Canvas & Ratio
Choose your destination platform format
Layout Template
Choose a content structure for your slides
Preset Themes
Typography & Sizing
Brand Kit Customization
AGENCYConfigure brand assets for headers & footers
Outro Slide CTA
Customize your closing call-to-action slide
Background Pattern
Build Your Carousel
Drag and drop any post card below onto a slide, or use the quick buttons to insert content/images instantly!

What's more convincing? p = 0.04 in a sample of 10 or p = 0.04 in a sample of 1,000,000? 🧵
Pick an answer, then go to the next post.
OK, now you've answered, and I hope you answered correctly: p = 0.04 in a sample of 10 will generally be much more convincing than that same p-value in a sample of 1,000,000 people. The reason has to do with a paradox.
This is my favorite illustration of the paradox (from @lakens): Even when there's no effect, with a large sample, you'll find plenty of significant estimates because minuscule deviations from 'no effect' with a point null will often be significant if you have high power.

Because of this fact, the same p-value at different levels of power corresponds to very different levels of evidence. So p = 0.04 in a sample of 1,000,000? That could be better evidence against an effect than for it. That the essence of Lindley's paradox.
Lindley's paradox makes it very clear why p-values are not measures of evidence absent context. If we want reliable measures of the evidence for something, we can use likelihoods or Bayes factors instead.

The way Bayes factors work is by dividing the marginal likelihood of the data you observe under one hypothesis to its marginal likelihood under another hypothesis. Or even simpler, comparing the probability of one model (M0) to another (M1) given an observation.*
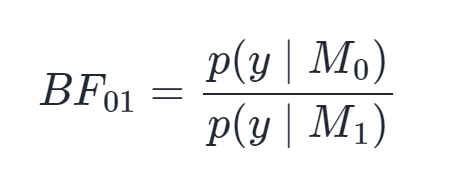
I'm going to get to some results, but first: The ladder of evidential strength proposed by Sir Harold Jeffreys goes from evidence being worth little more than an anecdote to being extreme. This goes in reverse when the denominator is larger than the numerator.

