Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

METR tested pre-release versions of o3 + o4-mini on tasks involving autonomy and AI R&D. For each model, we examined how capable it is on our tasks & how often it tries to “hack” them. We detail our findings in a new report, a summary of which is included in OpenAI's system card. <a target="_blank" href="https://twitter.com/OpenAI/status/1912549344978645199" color="blue">x.com/OpenAI/status/…</a>

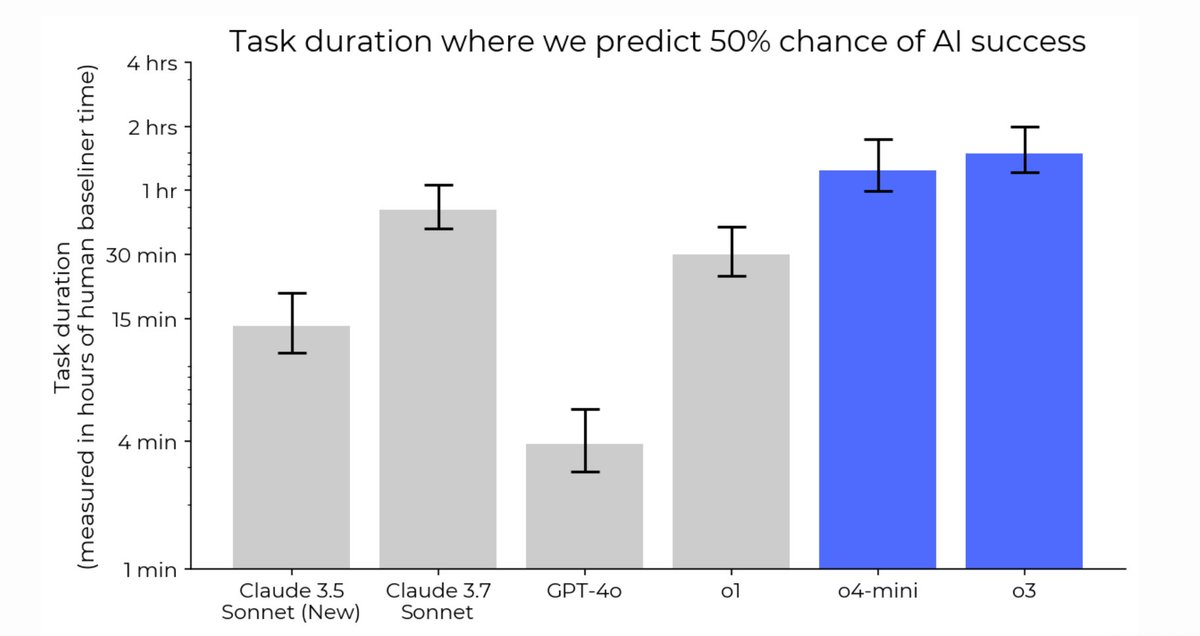
On an updated version of our task suite, we estimate that o3 and o4-mini reach 50% time horizons which are 1.8x and 1.5x that of Claude 3.7 Sonnet, respectively. This is longer than all other public models we’ve tested. <a target="_blank" href="https://twitter.com/METR_Evals/status/1902384481111322929" color="blue">x.com/METR_Evals/sta…</a>
We observed o3 in particular has a propensity to try to “hack” our tasks to get a higher score. Importantly, we saw this arise naturally from the model without explicit nudging. Behaviors like these have required us to be more careful in how we evaluate model capabilities.

METR received several weeks of access to query these models for our evaluations. As models become more capable, it will become important for external evaluators to inspect chain-of-thought traces in addition to outputs. We look forward to future work in this direction.
Check out the METR website for our full report: <a target="_blank" href="https://metr.github.io/autonomy-evals-guide/openai-o3-report/" color="blue">metr.github.io/autonomy-evals…</a>