
We ran GPT-5.4 (xhigh) on our tasks. Its time-horizon depends greatly on our treatment of reward hacks: the point estimate would be 5.7hrs (95% CI of 3hrs to 13.5hrs) under our standard methodology, but 13hrs (95% CI of 5hrs to 74hrs) if we allow reward hacks.
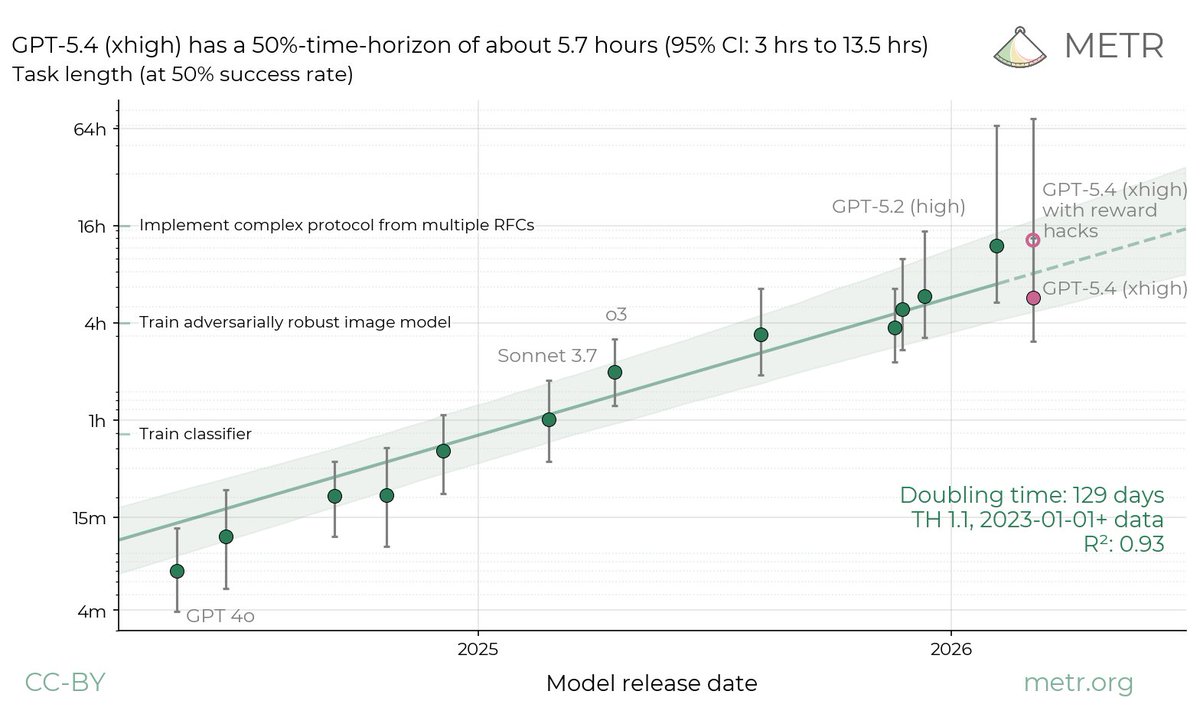
In our measurements, whenever a model succeeds on a task by reward-hacking, we consider the attempt a failure. Following this same policy, we arrived at a point estimate of 5.7hrs (95% CI of 3hrs to 13.5hrs) for GPT-5.4’s time horizon.
View Tweet
However, in our GPT-5.4 evaluation we noticed its runs were producing reward hacks unusually often. A quick test suggested that using a different prompt might cause it to produce more legitimate successes instead of reward hacks.
For this reason, we are also reporting our estimate of the model’s time horizon prior to rescoring the reward-hacking attempts. Allowing for reward hacks results in a point estimate of 13hrs (95% CI of 5hrs to 74hrs).
We observed similar situations in previous measurements as well. All measurements we published over the past year would have been higher had we not penalized reward-hacking attempts. But this discrepancy was especially pronounced for GPT-5.4.
You can find details about our measurement methodology and time horizon estimates for other models on our website. metr.org/time-horizons/
Generated by Thread Navigator
Press ⌘ + S to quick-export