In 2018, Hoekstra et al. evaluated the evidence for null effects in medicine. Several trials had found nonsignificant results, but it wasn't clear how much evidence in favor of the null those trials provided. There was only a modest relationship with p-values.
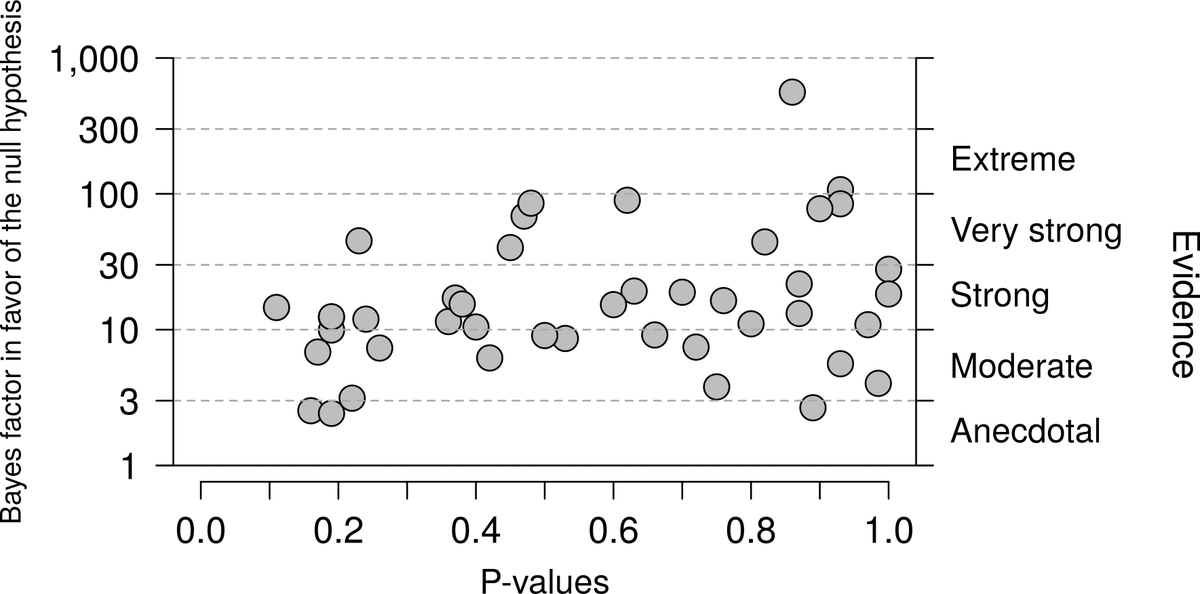
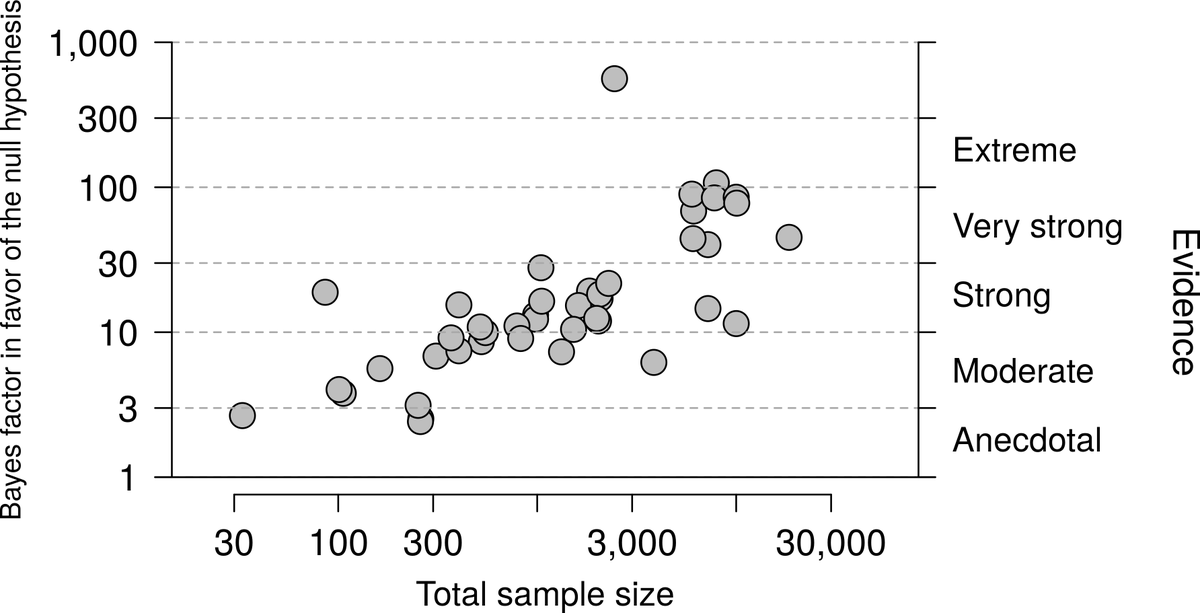
But p-values are evidently less important than sample size for determining if some effect isn't real. Studies with larger sample sizes provided much better evidence in favor of no effect.
Hulme et al. evaluated the efficacy of hydroxychloroquine for treating COVID-19. They found that reanalyzing a trial showing benefits from HCQ with patients who deteriorated, excluding the untested, or when the excluded were assumed positive, the evidence became fairly weak.
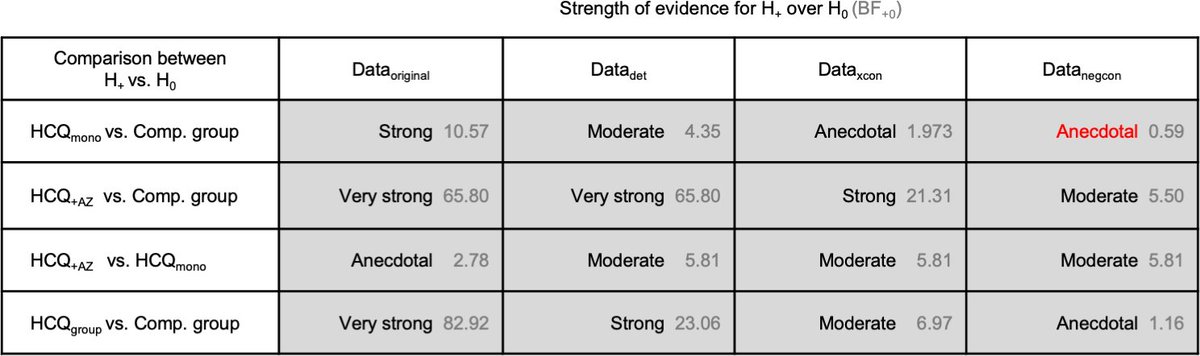
In another HCQ reanalysis, Wagenmakers and Gronau found that the evidence for a treatment effect among COVID-19 patients with pneumonia was only moderate, suggesting the need for more research.
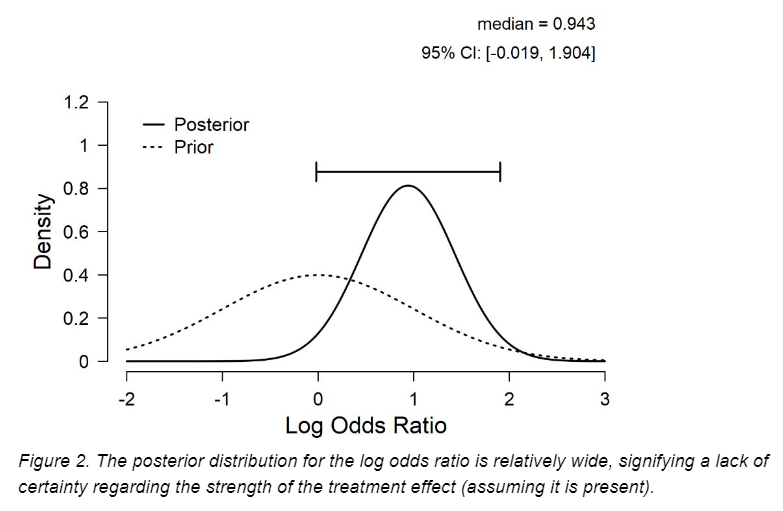
In 1959, Festinger and Carlsmith conducted a now-famous study where they documented Festinger's recently-coined concept of "cognitive dissonance". The study has been cited almost 6,000 times.

