Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

One of the best paper of the recent week. The big takeaway: scaling up model size doesn’t just make models smarter in terms of knowledge, it makes them last longer on multi-step tasks, which is what really matters for agents. Shows that small models can usually do one step perfectly, but when you ask them to keep going for many steps, they fall apart quickly. Even if they never miss on the first step, their accuracy drops fast as the task gets longer. Large models, on the other hand, stay reliable across many more steps, even though the basic task itself doesn’t require extra knowledge or reasoning. The paper says this is not because big models "know more," but because they are better at consistently executing without drifting into errors The paper names a failure mode called self-conditioning, where seeing earlier mistakes causes more mistakes, and they show that with thinking steps GPT-5 runs 1000+ steps in one go while others are far lower. 🧵 Read on 👇

🧵2/n. 🧠 The idea The work separates planning from execution, then shows that even when the plan and the needed knowledge are handed to the model, reliability drops as the task gets longer, which makes small accuracy gains suddenly matter a lot.

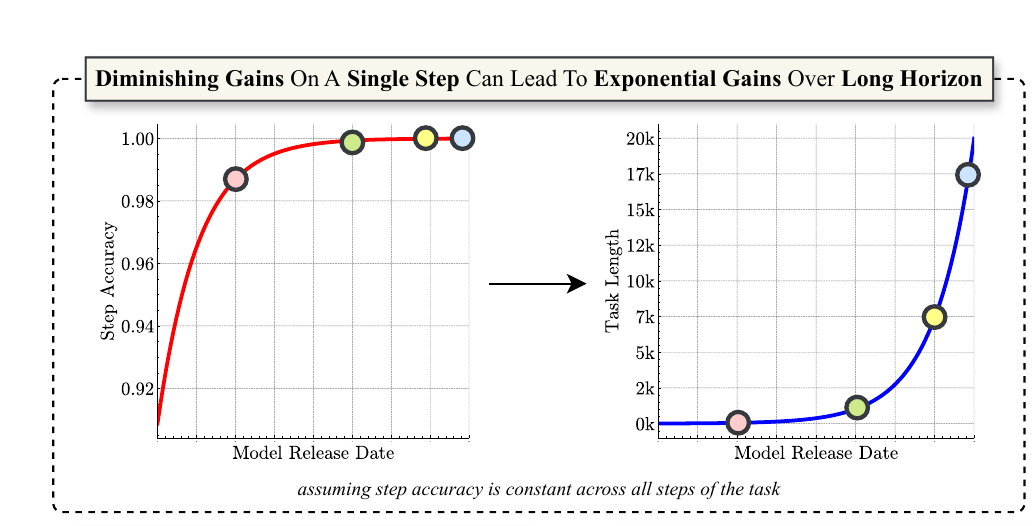
🧵3/n. even a tiny accuracy boost at the single-step level leads to exponential growth in how long a model can reliably execute a full task. This is why scaling up models is still worth it, even if short benchmarks look like progress is stalling. On the left, you see that step accuracy (how often the model gets each small move right) is almost flat, barely improving with newer models. That looks like diminishing returns, because each release is only slightly better at a single step. But on the right, when you extend that tiny step improvement across many steps in a row, the gains explode. Task length (how long a model can keep going without failing) jumps from almost nothing to thousands of steps.
🧵4/n. This chart is showing why models get worse the longer they run. The green line is what you’d expect: if a model makes small, random errors, then accuracy should stay flat over time. But the red line is what actually happens: accuracy keeps dropping as the task gets longer. The reason is called self-conditioning. Once the model makes a mistake, that mistake is fed back into its own history. Next time it looks at its past answers, it sees the wrong one, and that makes it even more likely to mess up again. The examples at the bottom show this: if the history is clean, the model keeps answering correctly. If the history already has errors, it spirals into worse mistakes. So the point is: LLMs don’t just fail because of random errors — they fail because their own mistakes poison the context and cause more mistakes later.

🧵5/n. This chart is showing how bigger models behave when earlier errors are present in their history. The green bars are when the context is clean, with 0% errors. In that case, larger models (like 14B and 32B) maintain much higher accuracy at step 100 compared to smaller ones. So, scaling clearly helps if everything is going smoothly. The pink bars are when half of the history already has errors. Here, accuracy drops sharply, and the bigger the model, the worse the collapse. The 32B model goes from the best in the clean case to much lower when errors are present. The message is: larger models are more powerful at executing long tasks when history is clean, but they are also more vulnerable to self-conditioning, meaning once they see their own earlier mistakes, they spiral down harder.

