Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

How much do LLMs memorize? Meta and collaborators suggest that they can estimate model capacity by measuring memorization. "Models in the GPT family have an approximate capacity of 3.6 bits-per-parameter." Once capacity fills, generalization begins! More in my notes below:

Paper Overview It introduces a novel framework to quantify how much information an LLM memorizes about individual datapoints, separate from generalization. They define model capacity in terms of bits-per-parameter and present a method to measure unintended memorization.
Two-part decomposition of memorization The paper formalizes unintended memorization (data-specific info) vs. generalization (distribution-level knowledge), and introduces a Kolmogorov-inspired compression-based metric to distinguish them.
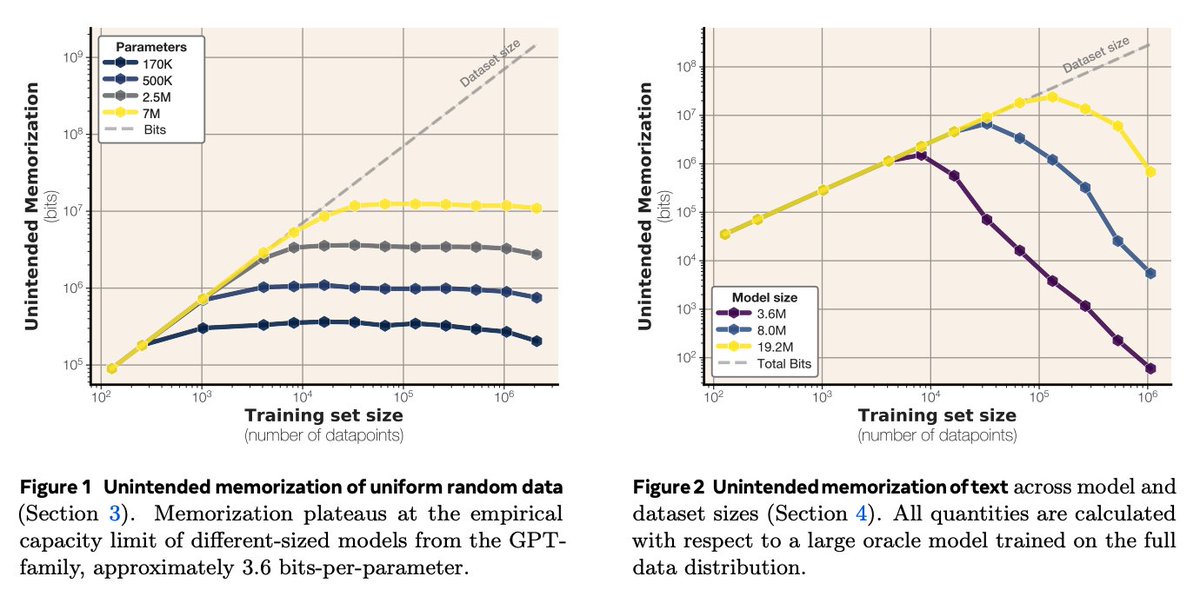
GPT capacity = 3.6 bits/parameter Through training on synthetic datasets with known entropy, the authors determine that GPT-style models trained in bfloat16 consistently memorize 3.5–3.6 bits per parameter, which increases slightly with fp32 precision. Their results show that GPT-family models can store about 3.6 bits-per-parameter, and propose scaling laws to predict memorization and membership inference.

Double descent and grokking As training data exceeds model capacity, models stop memorizing and begin to generalize, a transition coinciding with double descent in test loss. This supports the idea that generalization kicks in once memorization saturates.

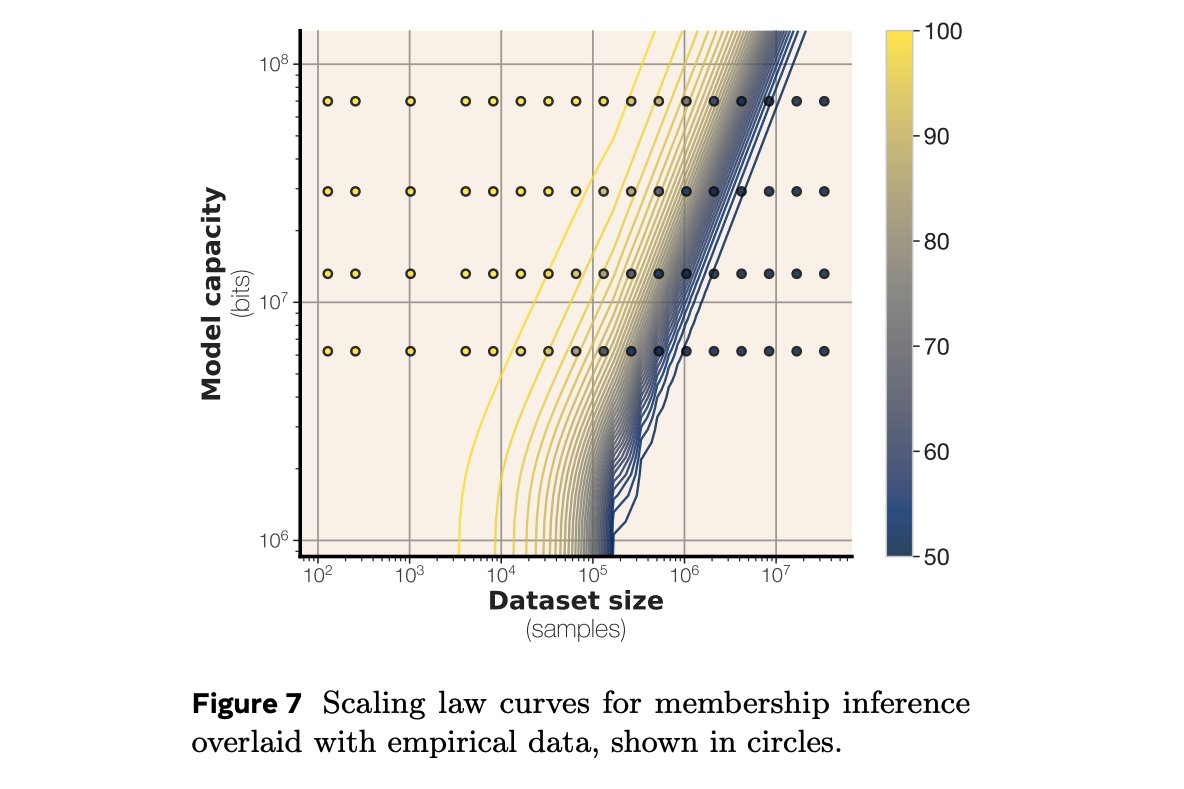
Scaling laws for membership inference The authors empirically derive a sigmoidal scaling law for membership inference performance as a function of capacity-to-data ratio. As the dataset size grows, inference accuracy drops to chance (F1 ~ 0.5), explaining why large models trained on huge corpora are resilient to this attack.
Rare tokens correlate with memorization On real text, highly memorized datapoints often contain rare words or languages (e.g., Japanese, Hebrew). This was measured using TF-IDF vs. memorization scores, indicating models are more likely to memorize outliers in the dataset.

Membership inference is easier than extraction Even when extraction fails, models can still exhibit detectable membership bias via loss differences, especially when trained on small datasets. The paper also shows that extraction success converges to test-level generalization as datasets grow large. Overall, the authors measured the capacity of modern transformer language models and analyzed how measurements such as extraction and F1 score scale with model and dataset size. Paper: <a target="_blank" href="https://www.arxiv.org/abs/2505.24832" color="blue">arxiv.org/abs/2505.24832</a>
