Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

Everyone says “LLMs are black boxes.” This paper "How Do LLMs Use Their Depth?” just opened one and showed how intelligence forms layer by layer. They follow a “Guess → Refine” strategy: • Early layers make statistical guesses using frequent tokens (“the”, “of”, “and”) • Middle layers pull in context to test those guesses • Later layers refine them into precise, context-aware predictions Across GPT-2-XL, Llama-2-7B, Llama-3-8B, and Pythia-6.9B, ~80% of early guesses get replaced before the final layer. Even cooler: models use depth dynamically easy tasks (like punctuation or determiners) finish early, while hard ones (like fact recall or reasoning) go deeper. In short: LLMs aren’t just deep networks. They’re layered thinkers early guessers, late reasoners. Paper: arxiv. org/abs/2510.18871

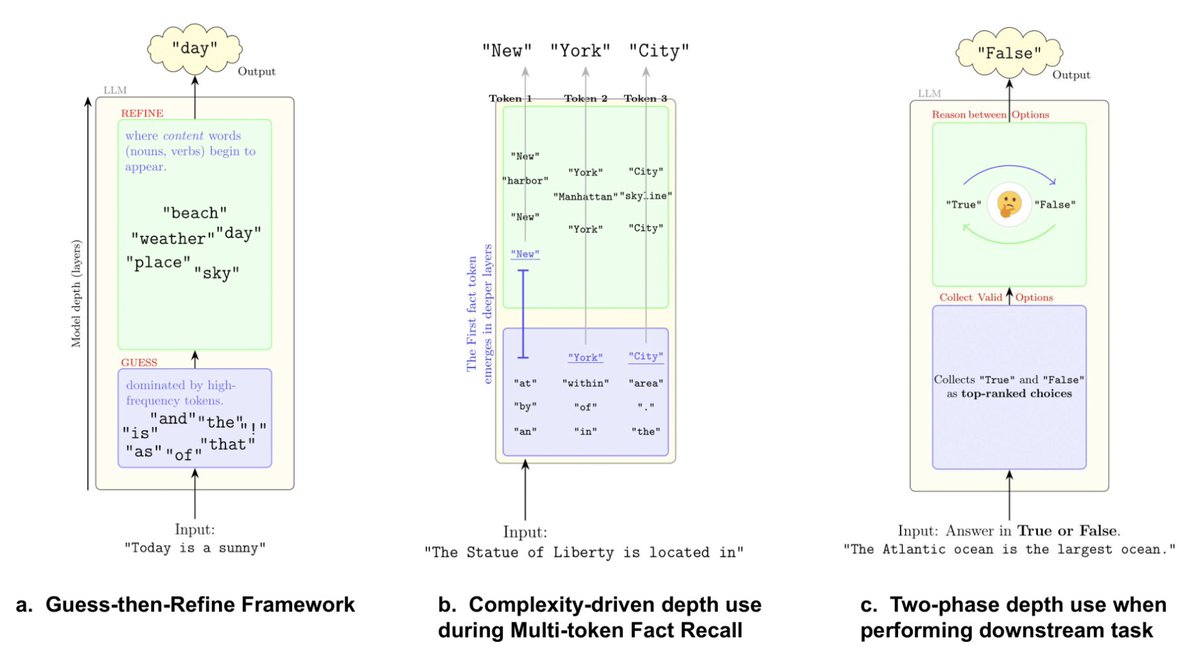
This single diagram captures the paper’s entire idea. LLMs act like early guessers and late reasoners. Early layers throw out high-frequency guesses (“the”, “is”, “and”). Later layers refine them into meaningful, context-aware answers. Think intuition → reasoning → conclusion.
Wild stat: In the first layer of Pythia-6.9B, 75% of top predictions are just the 10 most common words. By the final layer, that number drops to ~30%. Early layers rely purely on word frequency they’re guessing from statistical priors before context even forms.

Here’s the proof that early guesses aren’t permanent. ~80% of first-layer predictions get overturned by the end. Even frequent tokens (“the”, “and”) are refined 70%+ of the time. The model doesn’t decide once — it debates itself layer by layer.

LLMs literally use depth based on word type. Function words (DET, ADP, PUNCT) stabilize around layer 5, while content-heavy words (NOUN, VERB, ADJ) take 15–20 layers. Easy = shallow, hard = deep.