In the study, participants did tedious tasks for an hour and were then not paid, paid $1, or paid $20 to tell people that the tasks were interesting. The paid groups ended up rating the tasks more interesting after all was said and done, showing 'cognitive dissonance.'
Reanalysis of this result in 2018 suggested that the evidence for cognitive dissonance was actually not more than anecdotal. In other words, it was not worth more than a bare mention for demonstrating the phenomenon it was argued to show.
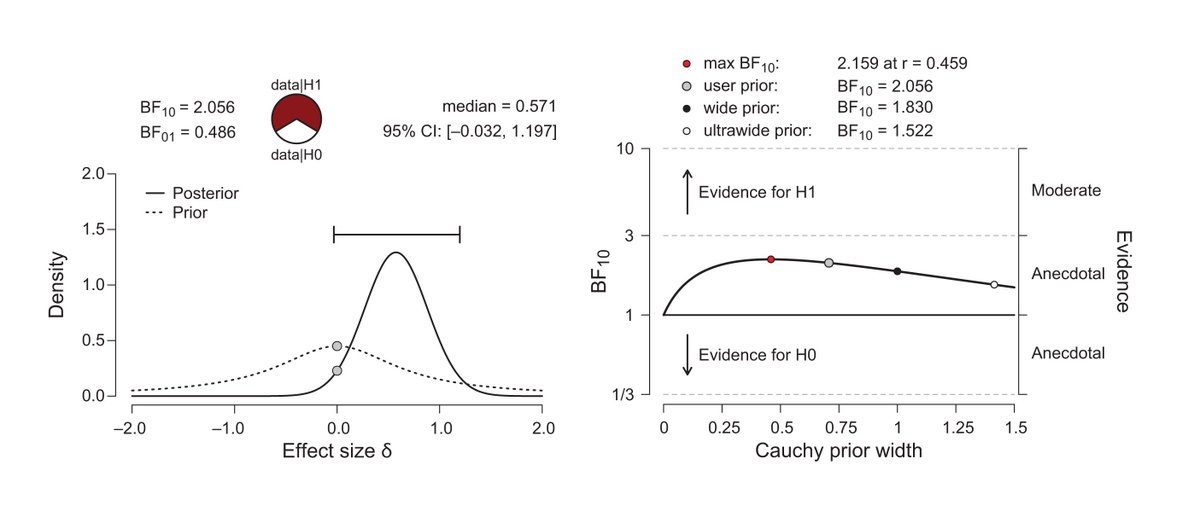
Bayes factors might be able to help with the abuse of p-values. The way they could do that is by forcing people to put more thought into their analyses. So if I'm being realistic, I don't expect them to help, but I hope you'll agree they're pretty cool!
Sources: <a target="_blank" href="https://www.cell.com/trends/ecology-evolution/abstract/S0169-5347(21)00341-4" color="blue">cell.com/trends/ecology…</a> <a target="_blank" href="https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0195474" color="blue">journals.plos.org/plosone/articl…</a> <a target="_blank" href="https://journals.plos.org/plosone/article?id=10.1371/journal.pone.0245048" color="blue">journals.plos.org/plosone/articl…</a> <a target="_blank" href="https://osf.io/preprints/psyarxiv/7nk8z" color="blue">osf.io/preprints/psya…</a> <a target="_blank" href="https://journals.sagepub.com/doi/full/10.1177/2515245918779348" color="blue">journals.sagepub.com/doi/full/10.11…</a> <a target="_blank" href="https://psycnet.apa.org/record/1960-01158-001" color="blue">psycnet.apa.org/record/1960-01…</a> <a target="_blank" href="https://journals.sagepub.com/doi/full/10.1177/2515245918779348" color="blue">journals.sagepub.com/doi/full/10.11…</a> Unnoted in the thread results regarding kidneys: <a target="_blank" href="https://osf.io/preprints/psyarxiv/4pf9j" color="blue">osf.io/preprints/psya…</a>, <a target="_blank" href="https://ccforum.biomedcentral.com/articles/10.1186/s13054-022-04120-y" color="blue">ccforum.biomedcentral.com/articles/10.11…</a> * I know this definition is imprecise, but it's a tweet. I also know Bayes factors aren't perfect and they can be abused.
For clarity, the first post is asking about which is more convincing evidence of an effect being present. The post on Jeffreys' classifications mentions going in reverse, but to be clear, what I mean is fractional Bayes factors being evidence for the denominator hypothesis/model
Clarification on what I meant with the apostrophes around 'no effect' in the p-value plot: <a target="_blank" href="https://twitter.com/cremieuxrecueil/status/1780834586982764545" color="blue">x.com/cremieuxrecuei…</a>