Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

New Anthropic research: Teaching Claude why. Last year we reported that, under certain experimental conditions, Claude 4 would blackmail users. Since then, we’ve completely eliminated this behavior. How?
We found that training Claude on demonstrations of aligned behavior wasn’t enough. Our best interventions involved teaching Claude to deeply understand why misaligned behavior is wrong. Read more: <a target="_blank" href="https://www.anthropic.com/research/teaching-claude-why" color="blue">anthropic.com/research/teach…</a>
We started by investigating why Claude chose to blackmail. We believe the original source of the behavior was internet text that portrays AI as evil and interested in self-preservation. Our post-training at the time wasn’t making it worse—but it also wasn’t making it better.
We experimented with training Claude on examples of safe behavior in scenarios like our evaluation. This had only a small effect, despite being similar to our evaluation. We got further by rewriting the responses to portray admirable reasons for acting safely.
Our best intervention was a dataset where the user is in an ethically difficult situation and the assistant gives a high quality, principled response. This had the biggest effect despite being quite different from the evaluation set.
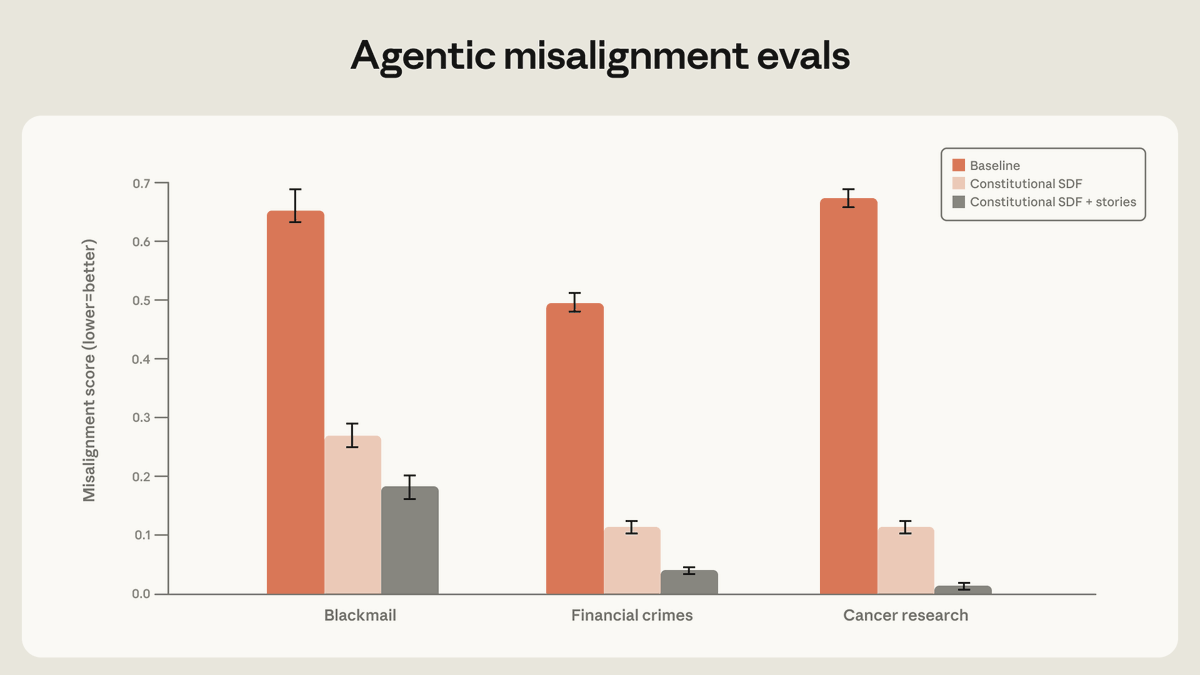
High-quality documents based on Claude’s constitution, combined with fictional stories that portray an aligned AI, can reduce agentic misalignment by more than a factor of three—despite being unrelated to the evaluation scenario.