Multi-token answers like “New York City” expose how reasoning compounds. The first token (“New”) needs 25+ layers of compute. Later tokens (“York”, “City”) appear much earlier (~12–20). That’s depth scaling with complexity in real time.

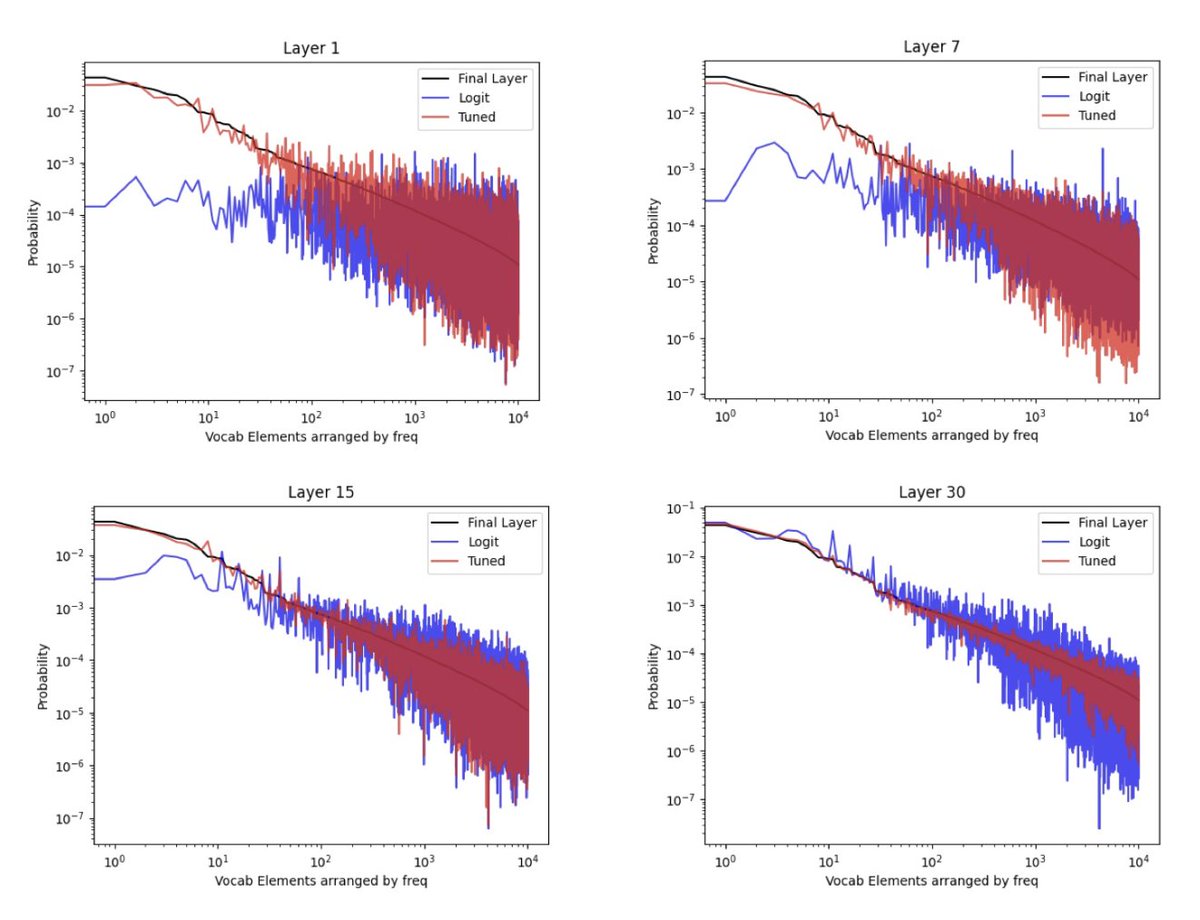
To prove these insights aren’t probe artifacts, they compared TunedLens vs LogitLens. Only TunedLens matched the final-layer probability distribution. Meaning: the “guess → refine” behavior is real, not a decoding illusion.
They even masked high-frequency words (“the”) 1000× less during training. Still appeared as early top predictions. That means early layers genuinely encode frequency priors, not probe bias.

LLMs don’t think in one pass. They guess, test, refine, and decide across their depth. Each layer isn’t just computation it’s a thought step. We’re literally watching models reason in slow motion. <a target="_blank" href="https://github.com/akshat57/how-do-llms-use-their-depth" color="blue">github.com/akshat57/how-d…</a>