"You need a 24 GB GPU for serious local LLMs in 2026."
Everyone repeats this. It's not true anymore.
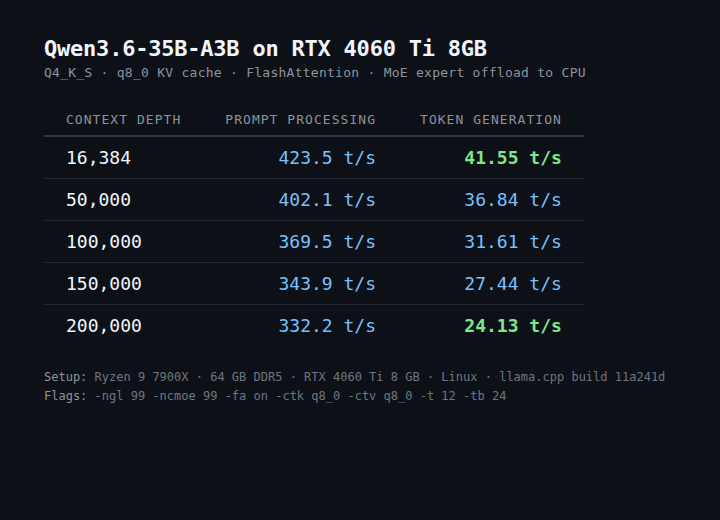
Just ran a 35B-parameter model on an RTX 4060 Ti 8 GB: • 41 tok/s at 16k context • 24 tok/s at 200k context
Recipe + benchmarks below 🧵

How to make it work:
MoE offload. Qwen3.6-35B activates only 3 B params per token. Keep attention + shared weights on GPU, push the cold expert FFNs to system RAM. In llama.cpp: -ngl 99 -ncmoe 99.
q8_0 KV cache. ~10 KB/token. 200k fits in 2 GB VRAM with FlashAttention on.
MoE offload. Qwen3.6-35B activates only 3 B params per token. Keep attention + shared weights on GPU, push the cold expert FFNs to system RAM. In llama.cpp: -ngl 99 -ncmoe 99.
q8_0 KV cache. ~10 KB/token. 200k fits in 2 GB VRAM with FlashAttention on.
Receipts. Qwen3.6-35B-A3B Q4_K_S, q8_0 KV, single-batch, FA on. Same machine, same model, varying context depth:
PP barely moves (332 t/s even at 200 k tokens). TG decays ~linearly with depth — attention scan over the full KV is the bottleneck, as expected.
PP barely moves (332 t/s even at 200 k tokens). TG decays ~linearly with depth — attention scan over the full KV is the bottleneck, as expected.

Why RTX 3070 8GB owners shouldn't write the card off:
The real bottleneck is host-RAM bandwidth for the MoE experts (~3 B active × Q4 ≈ 1.5 GB/token of streaming reads from DDR5), not GPU compute. The 3070 actually has higher memory bandwidth than the 4060 Ti (448 vs 288 GB/s).
The real bottleneck is host-RAM bandwidth for the MoE experts (~3 B active × Q4 ≈ 1.5 GB/token of streaming reads from DDR5), not GPU compute. The 3070 actually has higher memory bandwidth than the 4060 Ti (448 vs 288 GB/s).
If you have 64 GB RAM and a half-decent CPU, MoE + 8GB is arguably the new home-LLM sweet spot.
What setup are you running?
What setup are you running?
@MikelEcheve made a cool image for this post!

Generated by Thread Navigator
Press ⌘ + S to quick-export