Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

what are large language models actually doing? i read the 2025 textbook "Foundations of Large Language Models" by tong xiao and jingbo zhu and for the first time, i truly understood how they work. here’s everything you need to know about llms in 3 minutes↓

to understand LLMs, you first need to know the idea of pre-training. instead of teaching a model to solve one task with labeled data (like classifying tweets), we train it on massive unlabeled text and let it "figure out" language patterns by itself. this is called self-supervised learning.
there are 3 pre-training strategies: → unsupervised: models learn patterns without any labels → supervised: models learn from labeled tasks → self-supervised: models generate their own labels from unlabeled data (e.g., predicting masked words) LLMs use the third one. it's the most powerful.
self-supervised pretraining works like this: take a sentence like “the early bird catches the worm.” mask some words: “the [MASK] bird catches the [MASK]” ask the model to fill in the blanks. no labels needed the text itself is the supervision.

this idea leads to three main architecture types: → encoder-only (BERT): reads and understands text → decoder-only (GPT): generates the next word → encoder-decoder (T5, BART): reads input, generates output each has strengths. for example: • GPT is great at generation • BERT is great at classification • T5 can do both via a "text-to-text" framework
let’s dive into each. decoder-only (GPT-style): trained to predict the next token given previous ones: “the cat sat on the [MASK]” → “mat” this is called causal language modeling. loss is calculated using cross-entropy over predicted vs. actual next words.
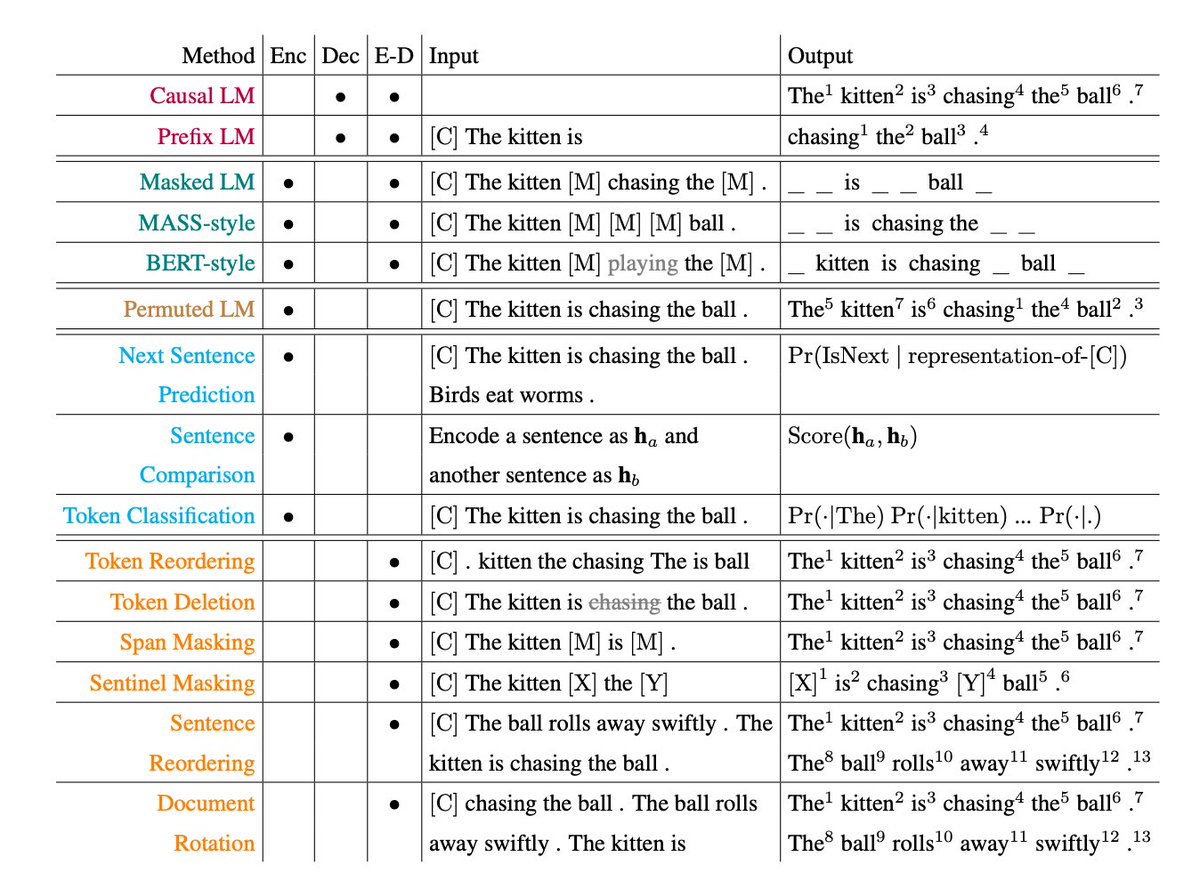
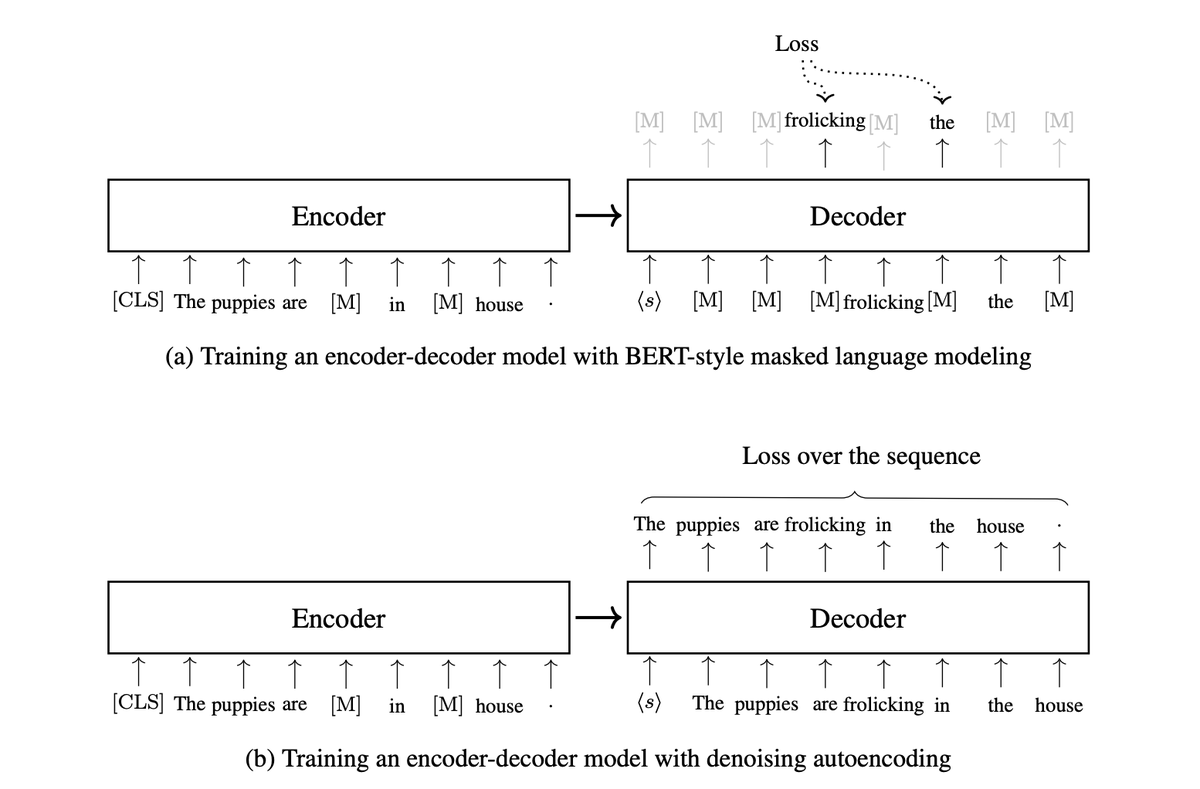
encoder-only (BERT-style): looks at the full sentence at once, masks random tokens, and tries to reconstruct them. this is masked language modeling, and it allows bidirectional context the model uses both left and right of the [MASK]. better for tasks like sentence classification.
example: original: "the early bird catches the worm" masked: "the [MASK] bird catches the [MASK]" the model learns to predict "early" and "worm" using all surrounding context. it's like learning to read by guessing missing words in a book.
encoder-decoder (T5-style): treats every NLP task as text-to-text. examples: “translate English to German: hello” → “hallo” “classify sentiment: i hate this” → “negative” the same model can be used for translation, summarization, QA, etc.
so, what happens after pre-training? we can either: → fine-tune: train the model further on labeled task-specific data → prompt: write smart inputs to steer the model prompting is the reason LLMs feel magical. let's talk about that next.
prompting is just carefully crafting the input to make the model behave how you want. example: "i love this movie. sentiment:" the model will likely complete: “positive”. add a few examples before the input, and the model learns the pattern. this is in-context learning.
prompting can go deep. strategies include: • chain of thought: "let's think step by step…" • problem decomposition: break big problems into smaller ones • self-refinement: ask the model to critique and revise its own output • RAG: let the model look things up externally

