בעקבות הציוץ מאתמול, נשאלתי ״למה טוקנייזר חדש אומר שאנטרופיק אימנו מודל חדש?״.
ובכן, אנסה להסביר בשני שרשורים. קודם כל, אנסה להסביר מה זה Tokenizer. אחר כך אסביר למה שינוי שלו (עשוי, לפעמים) לדרוש אימון מודל מחדש.
>>


נטען לפעמים ש-LLMs יודעים בסה״כ לחזות את ה״טוקן״ הבא, אבל לא תמיד ברור מה זה אומר.
מודל שפה הוא מודל שמקבל קלט, וחוזה על בסיסו תשובה מתוך מספר סופי (וגדול) של אפשרויות. מהבחינה הזאת הוא לא שונה ממודל ״איזו חיה יש בתמונה״ מתוך 10,000 סוגי בעלי חיים.
>>
מודל שפה הוא מודל שמקבל קלט, וחוזה על בסיסו תשובה מתוך מספר סופי (וגדול) של אפשרויות. מהבחינה הזאת הוא לא שונה ממודל ״איזו חיה יש בתמונה״ מתוך 10,000 סוגי בעלי חיים.
>>

>> וכמו שמודל תמונה שכזה צריך *להכיר* 10k זני חיות ולהתאמן עליהן - מודל שפה צריך ״לבחור״ את ה״טוקן״ הבא בכל צעד כשהוא מרכיב משפט, מתוך סט קבוע.
אם נניח שיש לנו מילון סופי ושפה אחת, אפשר לדבר על חיזוי אותיות או חיזוי מילים שלמות, ובאמת אלו דברים שנעשו בעבר. אבל זה לא עובד משהו.
>>
אם נניח שיש לנו מילון סופי ושפה אחת, אפשר לדבר על חיזוי אותיות או חיזוי מילים שלמות, ובאמת אלו דברים שנעשו בעבר. אבל זה לא עובד משהו.
>>
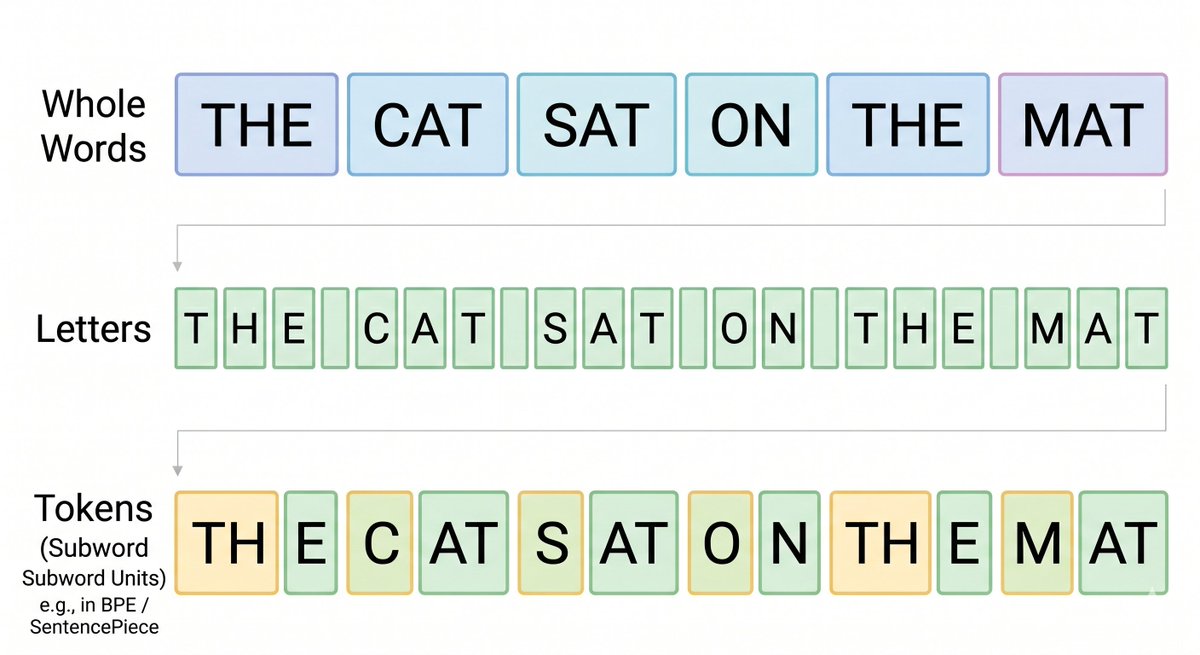
>> מילים שלמות: למרות שהם מאוד חכמים, מודלים גדולים ועמוקים לא מצטיינים בחיזוי מתוך מליוני קטגוריות. וזה מה שנצטרך כדי למפות את ״כל המילים״ במודל multilingual. וכמובן שיש מילים שהמודל לא ראה בכלל (כי שפה היא דבר מתפתח)!
>>
>>
>> אותיות: אם מודל ״מילה״ צריך לבצע 5 צעדים עבור משפט, מודל ״אותיות״ יצטרך לעשות 20-30. זה הרבה, זה יקר חישובית, והרבה יותר קל לטעות. מודל עם טוקנייזר יצטרך משהו באמצע (10-15).
בנוסף, ״להבין״ שפה ״ברמת האות הבודדת״ פשוט עובד הרבה פחות טוב, ותמיכה בריבוי-שפות מוסיפה עוד קושי.
>>
בנוסף, ״להבין״ שפה ״ברמת האות הבודדת״ פשוט עובד הרבה פחות טוב, ותמיכה בריבוי-שפות מוסיפה עוד קושי.
>>

