision just smarter engineering.
Proof that optimization is the new scaling.
Same GPUs, same precision just smarter engineering.
Proof that optimization is the new scaling.

At 128K context, it runs 8× faster than Qwen3-8B while generating cleaner, more consistent outputs. Prefill and decode both scale linearly, not exponentially.
Long-context isn’t theoretical anymore. It’s solved.
Long-context isn’t theoretical anymore. It’s solved.
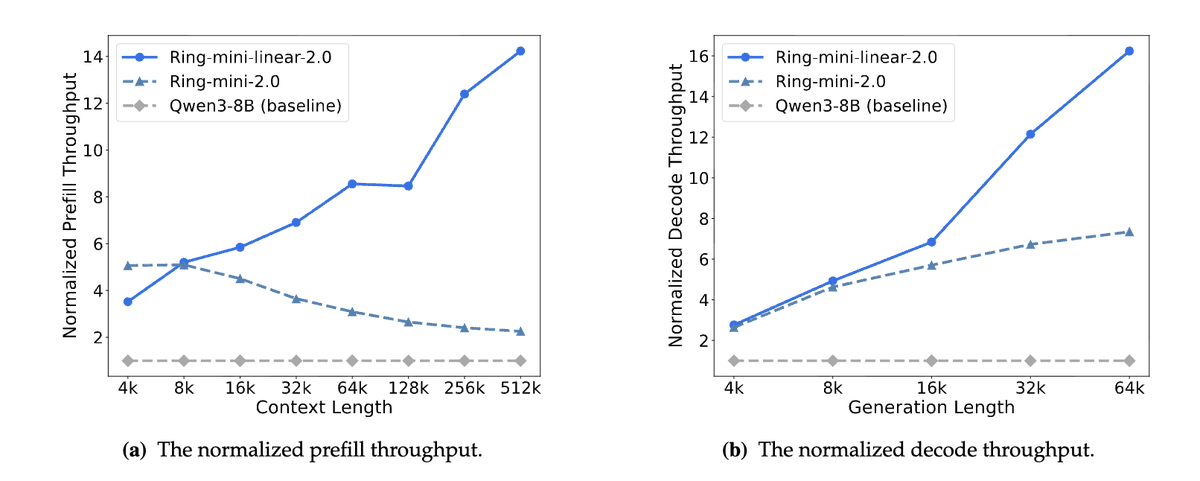
Even the largest version hits 2.5× prefill and 2× decode throughput vs its predecessor with better accuracy.
No trick, no pruning, no compromise.
Just smarter attention done right.
No trick, no pruning, no compromise.
Just smarter attention done right.

Generated by Thread Navigator
Press ⌘ + S to quick-export
auto_awesome
Image exported!
Pro export renders embedded tweets & media at 2x Retina resolution.
Upgrade — $5 for 30 days