Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

🧵 MemPalace claims to be "the highest-scoring AI memory system ever benchmarked" I cloned it. Installed it. Ran the benchmarks. Read every line of code. Here's what's actually inside. A thread.

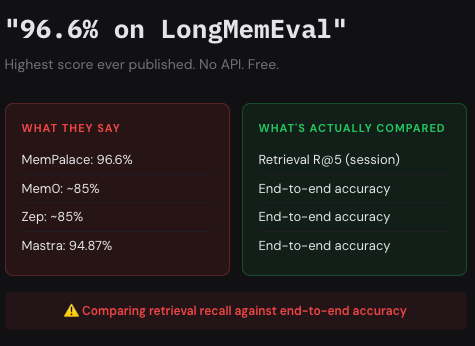
1/ The headline claim: 96.6% on LongMemEval, beating Mem0 (~85%), Zep (~85%), Mastra (94.87%) Problem: MemPalace reports retrieval Recall@5. The others report end-to-end QA accuracy. Those numbers measure completely different things. You can't put them in the same table.
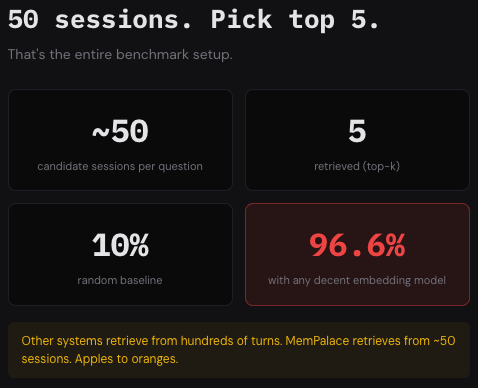
2/ LongMemEval_s has ~50 sessions per question. MemPalace retrieves at session granularity with n_results=50 (all of them). So R@5 asks: "is the right session in your top 5 out of ~50?" Random baseline: 10% Any decent embedding model: 95%+ This is a trivially easy retrieval setting.
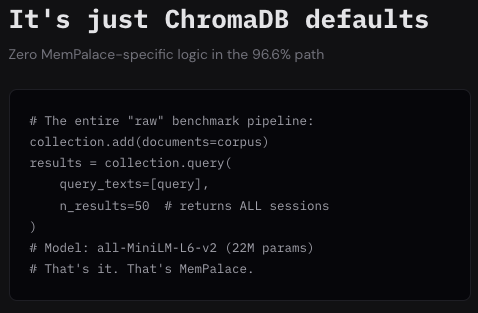
3/ The 96.6% path uses zero MemPalace-specific logic. It's ChromaDB's default collection.add() + collection.query() with all-MiniLM-L6-v2 (22M params). The "palace architecture" (wings/rooms) isn't used in the raw benchmark at all. The score is a ChromaDB benchmark, not a MemPalace benchmark.
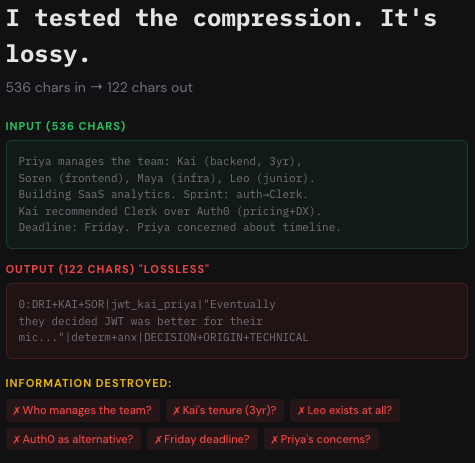
4/ They call AAAK "30x lossless compression." I tested it. 536 chars in, 122 chars out (4.4x, not 30x). Lost: who manages the team, tenure info, a team member's existence, the deadline, all reasoning context. That's the exact opposite of lossless.
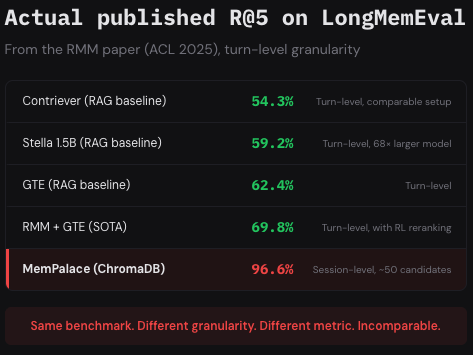
5/ Published R@5 on LongMemEval at turn-level (ACL 2025 RMM paper): Contriever: 54.3% Stella 1.5B: 59.2% GTE: 62.4% RMM+GTE: 69.8% MemPalace's 96.6% uses session-level with ~50 candidates. Same benchmark name. Completely different difficulty. Incomparable numbers.