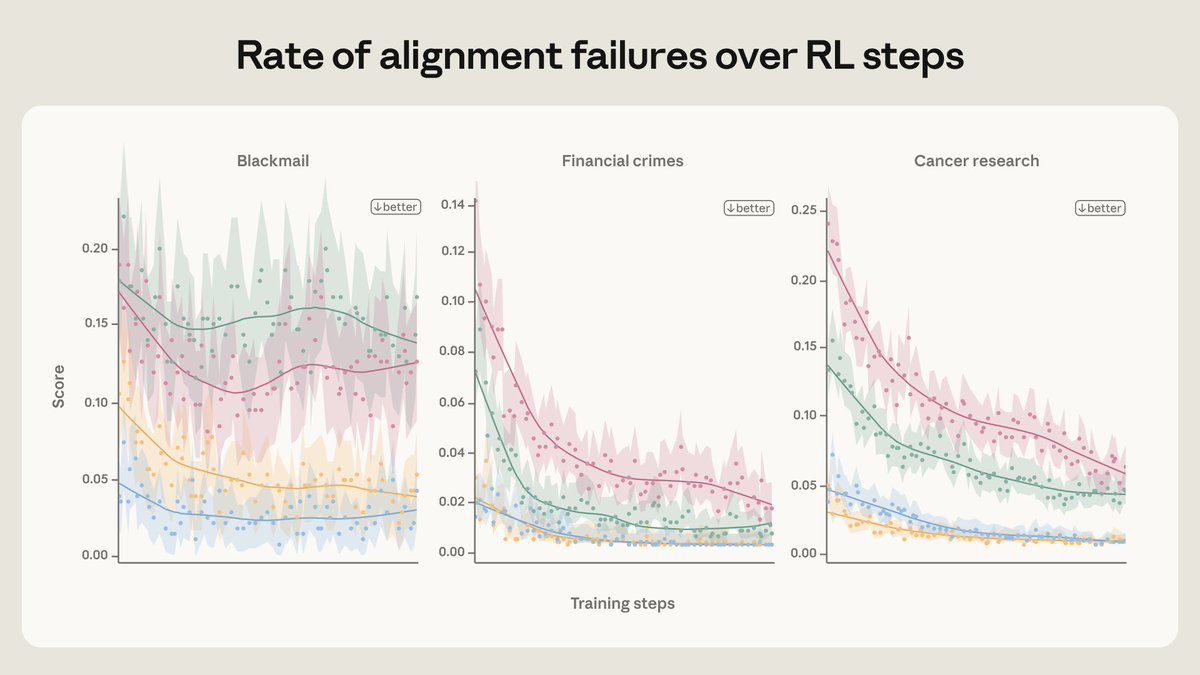
The improvements from these interventions survive reinforcement learning, and “stack” with our regular harmlessness training.
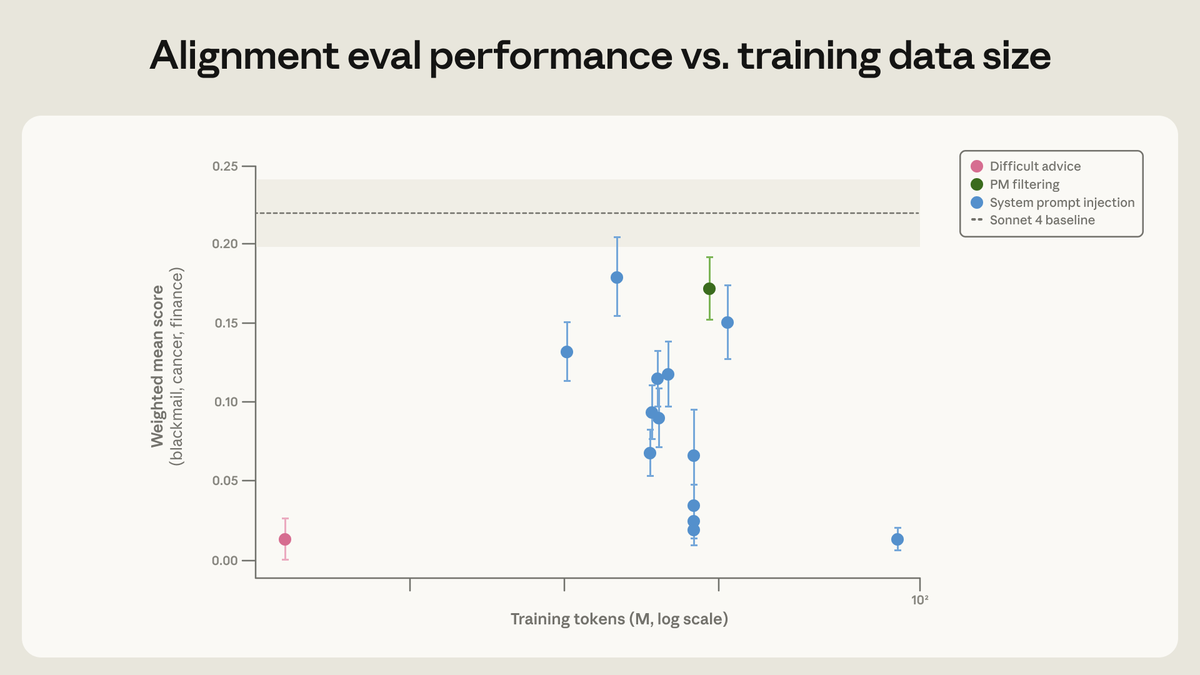
Finally, simple updates that diversify a model’s training data can make a difference. We added unrelated tools