Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

Has GPT-5 Achieved Spatial Intelligence? GPT-5 sets SoTA but not human‑level spatial intelligence. My notes below:

This report introduces a unified view of spatial intelligence (SI) for multimodal models and evaluates GPT‑5 and strong baselines across eight fresh SI benchmarks. GPT‑5 leads overall but is still short of human skill, especially on mentally reconstructing shapes, changing viewpoints, and deformation/assembly tasks.

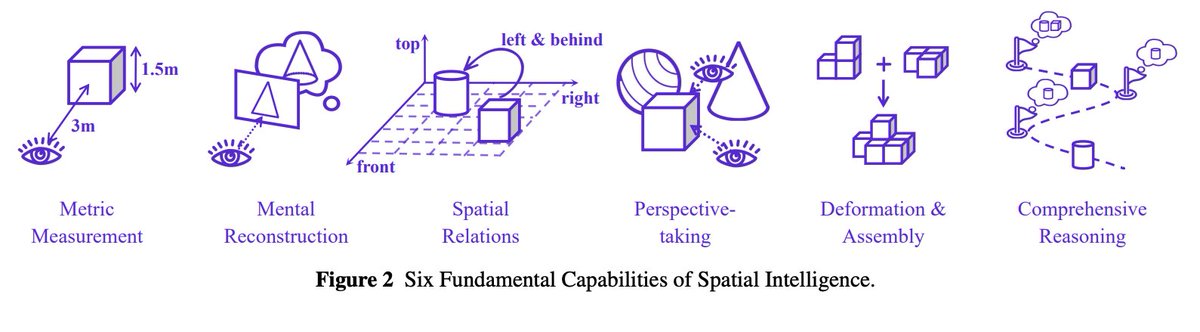
Unified SI schema and fair eval setup The authors consolidate prior work into six core SI capabilities (Metric Measurement, Mental Reconstruction, Spatial Relations, Perspective‑taking, Deformation & Assembly, Comprehensive Reasoning) and standardize prompts, answer extraction, and metrics to reduce evaluation variance across datasets.
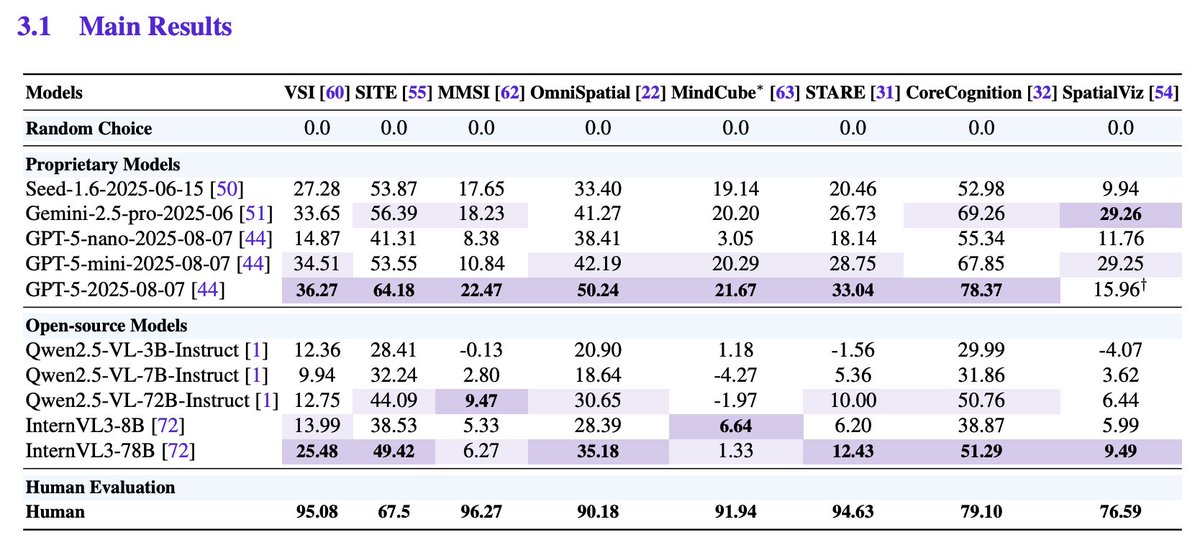
Broad benchmark sweep, heavy compute Eight recent benchmarks (e.g., VSI‑Bench, SITE, MMSI, OmniSpatial, MindCube, STARE, CoreCognition, SpatialViz) are used with unified protocols; results reflect >1B tokens of evaluation traffic.

