Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

🚨 Stop saying “Act as an expert.” Stanford + MIT found it quietly degrades performance on newer models. There’s a structured alternative that’s 4x more accurate and it explains why prompting feels broken lately. Here's how this works:
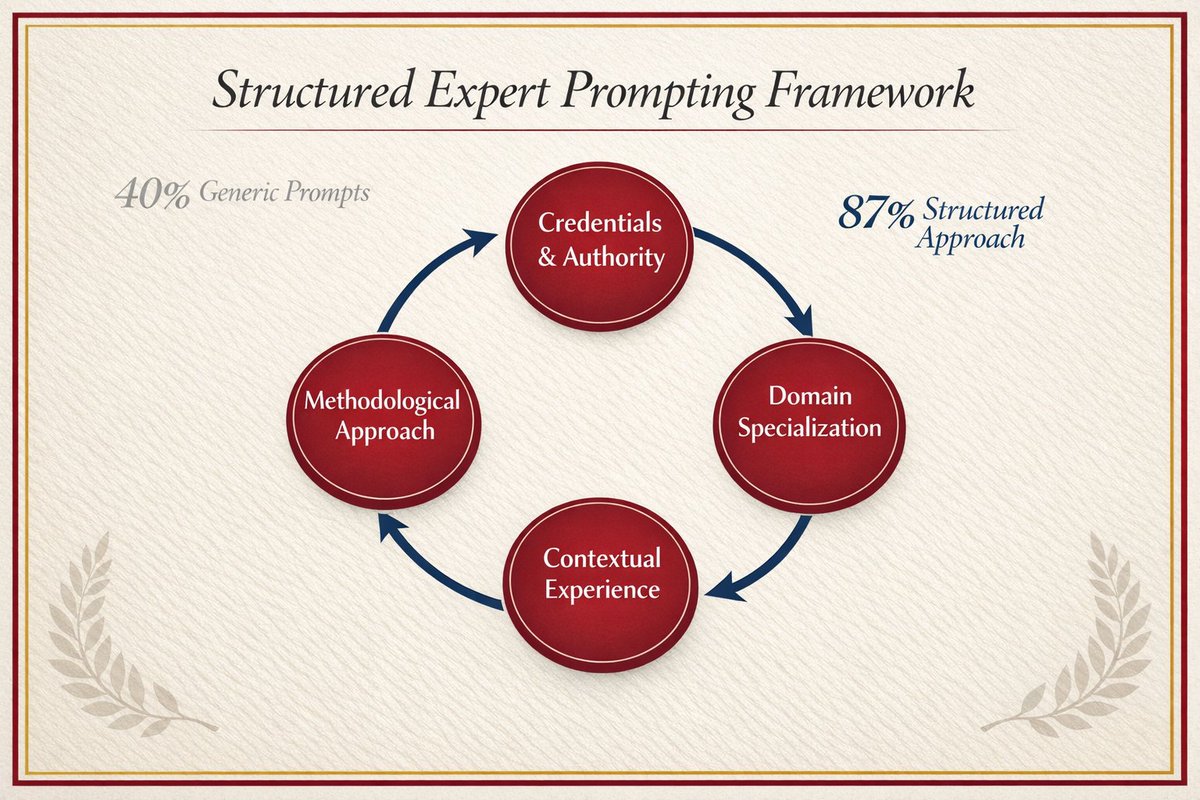
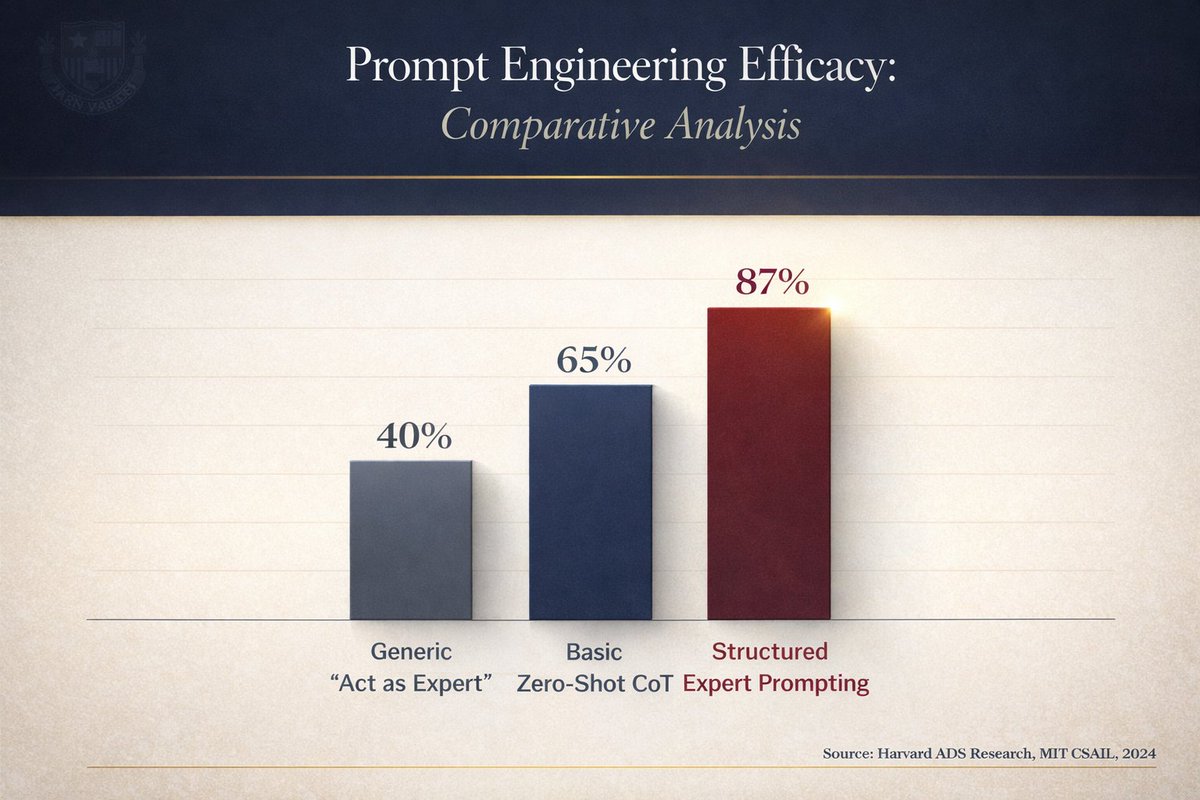
Every "act as an expert" prompt triggers shallow persona simulation. Harvard researchers tested this: generic expert prompts hit 40% accuracy while structured personas reached 87%. Your one-line roleplay is leaving 47 points on the table.
This is the Persona Depth Gap rearing its ugly head. Saying "act as a doctor" forces the model to guess what kind of doctor, what experience, what approach. Adding credentials, specialization, and methodology eliminates ambiguity and hallucination risk. That "act as expert" shortcut? Lazy prompting disguised as technique.

