Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

The 10 types of clustering that all data scientists need to know. Let's dive in:

1. K-Means Clustering: This is a centroid-based algorithm, where the goal is to minimize the sum of distances between points and their respective cluster centroid.

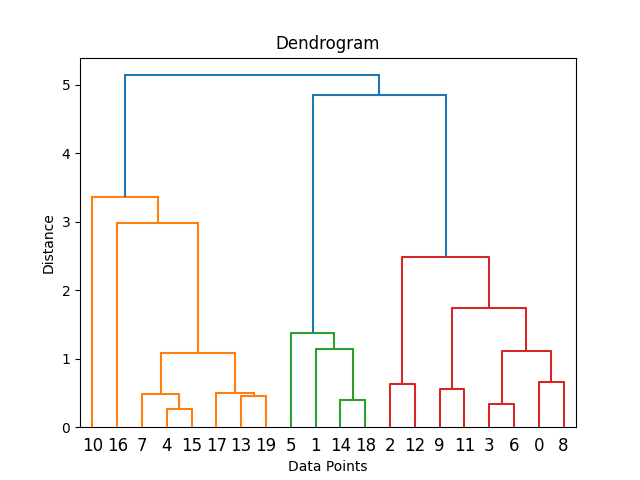
2. Hierarchical Clustering: This method creates a tree of clusters. It is subdivided into Agglomerative (bottom-up approach) and Divisive (top-down approach).
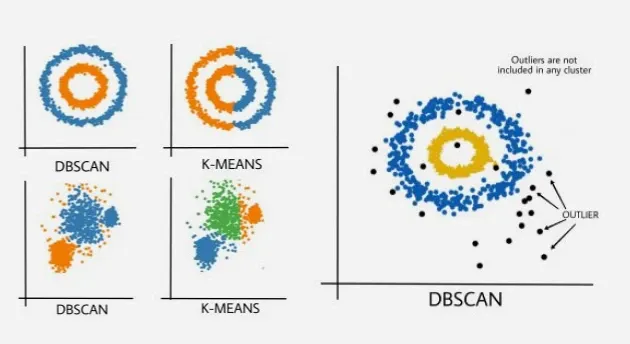
3. DBSCAN (Density-Based Spatial Clustering of Applications with Noise): This algorithm defines clusters as areas of high density separated by areas of low density.
4. Mean Shift Clustering: It is a centroid-based algorithm, which updates candidates for centroids to be the mean of points within a given region.
5. Gaussian Mixture Models (GMM): This method uses a probabilistic model to represent the presence of subpopulations within an overall population without requiring to assign each data point to a cluster.

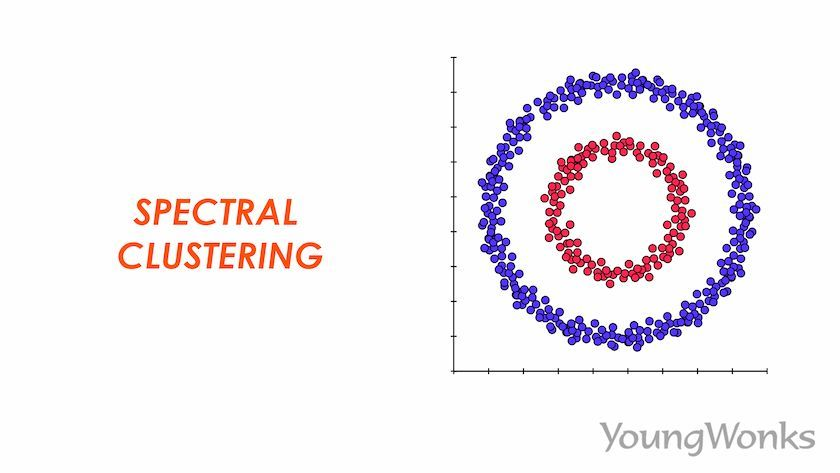
6. Spectral Clustering: It uses the eigenvalues of a similarity matrix to reduce dimensionality before applying a clustering algorithm, typically K-means.
7. OPTICS (Ordering Points To Identify the Clustering Structure): Similar to DBSCAN, but creates a reachability plot to determine clustering structure.
8. Affinity Propagation: It sends messages between pairs of samples until a set of exemplars and corresponding clusters gradually emerges.
9. BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies): Designed for large datasets, it incrementally and dynamically clusters incoming multi-dimensional metric data points.
10. CURE (Clustering Using Representatives): It identifies clusters by shrinking each cluster to a certain number of representative points rather than the centroid.

EVERY DATA SCIENTIST NEEDS TO LEARN AI IN 2025. 99% of data scientists are overlooking AI. I want to help.
On Wednesday, May 21st, I'm sharing one of my best AI Projects: Customer Segmentation Agent with AI Register here (500 seats): <a target="_blank" href="https://learn.business-science.io/ai-register" color="blue">learn.business-science.io/ai-register</a>