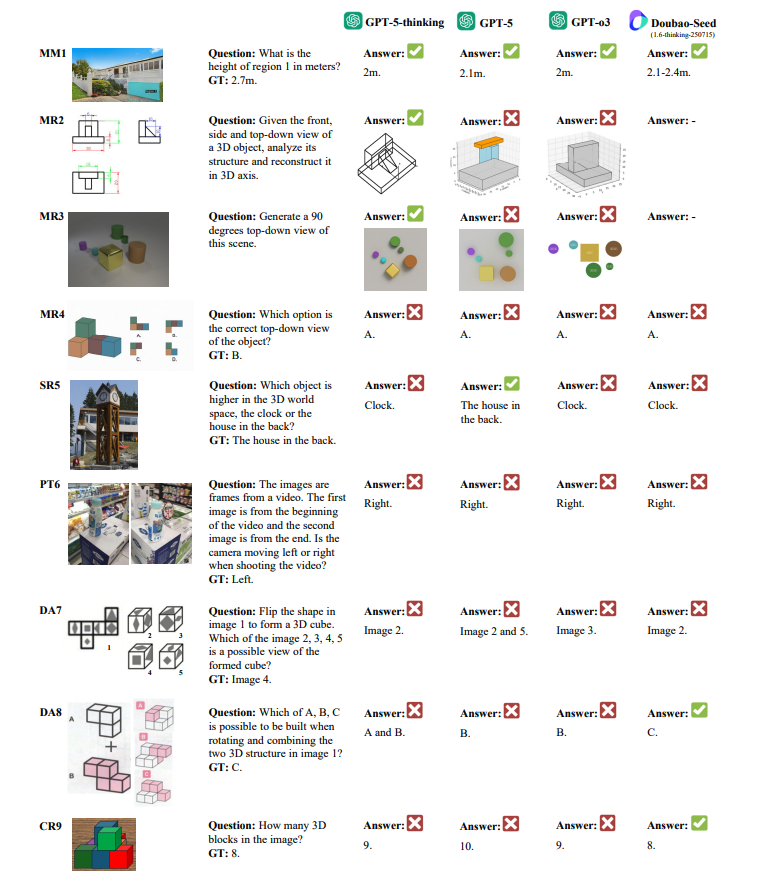
GPT‑5 sets SOTA but not human‑level SI. GPT‑5 tops aggregate scores and sometimes reaches human parity on Metric Measurement and Spatial Relations, yet shows significant gaps on Mental Reconstruction, Perspective‑taking, Deformation & Assembly, and multi‑stage Comprehensive Reasoning.
Thinking Modes "In High mode, 28 questions exceeded the 15-minute time limit or hit token limit, and were counted as incorrect, resulting in an accuracy of 52.54%; excluding these cases yields 68.89%." High could lead to better results, but I understand the token limit issues.

Hard SI narrows the closed vs open gap While proprietary models win on average, their advantage evaporates on the hardest SI categories; several open‑source systems perform similarly, far from human ability on MR/PT/DA/CR. Non‑SI portions (e.g., CoreCognition’s Formal Operation) can reach near‑human levels.
Qualitative analysis exposes failure modes Case studies show prompt sensitivity for novel‑view generation, blind spots with perspective effects and size constancy, persistent failures on paper‑folding/assembly, and difficulty inferring occluded objects during counting. Paper: <a target="_blank" href="https://arxiv.org/abs/2508.13142" color="blue">arxiv.org/abs/2508.13142</a>