Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

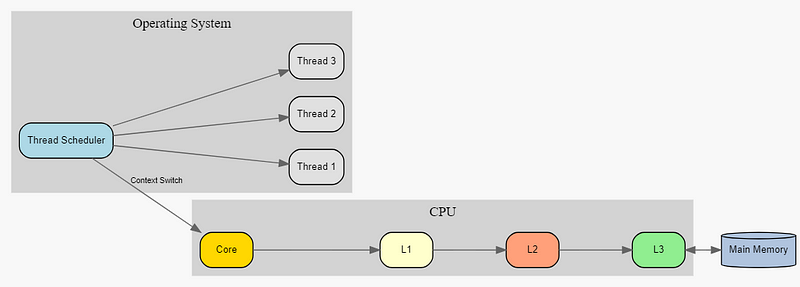
Multithreading in a Single CPU Multithreading on a single CPU is a complex process that involves complex interactions between the CPU, cache, memory, and operating system. When multiple threads run on a single CPU, they share the same physical resources, including the CPU cache. This sharing introduces challenges in maintaining data consistency and maximizing performance. The CPU cache is a small, fast memory that sits between the CPU and the main memory (RAM). It’s organized in a hierarchy, typically with three levels: L1 (smallest and fastest), L2, and L3 (largest and slowest of the cache levels). Each cache level is divided into cache lines, which are fixed-size blocks of memory (usually 64 bytes). When a thread accesses memory, the CPU first checks if the data is in the cache. If it’s not (a cache miss), the CPU fetches the data from the main memory and stores it in the cache for faster future access. This process is known as cache filling. I already have talked about this in detail in my previous tweets. Cache coherency becomes a critical issue when multiple threads share the same cache. If one thread modifies data that another thread has cached, the second thread might work with stale data, leading to inconsistencies. To prevent this, CPUs implement cache coherency protocols, such as the MESI (Modified, Exclusive, Shared, Invalid) protocol. The MESI protocol works as follows: 1. Modified (M): The cache line is present only in the current cache and is dirty (modified). 2. Exclusive (E): The cache line is present only in the current cache and is clean (unmodified). 3. Shared (S): The cache line is present in multiple caches and is clean. 4. Invalid (I): The cache line is invalid (unused or outdated). When a thread is swapped out, the operating system’s thread scheduler triggers a context switch. During this process, the CPU’s cache management system must ensure that any modified data in the cache is written back to the main memory (if in the Modified state) or invalidated (if in the Shared or Exclusive state). This process is known as cache flushing or invalidation. The exact mechanism of cache flushing depends on the CPU architecture. Some CPUs provide specific instructions for cache management, such as the WBINVD (Write Back and Invalidate Cache) instruction in x86 architectures. The operating system uses these instructions to manage the cache during context switches. It’s important to note that cache flushing is not always a complete flush of the entire cache. Modern CPUs and operating systems employ sophisticated techniques to minimize the performance impact of context switches: 1. Partial flushing: Only flush the cache lines associated with the outgoing thread. 2. Lazy flushing: Delay the flush until the cache line needs to be reused. 3. Cache tagging: Use additional bits to tag cache lines with thread or process IDs. The Thread Control Block (TCB) plays a crucial role in this process. The TCB is a data structure maintained by the operating system for each thread, containing information such as the thread’s state, register values, and memory management information. During a context switch, the operating system saves the current thread’s TCB and loads the next thread’s TCB. Another important aspect of multithreading on a single CPU is the concept of time-slicing. Since only one thread can execute at a time on a single CPU core, the operating system’s scheduler allocates CPU time to each thread in small intervals called time slices or quantum. The length of a time slice is a trade-off between responsiveness and overhead: shorter time slices provide better responsiveness for interactive applications but increase the overhead of context switching. The scheduler employs various algorithms to determine which thread to run next. Common scheduling algorithms include: 1. Round-robin: Each thread gets an equal share of CPU time in a circular order. 2. Priority-based: Threads with higher priority get more CPU time. 3. Multilevel queue: Multiple queues with different priorities, each using a different scheduling algorithm. To further optimize performance, modern CPUs implement Simultaneous Multithreading (SMT), also known as Hyper-Threading in Intel CPUs. SMT allows a single physical CPU core to appear as multiple logical cores in the operating system. It does this by duplicating certain parts of the CPU (such as registers) while sharing others (such as the execution units and cache). This allows two threads to execute simultaneously on a single physical core, improving overall throughput, especially for workloads with mixed instruction types. However, SMT can also introduce its challenges, such as cache contention and potential security vulnerabilities (like the Spectre and Meltdown attacks). Operating systems and CPU manufacturers continuously work on mitigations and improvements to balance performance and security in multithreaded environments. I tried to show how multi-threading works below. You can find the full code link here: <a target="_blank" href="https://bit.ly/4fZKGPe" color="blue">bit.ly/4fZKGPe</a> That's it for today. Let me know if you have any questions or suggestions.