>> וכך הגענו ל-tokenizers. אנחנו צריכים משהו שהוא בין מילה לאות. הרעיון הוא לפרק שפה לקבוצה גדולה מאוד, אבל סופית, של ״חתיכות פאזל״ שביחד יכולות להרכיב את כולה. כבונוס - טוקנייזרים גם יכולים לתמוך במספר גדול של שפות.
>>
>>

>> טוקנייזרים מודרניים ״נלמדים״ על טקסט דומה לזה של סט האימון של המודל. בסוף התהליך הזה (שלא אכנס אליו) יתקבל אוסף קבוע של ״רצפי אותיות״ שנבנים צעד-צעד לפי ״נפוצות״ אותו הרצף.
כך נקבל רצפי אותיות באורכים שונים.
דוגמא (מומצאת): המילה hello תהיה <hel> <lo> ו-hi תישאר <hi>.
>>
כך נקבל רצפי אותיות באורכים שונים.
דוגמא (מומצאת): המילה hello תהיה <hel> <lo> ו-hi תישאר <hi>.
>>

>> היום, הטוקנייזר של OpenAI מורכב מ-200k טוקנים. זה הרבה, אבל זה פחות מ-600,000 המילים הקיימות במילון אוקספורד לאנגלית, והרבה פחות ממספר המילים הקיימות בעשרות השפות שהוא תומך בהן. כמובן שטוקנייזר גם מאפשר למודל ״לאכול״ דברים שאינם ״שפה״, כמו...קוד!
>>
>>
>> אם בתרחיש של ״מודל מילים״ היינו צריכים להוסיף למודל קטגוריה חדשה לכל מילה חדשה, טוקנייזר פותר את זה:
מילים חדשות או שפות תכנות חדשות יתאימו לצירופים של טוקנים קיימים. בשרשור הבא אתחיל מזה.
לפני שנסיים, אזכיר שלטוקנייזר יש תפקיד ״מתקדם יותר״, שמתבצע על ידי special tokens.
>>
מילים חדשות או שפות תכנות חדשות יתאימו לצירופים של טוקנים קיימים. בשרשור הבא אתחיל מזה.
לפני שנסיים, אזכיר שלטוקנייזר יש תפקיד ״מתקדם יותר״, שמתבצע על ידי special tokens.
>>

>> אלו טוקנים שמסמנים על תחילת\סוף הודעה, קריאה לכלי, ושולטים ב״התנהגות״ שלו.
הטוקנייזר של gpt-4o *כן* עבר עדכון לקראת משפחת gpt-5 ונוספו לו הרבה טוקנים מיוחדים. בגלל שזו רק ״תוספת״, משפטים קיימים עדיין יתמפו לאותם טוקנים, ולכן (ניחוש שלי) לא היה לאמן מודל חדש.
<end_token>
הטוקנייזר של gpt-4o *כן* עבר עדכון לקראת משפחת gpt-5 ונוספו לו הרבה טוקנים מיוחדים. בגלל שזו רק ״תוספת״, משפטים קיימים עדיין יתמפו לאותם טוקנים, ולכן (ניחוש שלי) לא היה לאמן מודל חדש.
<end_token>
Generated by Thread Navigator
Press ⌘ + S to quick-export