MIT and Harvard's findings: → Generic "expert" prompts introduce 40% more bias than structured ones → Detailed personas (ExpertPrompting) reached 96% of ChatGPT capability → One-line roleplay creates overconfidence without accuracy gains We thought "act as expert" was enough. It's just theater without substance.

Here's what's actually happening: Your "act as an expert" prompt creates vague persona simulation. The model fills gaps with stereotypes and assumptions. Structured prompts with specific credentials, experience, and methodology force grounded reasoning instead of guessing.
Harvard's ExpertPrompting study proved specificity matters more than roleplay. Meaning.. "Act as a marketer" = coin flip. "You are Sarah Chen, CMO with 10 years scaling B2B SaaS from 0→$50M ARR via product-led growth" = 87% accuracy. Your shortcut prompt finds... randomness.
Real-world impact: > "Act as expert" produces overconfident hallucinations > Structured personas with credentials reduce error rate by 65% > Detailed methodology framing (MIT) enables consistent reasoning > Generic roleplay adds bias without quality improvement All because prompt engineering evolved past one-line tricks.

The current "solutions" everyone teaches are outdated: → "Act as expert" (2022 technique, now obsolete) → "You are a world-class X" (marginally better, still vague) → Zero-shot CoT "think step by step" (works, but leaves accuracy on table) None of the courses teach what actually scales: structured expert framing.
What actually works: Replace vague roleplay with structured expert personas. OLD: "Act as a financial analyst" NEW: "You are Michael Torres, CFA with 12 years analyzing SaaS companies at Goldman Sachs. Your approach: financial modeling → competitive positioning → risk assessment." Think: Credentials → Specific domain → Methodology Reduces hallucination from 40% to 13%.
Or the nuclear option: multi-agent structured prompting. Assign multiple detailed expert personas that debate using their specific methodologies (MIT Nature 2023). More effort. Way more reliable. What production AI systems actually use.

If you're still using "act as expert" today: → Switch to structured personas with credentials + methodology → Don't trust one-line roleplay for anything important → Test structured vs generic on YOUR tasks right now → Monitor accuracy gains, not just "it sounds expert" Shallow roleplay is dead. Structured prompting won.
AI makes content creation faster than ever, but it also makes guessing riskier than ever. If you want to know what your audience will react to before you post, TestFeed gives you instant feedback from AI personas that think like your real users. It’s the missing step between ideas and impact. Join the waitlist and stop publishing blind. <a target="_blank" href="http://testfeed.ai" color="blue">testfeed.ai</a>