🚨 DeepSeek just did something wild.
They built an OCR system that compresses long text into vision tokens literally turning paragraphs into pixels.
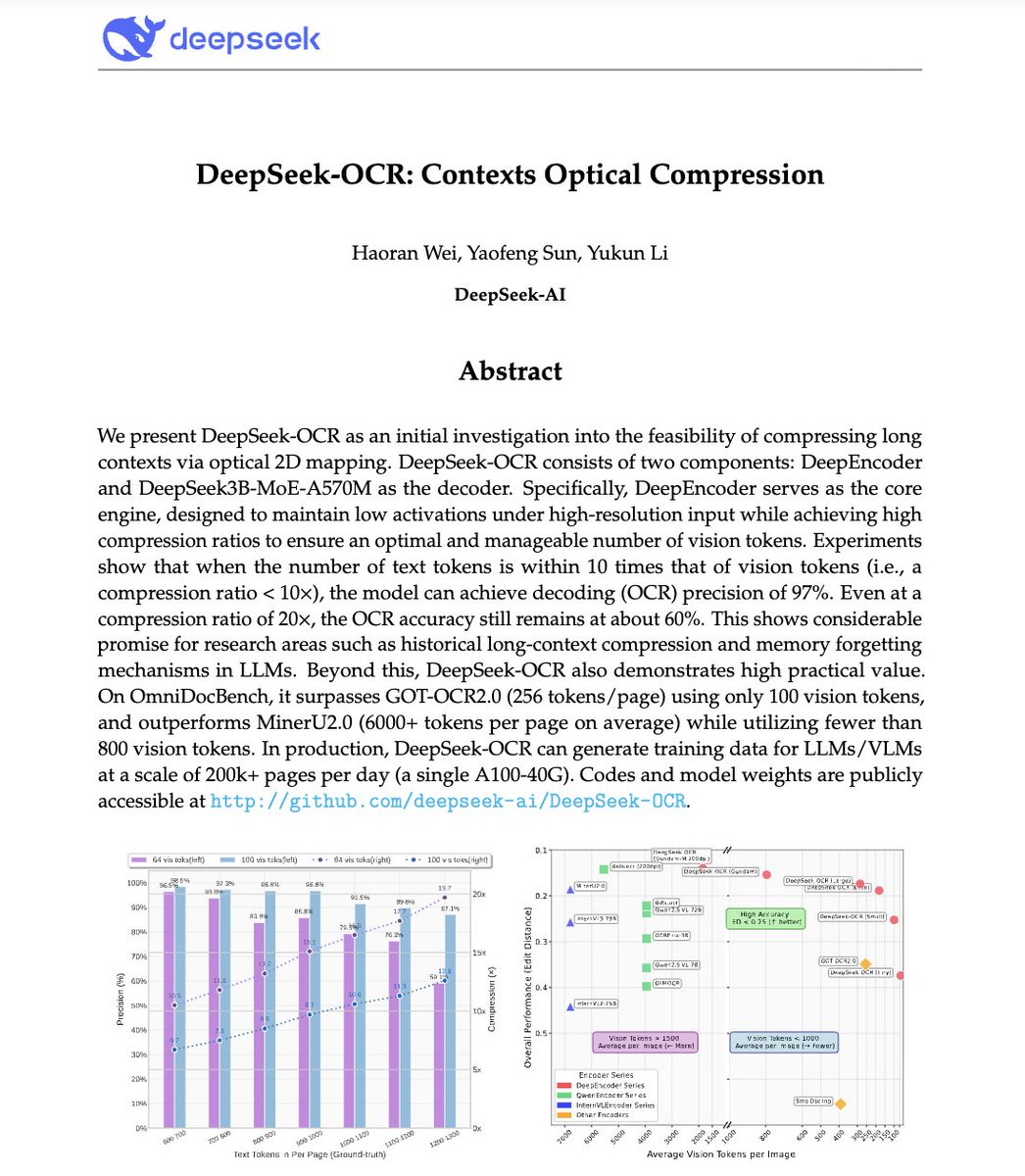
Their model, DeepSeek-OCR, achieves 97% decoding precision at 10× compression and still manages 60% accuracy even at 20×. That means one image can represent entire documents using a fraction of the tokens an LLM would need.
Even crazier? It beats GOT-OCR2.0 and MinerU2.0 while using up to 60× fewer tokens and can process 200K+ pages/day on a single A100.
This could solve one of AI’s biggest problems: long-context inefficiency.
Instead of paying more for longer sequences, models might soon see text instead of reading it.
The future of context compression might not be textual at all.
It might be optical 👁️
github. com/deepseek-ai/DeepSeek-OCR

