Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

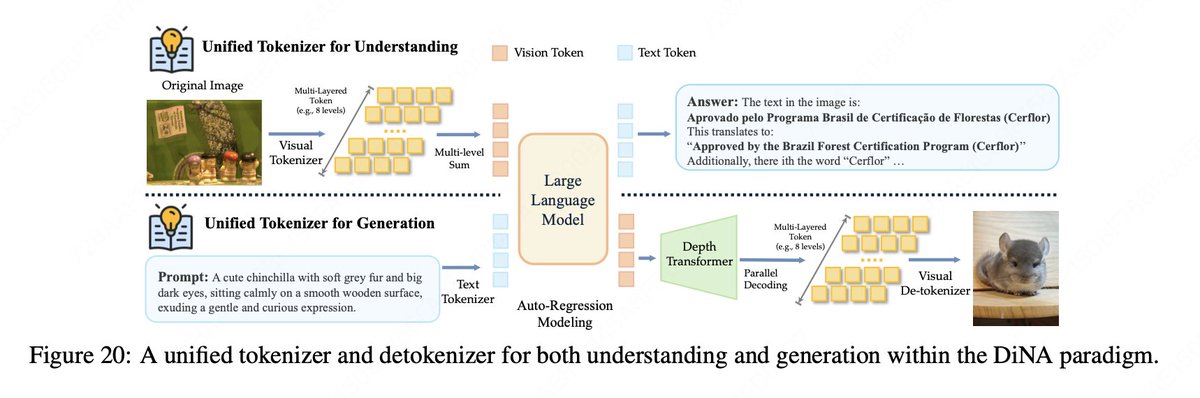
🔥 Introducing LongCat-Next: A Discrete Native Autoregressive Multimodal Model LongCat-Next integrates language, vision, and audio into a unified discrete autoregressive model, extending Next-Token Prediction to native multimodality and delivering industrial-strength performance across diverse multimodal domains. 🔑 Key Features: ⚙️ 68.5B total params, 3B active, LongCat-Flash-Lite MoE backbone, excels at seeing, painting, and speaking in a unified discrete autoregressive framework. 🧩 Discrete Native Autoregression Paradigm (DiNA): We introduce DiNA, a unified paradigm that extends next-token prediction from language to native multimodality, internalizing diverse modalities into a shared discrete token space. 🌐 Discrete Native Any‑Resolution Vision Transformer (dNaViT): A unified visual tokenizer and de-tokenizer that encodes images into discrete IDs with semantic completeness, enabling both understanding and generation at any resolution. This approach overcomes the performance ceiling of discrete vision modeling in understanding tasks and enables to reconcile the conflict between understanding and generation. 👀 Visual Understanding: Fine-grained visual perception for complex tasks such as OCR, Charts, GUI interpretation, and document analysis, and advanced STEM reasoning capabilities. 🎨 Visual Generation: Generation under 28x compression ratio at arbitary resolution with competitive performance, especially in text rendering. 🎧 Speech: Strong audio comprehension capabilities, low-latency and intelligent audio-to-audio interaction, as well as speech synthesis featuring customizable voice cloning. 📄 Paper: <a target="_blank" href="https://github.com/meituan-longcat/LongCat-Next/blob/main/tech_report.pdf" color="blue">github.com/meituan-longca…</a> 🔗 GitHub: <a target="_blank" href="https://github.com/meituan-longcat/LongCat-Next" color="blue">github.com/meituan-longca…</a> 😊 HuggingFace: <a target="_blank" href="https://huggingface.co/meituan-longcat/LongCat-Next" color="blue">huggingface.co/meituan-longca…</a> 💻 demo: <a target="_blank" href="https://longcat.chat/longcat-next" color="blue">longcat.chat/longcat-next</a> 📖 blog: <a target="_blank" href="https://longcat.chat/longcat-next/intro" color="blue">longcat.chat/longcat-next/i…</a>