this is all possible because of the way these models are trained: predict the next word over and over until they internalize language structure, reasoning patterns, and world knowledge. it's not magic. it's scale.
but LLMs aren’t trained just to be smart — they need to be aligned with human values. how? → supervised fine-tuning (SFT): teach the model on human-written responses → RLHF (reinforcement learning from human feedback): train a reward model to prefer good outputs this is how ChatGPT was aligned.
alignment is hard. newer methods like Direct Preference Optimization (DPO) avoid the instability of RL and are becoming more popular. the goal is the same: steer models toward helpful, harmless, honest responses.
finally, inference matters. how do you actually run these massive models efficiently? → use smart decoding (top-k, nucleus sampling) → cache previous results → batch multiple requests → scale context with better memory and position interpolation this is how you get fast, low-latency responses.
in short: LLMs work because they: 1. learn from massive text via self-supervision 2. use Transformers to model token sequences 3. can be prompted/fine-tuned for any task 4. are aligned with human preferences 5. are optimized for fast inference they're general-purpose text reasoning machines.
this was based on the brilliant textbook: "Foundations of Large Language Models" by Tong Xiao and Jingbo Zhu (NiuTrans Research Lab) arxiv: <a target="_blank" href="https://arxiv.org/abs/2501.09223v2" color="blue">arxiv.org/abs/2501.09223…</a> highly recommend it if you're serious about understanding LLMs deeply.
The AI prompt library your competitors don't want you to find → Unlimited prompts: $15/month → Starter pack: $3.99/month → Pro bundle: $9.99/month Grab it before it's gone ↓ <a target="_blank" href="https://godofprompt.ai/pricing" color="blue">godofprompt.ai/pricing</a>
I hope you've found this thread helpful. Follow me @alex_prompter for more. Like/Repost the quote below if you can: <a target="_blank" href="https://twitter.com/1657385954594762758/status/1949050402810523990" color="blue">x.com/16573859545947…</a>