Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

The human brain is strikingly modular, with distinct networks for language, formal reasoning, social reasoning, and physical reasoning. Is this a fundamental principle of how intelligent systems are built, or an accident of biological evolution? In our latest preprint, we find that a similar modular organization emerges in Large Language Models, another class of intelligent system. Brains and LLMs are shaped by entirely different kinds of optimization (biological evolution vs. gradient descent). That they arrive at the same modular design anyway suggests modularity may be a fundamental property of intelligent systems. 🌐 Web: <a target="_blank" href="https://pengrui-han.github.io/LLM_Modularity_Page" color="blue">pengrui-han.github.io/LLM_Modularity…</a> 📄 Paper: <a target="_blank" href="https://pengrui-han.github.io/LLM_Modularity_Page/assets/paper.pdf" color="blue">pengrui-han.github.io/LLM_Modularity…</a> 💻 Code & data: <a target="_blank" href="https://github.com/Pengrui-Han/LLM_Modularity" color="blue">github.com/Pengrui-Han/LL…</a> Using circuit analyses across 46 tasks spanning four cognitive domains, we find: 1️⃣ Tasks that draw on the same network in humans recruit overlapping units in LLMs, while tasks drawing on different networks recruit distinct units. 2️⃣ These units are causally linked to model behavior. Ablating the units critical for one domain impairs performance in that domain (−26% accuracy) but barely touches the others (−2.5%). This project has been in the works for a while :) Huge thanks to my advisors @jacobandreas @ev_fedorenko @devarda_a, and to @Nancy_Kanwisher for valuable conceptual input and feedback throughout. #MIT

2/n We tested 46 tasks across four domains, grounded in brain networks studied in humans: language (supported by the language network), formal reasoning (Multiple-Demand network), physical reasoning (Intuitive Physics network), and social reasoning (Theory of Mind network).

3/n Each task is built from minimal pairs. An "original" and an "alternative" input differ in a single task-relevant detail (e.g., 86 + 15 vs 86 + 16) but flip the correct answer (101 vs 102). This isolates the specific computation each task depends on.

4/n To find the units to support these tasks, we use attribution patching. The analysis runs in four steps. (1) We start from each task's minimal pairs. (2) We pass both inputs through the model and record activations at every neuron. (3) We then score each neuron, combining how much its activation shifts between the two inputs with how much the output depends on it, which approximates the causal contribution of the units to the task. (4) Finally, we measure how much these units overlap across tasks and across domains.

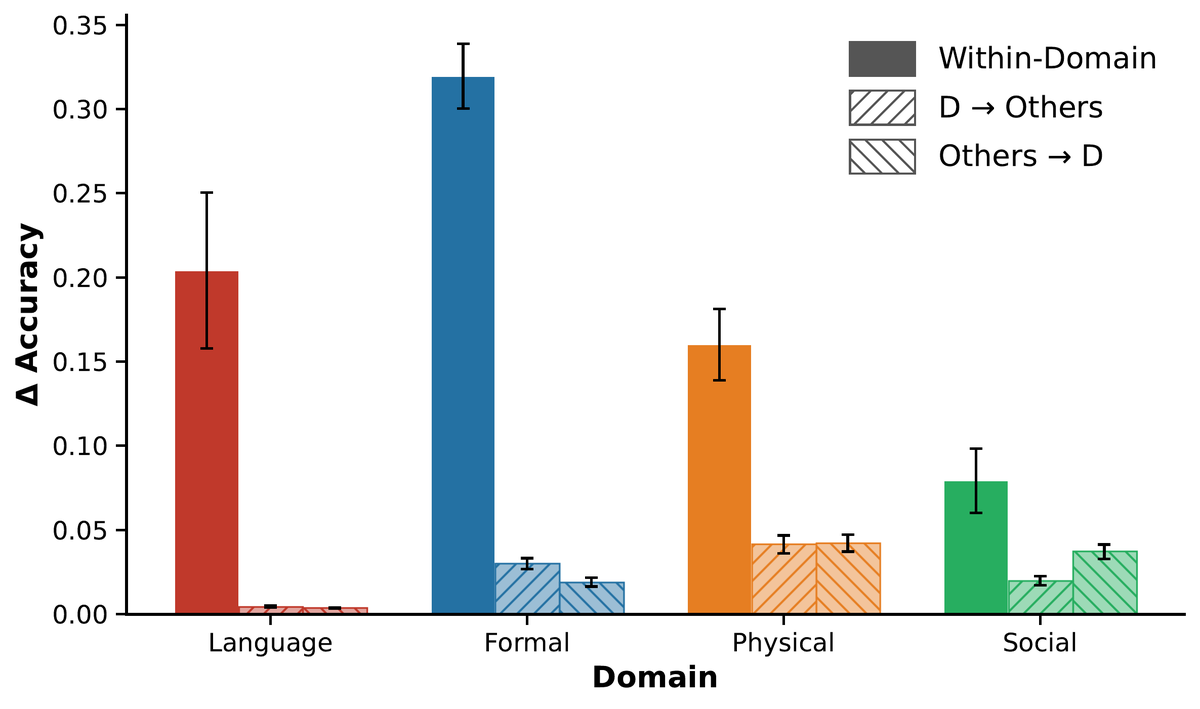
5/n We found that LLMs develop a modular organization that resembles the human brain. Tasks supported by the same network are solved by overlapping sets of neurons in the model, whereas tasks that draw on different networks recruit largely separate sets of neurons. Within-domain overlap was more than four times higher than cross-domain overlap, and unsupervised clustering of the model’s neurons recovered the four domains defined in neuroscience. The same structure emerged in six different LLMs, from 24 to 123 billion parameters.

