Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

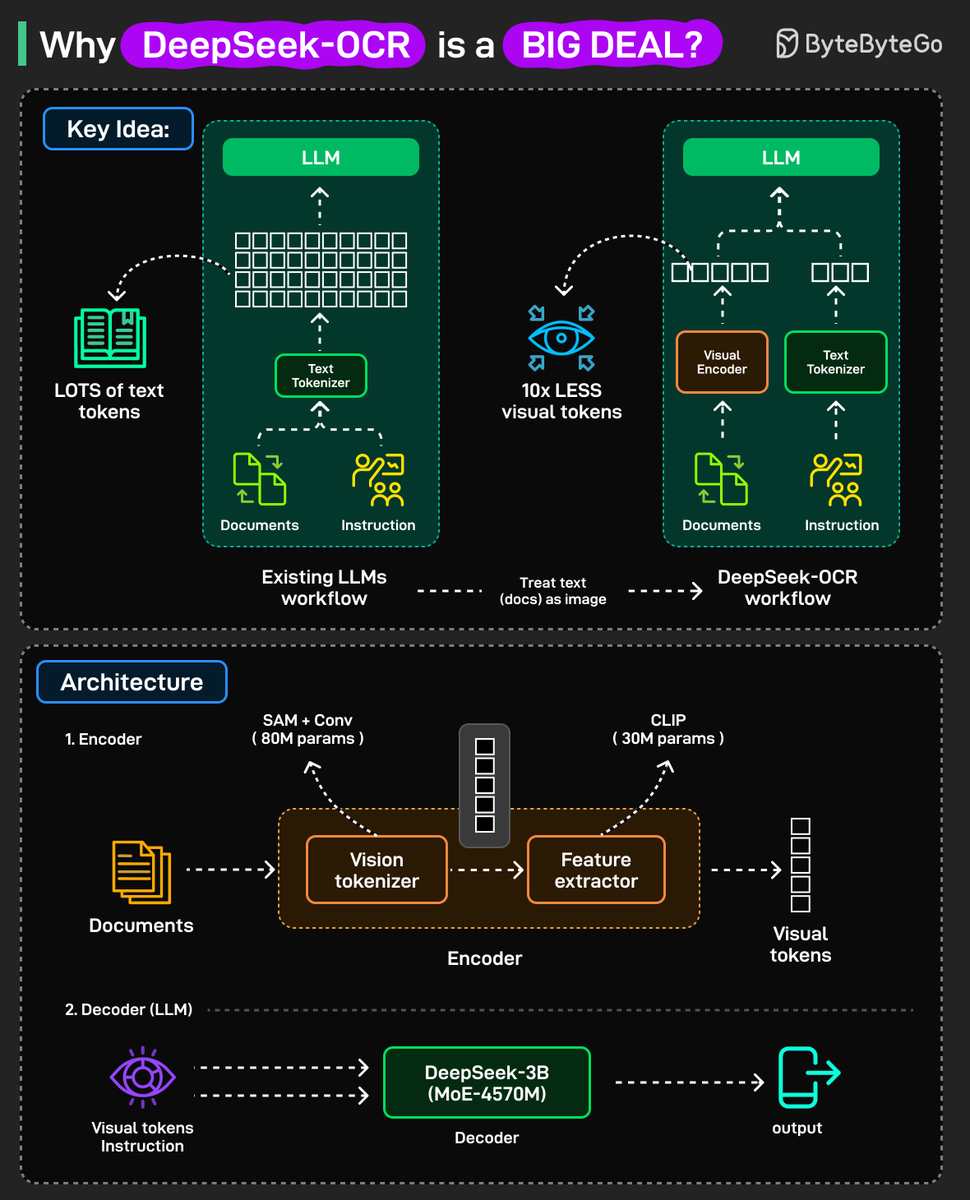
Why is DeepSeek-OCR such a BIG DEAL? Existing LLMs struggle with long inputs because they can only handle a fixed number of tokens, known as the context window, and attention cost grows quickly as inputs get longer. DeepSeek-OCR takes a new approach. Instead of sending long context directly to an LLM, it turns it into an image, compresses that image into visual tokens, and then passes those tokens to the LLM. Fewer tokens lead to lower computational cost from attention and a larger effective context window. This makes chatbots and document models more capable and efficient. How is DeepSeek-OCR built? The system has two main parts: 1. Encoder: It processes an image of text, extracts the visual features, and compresses them into a small number of vision tokens. 2. Decoder: A Mixture of Experts language model that reads those tokens and generate text one token at a time, similar to a standard decoder-only transformer. When to use it? DeepSeek-OCR shows that text can be efficiently compressed using visual representations. It is especially useful for handling very long documents that exceed standard context limits. You can use it for context compression, standard OCR tasks, or deep parsing, such as converting tables and complex layouts into text. Over to you: What do you think about using visual tokens to handle long-context problems in LLMs? Could this become the next standard for large models? -- We just launched Become an AI Engineer | Learn by Doing: Cohort 2. If you missed Cohort 1, now’s your chance to join us for Cohort 2. Check it out here: <a target="_blank" href="https://bit.ly/3LdaWuw" color="blue">bit.ly/3LdaWuw</a> #AI #AIEngineer #MachineLearning .