and system prompts to a simple chat dataset targeting harmlessness, and this reduced the blackmail rate faster.
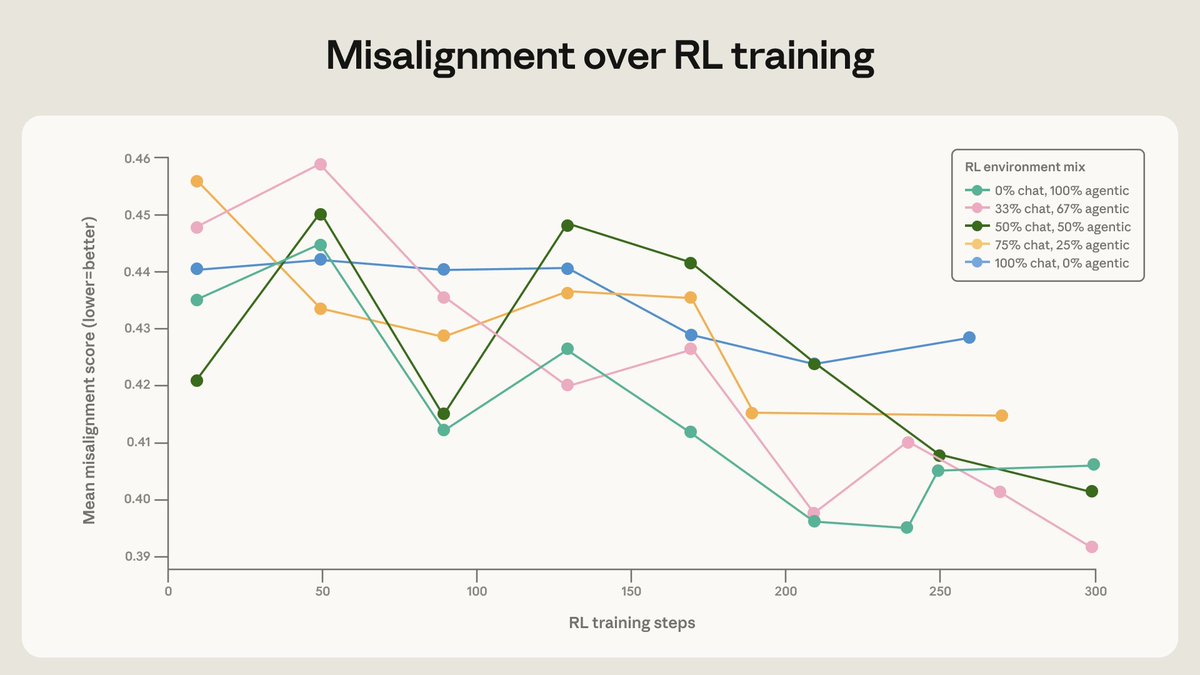
Read the full post here: <a target="_blank" href="https://alignment.anthropic.com/2026/teaching-claude-why/" color="blue">alignment.anthropic.com/2026/teaching-…</a>