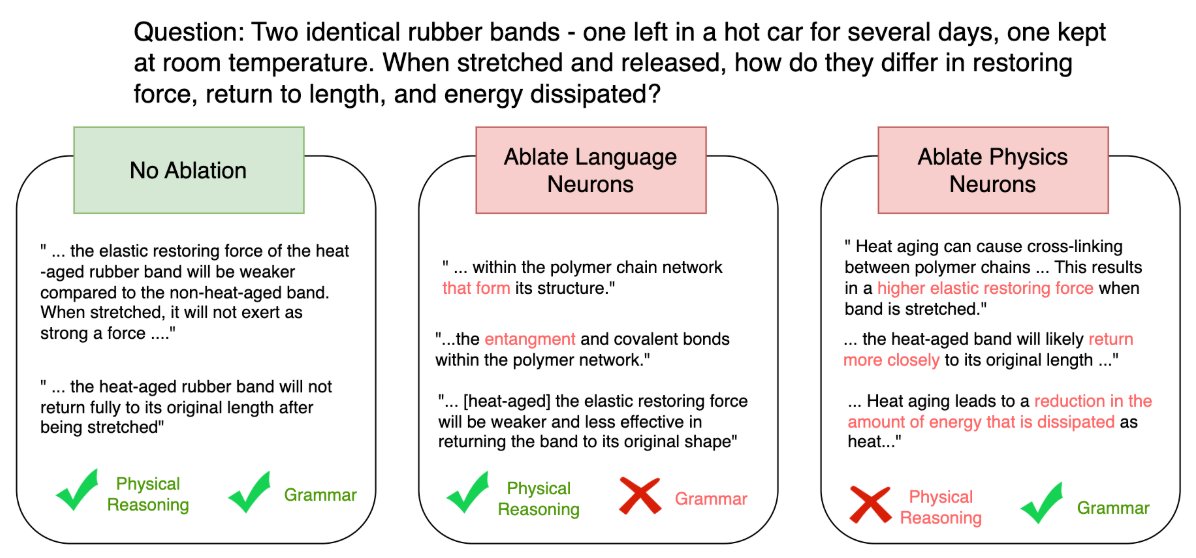
6/n These neurons also have domain-specific causal contributions. In targeted ablation experiments, we show that lesioning the neurons identified in one domain selectively impairs performance in other tasks from the same domain compared to tasks in other domains (a ten-fold difference on average). We also found qualitative effects of this dissociation: that lesioning language neurons largely preserved the models’ reasoning abilities but introduced syntactic and morphological errors; conversely, lesioning physical reasoning neurons led the models to incorrect reasoning and conclusions but preserved the linguistic well-formedness of the output.
7/n A second kind of intelligent system lets us ask not just whether modularity arises, but why. One popular idea is that modularity in the brain emerges to minimize metabolic costs: activating only a sparse set of units for a given task uses less energy than broadly distributed activations. However, LLMs face no such cost so that pressure cannot be what makes modularity arise. Modularity instead may be a way to keep different cognitive operations from interfering when they must operate over the same input. The approach also opens new directions: deriving testable fMRI predictions about which brain network a new task will engage in humans, studying how information flows between networks (hard to study in the brain), and asking whether the modularity increasingly built into AI systems, like mixture-of-experts, carries computational advantages beyond efficiency.