1. Vision-Text Compression: The Core Idea
LLMs struggle with long documents because token usage scales quadratically with length.
DeepSeek-OCR flips that: instead of reading text, it encodes full documents as vision tokens each token representing a compressed piece of visual information.
Result: You can fit 10 pages worth of text into the same token budget it takes to process 1 page in GPT-4.
LLMs struggle with long documents because token usage scales quadratically with length.
DeepSeek-OCR flips that: instead of reading text, it encodes full documents as vision tokens each token representing a compressed piece of visual information.
Result: You can fit 10 pages worth of text into the same token budget it takes to process 1 page in GPT-4.

2. DeepEncoder - The Optical Compressor
Meet the star: DeepEncoder.
It uses two backbones SAM (for perception) and CLIP (for global vision) bridged by a 16× convolutional compressor.
This allows it to maintain high-res understanding without exploding activation memory.
The encoder converts thousands of image patches → a few hundred compact vision tokens.
Meet the star: DeepEncoder.
It uses two backbones SAM (for perception) and CLIP (for global vision) bridged by a 16× convolutional compressor.
This allows it to maintain high-res understanding without exploding activation memory.
The encoder converts thousands of image patches → a few hundred compact vision tokens.

3. Multi-Resolution “Gundam” Mode
Documents vary invoices ≠ blueprints ≠ newspapers.
To handle this, DeepSeek-OCR supports multiple resolution modes: Tiny, Small, Base, Large, and Gundam.
Gundam mode combines local tiles + a global view scaling from 512×512 to 1280×1280 efficiently.
One model, multiple resolutions, no retraining.
Documents vary invoices ≠ blueprints ≠ newspapers.
To handle this, DeepSeek-OCR supports multiple resolution modes: Tiny, Small, Base, Large, and Gundam.
Gundam mode combines local tiles + a global view scaling from 512×512 to 1280×1280 efficiently.
One model, multiple resolutions, no retraining.

4. Data Engine OCR 1.0 to 2.0
They didn’t just train on text scans.
DeepSeek-OCR’s data includes:
• 30M+ PDF pages across 100 languages
• 10M natural scene OCR samples
• 10M charts + 5M chemical formulas + 1M geometry problems
It’s not just reading it’s parsing scientific diagrams, equations, and layouts.
They didn’t just train on text scans.
DeepSeek-OCR’s data includes:
• 30M+ PDF pages across 100 languages
• 10M natural scene OCR samples
• 10M charts + 5M chemical formulas + 1M geometry problems
It’s not just reading it’s parsing scientific diagrams, equations, and layouts.

5.
This isn’t “just another OCR.”
It’s a proof of concept for context compression.
If text can be represented visually with 10× fewer tokens LLMs could use the same idea for long-term memory and efficient reasoning.
Imagine GPT-5 processing a 1M-token document as a 100K-token image map.
This isn’t “just another OCR.”
It’s a proof of concept for context compression.
If text can be represented visually with 10× fewer tokens LLMs could use the same idea for long-term memory and efficient reasoning.
Imagine GPT-5 processing a 1M-token document as a 100K-token image map.

Stop wasting hours writing prompts
→ 10,000+ ready-to-use prompts
→ Create your own in seconds
→ Lifetime access. One-time payment.
Claim your copy 👇
godofprompt.ai/pricing
→ 10,000+ ready-to-use prompts
→ Create your own in seconds
→ Lifetime access. One-time payment.
Claim your copy 👇
godofprompt.ai/pricing
Generated by Thread Navigator
Press ⌘ + S to quick-export
auto_awesome
Image exported!
Pro export renders embedded tweets & media at 2x Retina resolution.
Upgrade — $5 for 30 days