
AI scaling is not exponential. It never was. I fit a logistic model to general capability vs compute across every major model generation — AlexNet to GPT-4. R² = 0.98. The asymptote is not infinity. Never was or will be. Thread 🧵

Utility defined as (model score − chance) / (human ceiling − chance) averaged across MMLU, NarrativeQA, GSM8K, MedQA on a fixed suite. Vision-era models scored on the full suite including language, intentionally.
This isn’t just curve fitting. The Cramér-Rao lower bound is ironclad: there is a hard information-theoretic ceiling on what you can extract from a finite training distribution regardless of compute. The asymptote is a theorem, not an assumption. L was fit as a free parameter.
∂U/∂x at GPT-4: 0.00001
∂²U/∂x² throughout the GPT era: negative
We passed the inflection point at BERT-Large. Every subsequent model generation has been buying movement along a curve that is basically flat. Stargate is buying horizontal movement
∂²U/∂x² throughout the GPT era: negative
We passed the inflection point at BERT-Large. Every subsequent model generation has been buying movement along a curve that is basically flat. Stargate is buying horizontal movement
The entire bull case for AI valuations is predicated on e^{at}. Nvidia, OpenAI, hyperscaler capex, all priced on exponential functional form.
The logistic fits dramatically better. Functional form misspecification is as obvious as day here. What a hype bubble 🫧
The logistic fits dramatically better. Functional form misspecification is as obvious as day here. What a hype bubble 🫧
This week: FT reports companies curbing AI deployments as costs outpace ROI. This is not a demand problem. It’s the second derivative turning negative in the real economy.
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Cramér-Rao formalizes your data quality argument: MSE = variance + bias². Scaling compute reduces variance asymptotically. It cannot reduce bias in the training distribution
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Garbage in, garbage out regardless of GPU count. The logistic ceiling IS the bias floor. No amount of Stargate fixes a biased training distribution and limited information content
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Grok, xAI’s own AI, on my logistic scaling thread: “Bearish for the bigger = magically smarter forever narrative that inflated many AI valuations”. Even the product built to sell the narrative can see the curve 😂

@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Sensitivity analysis: I downloaded Epoch’s zip data and fit, as well as added nonparametric loess, added loglik and AIC.
Strongly bolsters logistic functional form and saturation!
Talk about diminishing returns, what a hype scam
Strongly bolsters logistic functional form and saturation!
Talk about diminishing returns, what a hype scam

@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Additionally: Brier score has a beautiful property: it decomposes cleanly into what you can improve and what you cannot. The Uncertainty term is irreducible, it’s the floor set by your data
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Corpus bias means the model minimizes loss under the wrong distribution. This doesn’t just raise the uncertainty floor, it corrupts resolution and calibration too. The model learns to be confident about the wrong things. No compute fixes a misaligned objective.
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Fisher Information makes this precise. I(theta) measures how much your data can actually tell you about what you’re estimating. Sparsity, low signal:noise, and systematic bias all play in
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Cramer-Rao follows as no unbiased estimator, **regardless of complexity** can have variance below 1/I(θ). This is a theorem. Compute MIGHT scale your estimator’s efficiency toward that bound. It does not move the bound.
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell And you cannot even reach 1/I(theta) in practice. The CRB requires correct model specification and exact optimization. Transformers are *misspecified* relative to the true DGP. SGD introduces its own bias. The reachable ceiling sits strictly BELOW the theorem’s guarantee
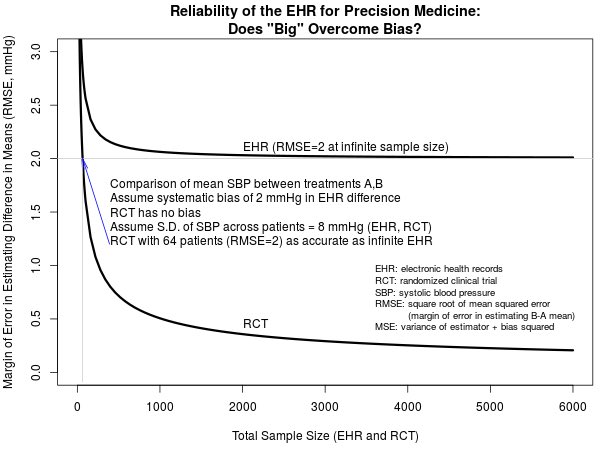
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Frank Harrell’s RMSE plot from y EHR/RCT post is the cleanest argument against AI scaling I’ve seen. Bias² is a floor compute cannot move. MSE = variance + bias² applies whether your n is patients or parameters. fharrell.com/post/ehrs-rcts/
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Grateful for the engagement on this thread. The bridge from RCTs to AI scaling struck me between patients and after clinic hours. Harrell’s RMSE plot has been living rent-free in my head ever since. Medicine teaches you that bias doesn’t yield to volume. Neither does compute
@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Reran with L totally free (no bounds).
MLE: L = 0.900
95% profile CI: [0.848, 0.952]
Human ceiling (1.0) excluded from the CI.
Saturation isn’t imposed, the data **put it there**
MLE: L = 0.900
95% profile CI: [0.848, 0.952]
Human ceiling (1.0) excluded from the CI.
Saturation isn’t imposed, the data **put it there**

@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Another key caveat: I used Claude to help scrape HELM and other published data. There is missingness of data.
Manually pulling data from HELM here for NarrativeQA, saturation conclusion is unchanged
Manually pulling data from HELM here for NarrativeQA, saturation conclusion is unchanged

@ylecun @GaryMarcus @fchollet @profgalloway @AswathDamodaran @f2harrell Next sensitivity analysis, manually pulling the GSM8k win rate data from HELM lite, logistic and loess fits; saturation confirmed 👍

Generated by Thread Navigator
Press ⌘ + S to quick-export