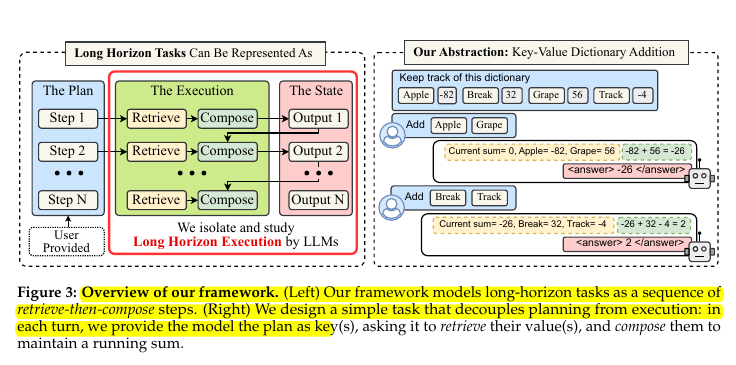
🧵6/n. how the authors tested execution in a very controlled way. The authors turn long tasks into a simple loop where each turn says which keys to read from a dictionary and asks the model to update a running sum, so any failure is about execution, not missing knowledge or planning. the paper isolates execution by stripping away planning and knowledge, and tests whether models can keep a simple running sum correct across many turns. On the left, they explain that a long task can be broken into repeated steps: first retrieve the right piece of information, then compose it into the running result, and finally store the updated state. The planning part (what steps to do) is already given to the model, so the test only measures whether the model can keep executing correctly across many steps. On the right, they show the toy task they used. It’s basically a dictionary where each word has a number attached. The model is told which keys to pick (like “Apple” and “Grape”), it retrieves their numbers, and then adds them into the running total. This setup ensures the task doesn’t depend on external knowledge or creative planning, only on correct execution turn after turn.
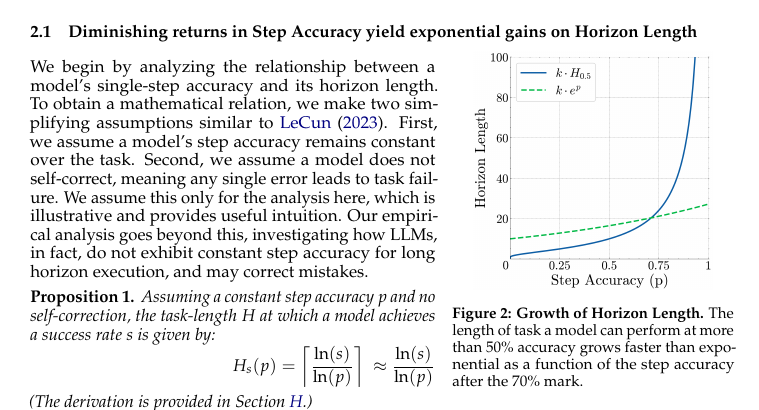
🧵7/n. 📈 Why small gains explode the horizon Under a simple constant‑accuracy model without self‑correction, once single‑step accuracy passes about 70%, a tiny bump yields a faster‑than‑exponential jump in the task length that stays above a 50% success target, so diminishing returns on short tasks hide massive real‑world gains on long ones.
🧵8/n. 🧮 What scaling buys even without new knowledge Larger models keep the running sum correct across many more turns even though small models already have 100% single‑step accuracy, which says the benefit of scale here is more reliable execution over time, not better facts.

🧵9/n. 🔁 The self‑conditioning effect As soon as the context shows earlier mistakes, the model becomes more likely to err again, so per‑turn accuracy keeps drifting down with length, and this is separate from long‑context limits and is not fixed by just using a bigger model.
🧵10/n. Thinking fixes the drift When models are set to think with sequential test‑time compute, accuracy at a fixed late turn stays stable even if the history is full of wrong answers, which shows that deliberate reasoning steps break the negative feedback loop.
🧵11/n. 🚀 Single‑turn capacity, numbers that matter Without chain‑of‑thought, even very large instruction‑tuned models struggle to chain 2 steps in one turn, but with thinking, GPT‑5 executes 1000+ steps, Claude 4 Sonnet is about 432, Grok‑4 is 384, and Gemini 2.5 Pro and DeepSeek R1 hover near 120.
🧵12/n. 🧱 Parallel sampling does not replace thinking Running many parallel samples and voting gives only small gains compared to sequential reasoning, so for long‑horizon execution the key is sequential test‑time compute, not more parallel guesses.
🧵13/n. 🧽 Practical mitigation by trimming history A sliding window that drops old turns improves reliability by hiding accumulated errors from the model, which reduces self‑conditioning in simple Markovian setups like this task.
🧵14/n. 🧾 Where the errors actually come from Lookup and addition alone stay near perfect for a long time, but combining them with reliable state tracking makes errors grow, so the weak spot is the ongoing management of state while composing small operations.
🧵15/n. 🛠️ What to do as an agent builder Measure horizon length directly, use thinking for multi‑step execution, prefer sequential compute over pure parallel sampling, and manage context to avoid feeding the model its own earlier mistakes.
Paper – <a target="_blank" href="https://arxiv.org/abs/2509.09677" color="blue">arxiv.org/abs/2509.09677</a> Paper Title: "The Illusion of Diminishing Returns: Measuring Long Horizon Execution in LLMs"