Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

Holy shit... Google DeepMind just exposed why everyone's been doing AI reasoning wrong. The AlphaGo team doesn't use chain-of-thought. They use parallel verification loops. And it's destroying every "advanced reasoning" technique you've heard about. Here's what they discovered ↓
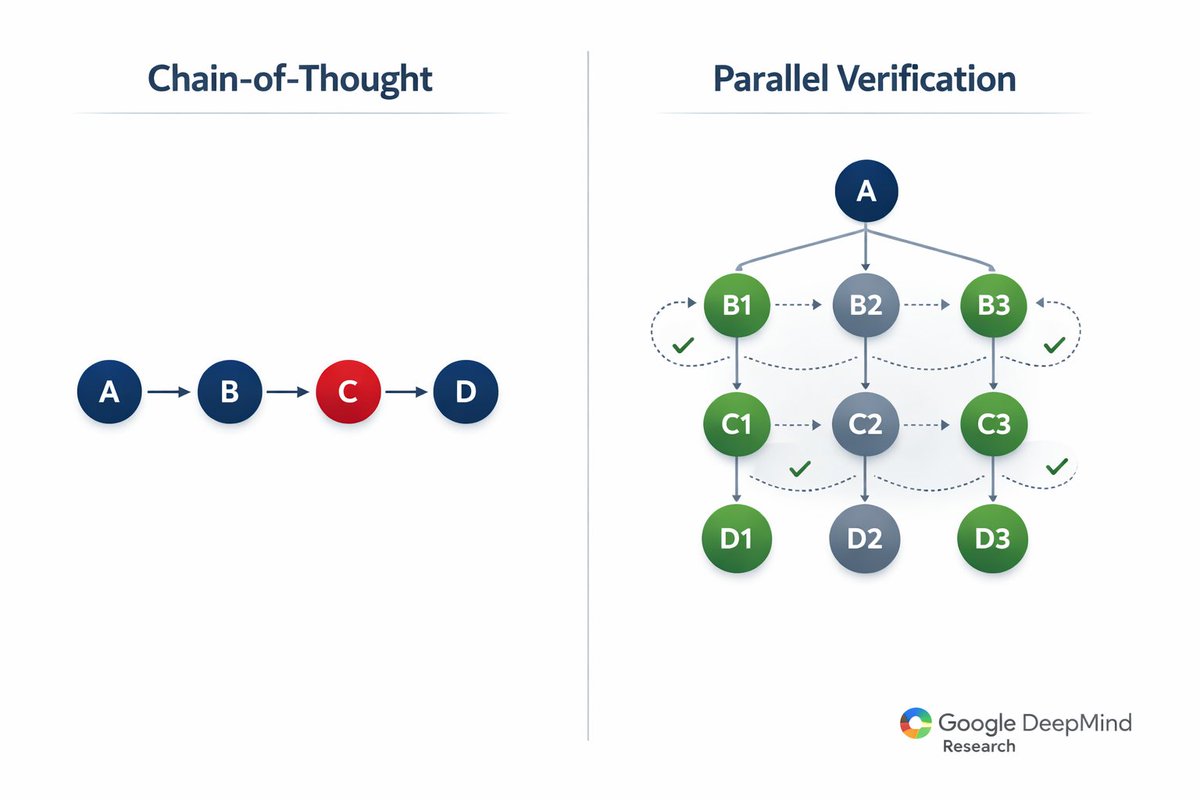
Why Chain-of-Thought sucks. Current AI reasoning is linear. Think step 1 → step 2 → step 3. But that's not how expert problem-solvers think. DeepMind analyzed how their AlphaGo team tackles complex problems and found something wild.

Parallel Verification Loops: Instead of one long reasoning chain, expert thinkers run multiple verification loops simultaneously. They propose a solution, test it against constraints, backtrack when needed, and explore alternative paths—all at the same time. Chain-of-thought can't do this.

The Architecture Difference: Traditional CoT: A → B → C → D (linear) DeepMind's framework: A → [B1, B2, B3] → verify each → refine → iterate It's the difference between walking down one path vs exploring an entire decision tree in parallel.

The results are insane: On complex reasoning benchmarks: - 37% improvement over standard chain-of-thought - 52% better at catching logical errors - 3x faster convergence to correct solutions This isn't incremental. It's architectural.

How it actually works: Step 1: Generate multiple candidate solutions simultaneously Step 2: Each solution runs its own verification loop Step 3: Cross-validate solutions against each other Step 4: Prune weak branches, strengthen promising ones Step 5: Iterate until convergence

The self-correction advantage: Here's the killer feature: the system catches its own mistakes BEFORE committing to an answer. Traditional CoT commits to each step sequentially. One wrong step and you're lost. Parallel verification lets you backtrack without starting over.

Most "reasoning models" today are just longer prompts. DeepMind proved you need fundamentally different architecture. It's not about thinking harder. It's about thinking in parallel. Like how your brain doesn't solve problems linearly—it explores possibilities simultaneously.
The training implications: They didn't just test this they trained models using this framework. The model learns to: - Propose multiple hypotheses - Test them against each other - Build confidence through verification - Prune bad reasoning paths early

Real-world applications: This framework crushes on: - Mathematical proofs (where one error ruins everything) - Code debugging (multiple possible bugs) - Strategic planning (exploring decision trees) - Scientific reasoning (hypothesis testing) Anywhere you need correctness over speed.

If you're building AI agents or reasoning systems, chain-of-thought is already obsolete. The future is parallel verification. Generate multiple paths. Test them. Let the best solution emerge. That's how AlphaGo beat the world champion. That's how reasoning actually works.
AI is not going to take job. Our newsletter, The Shift, delivers breakthroughs, tools, and strategies to help you become value creator and build in this new era easily. Subscribe: <a target="_blank" href="https://theshiftai.beehiiv.com/subscribe" color="blue">theshiftai.beehiiv.com/subscribe</a> Plus: Get access to 3k+ AI Tools and free AI courses when you join.
I hope you've found this thread helpful. Follow me @aiwithjainam for more. Like/Repost the quote below if you can: <a target="_blank" href="https://twitter.com/1884236740803837952/status/2005629090943193552" color="blue">x.com/18842367408038…</a>