Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

Self-attention in LLMs, clearly explained:
Before we start a quick primer on tokenization! Raw text → Tokenization → Embedding → Model Embedding is a meaningful representation of each token (roughly a word) using a bunch of numbers. This embedding is what we provide as an input to our language models. Check this👇

The core idea of Language modelling is to understand the structure and patterns within language. By modeling the relationships between words (tokens) in a sentence, we can capture the context and meaning of the text.

Now self attention is a communication mechanism that help establish these relationships, expressed as probability scores. Each token assigns the highest score to itself and additional scores to other tokens based on their relevance. You can think of it as a directed graph 👇

To understand how these probability/attention scores are obtained: We must understand 3 key terms: - Query Vector - Key Vector - Value Vector These vectors are created by multiplying the input embedding by three weight matrices that are trainable. Check this out 👇
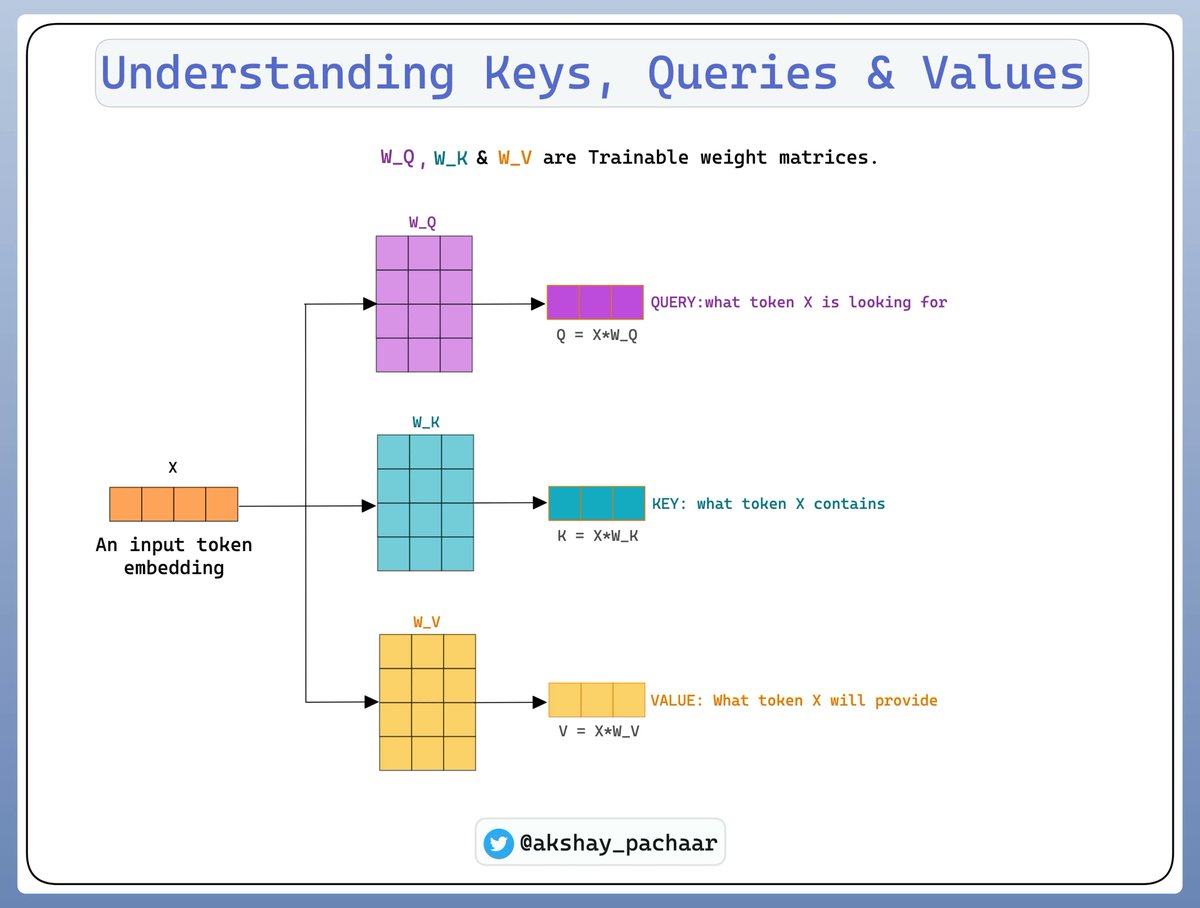
Now here's a broader picture of how input embeddings are combined with Keys, Queries & Values to obtain the actual attention scores. After acquiring keys, queries, and values, we merge them to create a new set of context-aware embeddings. Check this out👇

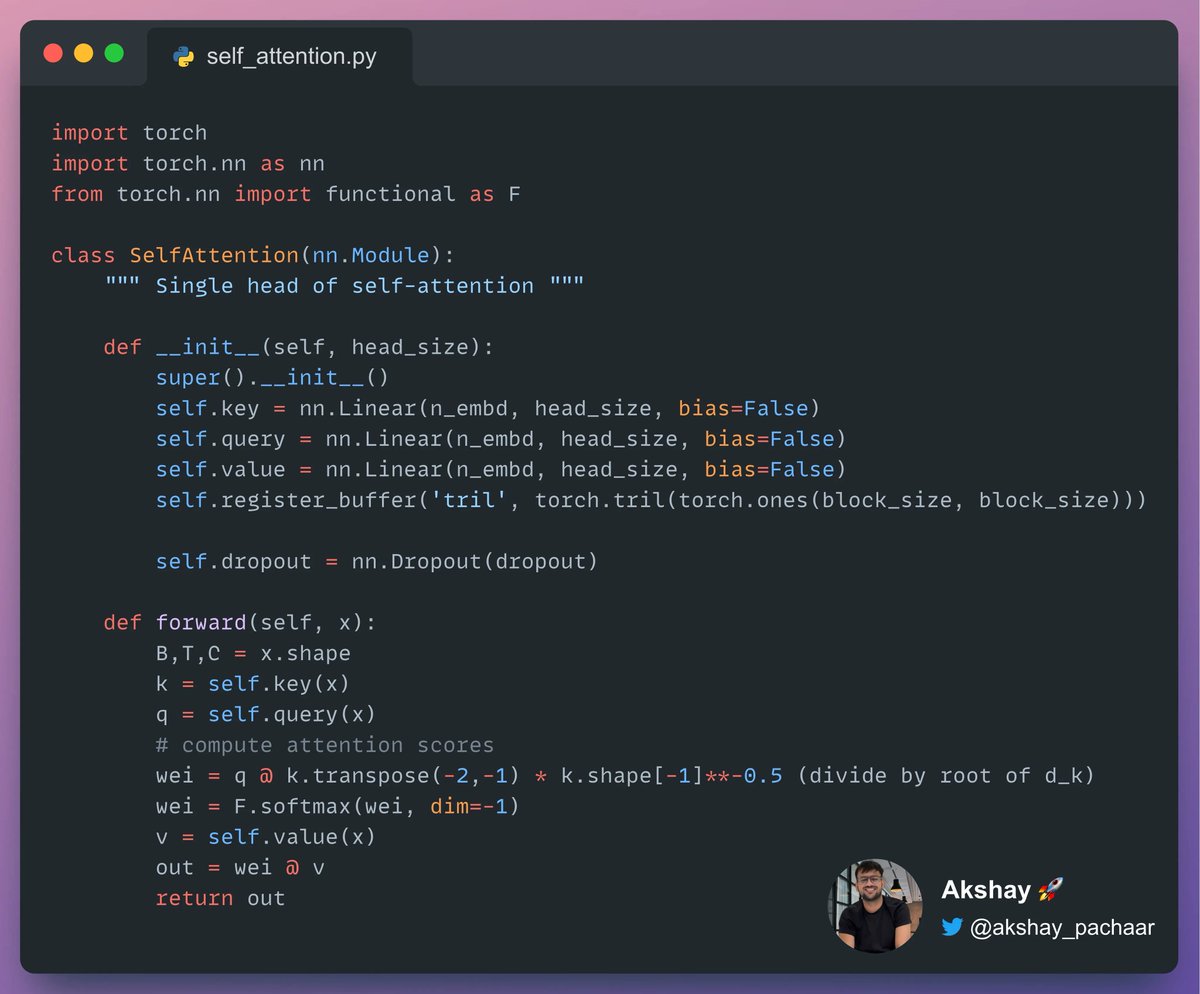
Implementing self-attention using PyTorch, doesn't get easier! 🚀 It's very intuitive! 💡 Check this out 👇
I'll leave you with this visual, which intuitively explains self-attention as a communication mechanism between tokens. This communication can be represented by a directed graph 👇

If you found it insightful, reshare with your network. Find me → @akshay_pachaar ✔️ For more insights and tutorials on LLMs, AI Agents, and Machine Learning! <a target="_blank" href="https://twitter.com/703601972/status/1930603077356462471" color="blue">x.com/703601972/stat…</a>