Introducing GLM-5V-Turbo: Vision Coding Model
- Native Multimodal Coding: Natively understands multimodal inputs including images, videos, design drafts, and document layouts.
- Balanced Visual and Programming Capabilities: Achieves leading performance across core benchmarks for multimodal coding, tool use, and GUI Agents.
- Deep Adaptation for Claude Code and Claw Scenarios: Works in deep synergy with Agents like Claude Code and OpenClaw.
Try it now: chat.z.ai
API: docs.z.ai/guides/vlm/glm…
Coding Plan trial applications: docs.google.com/forms/d/e/1FAI…


VIDEO
The model can understand design drafts, screenshots, and web interfaces to generate complete, runnable code, truly achieving the goal of "seeing the screen and writing the code."

VIDEO
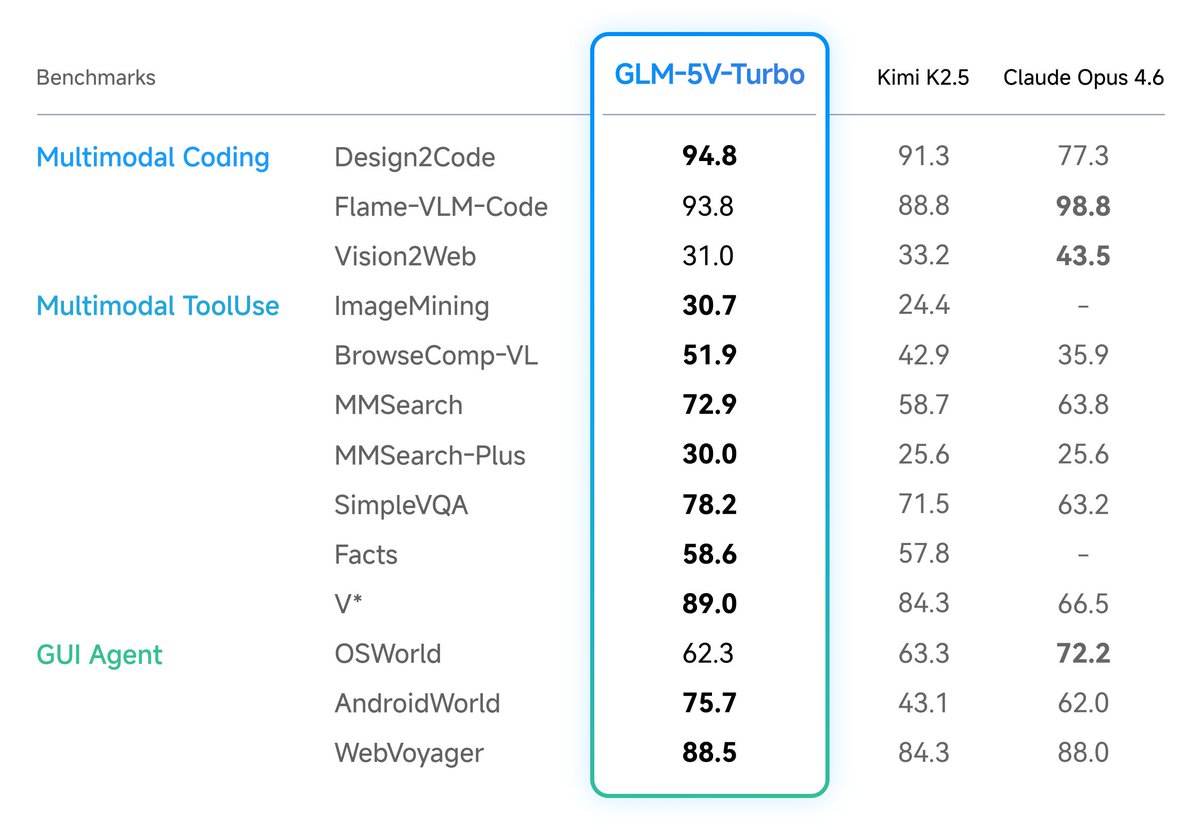
GLM-5V-Turbo leads in benchmarks for design draft reconstruction, visual code generation, multimodal retrieval and QA, and visual exploration. It also performs exceptionally well on AndroidWorld and WebVoyager, which measure control capabilities in real GUI environments.
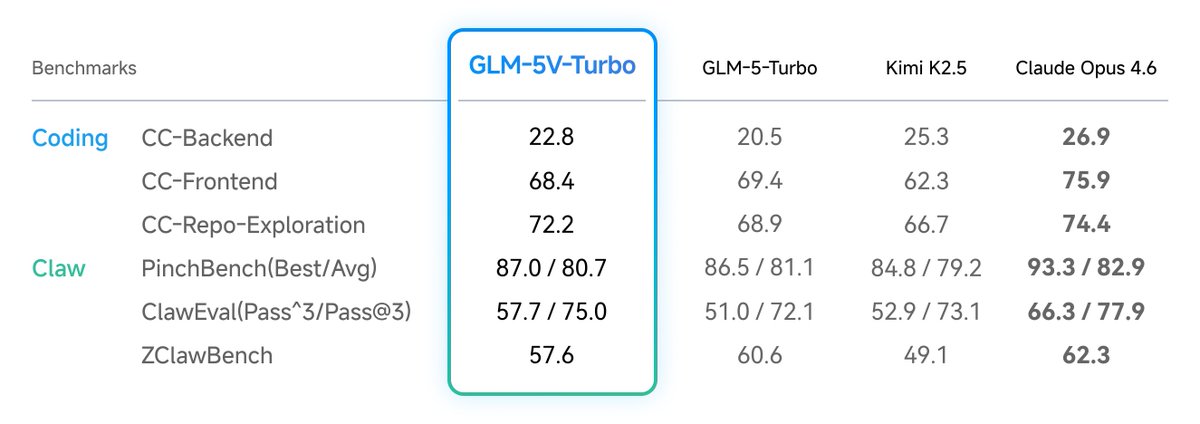
Regarding pure-text coding, GLM-5V-Turbo maintains stable performance across three core benchmarks of CC-Bench-V2 (Backend, Frontend, and Repo Exploration), proving that the introduction of visual capabilities does not degrade text-based reasoning.
The leading performance of GLM-5V-Turbo stems from systematic upgrades across four levels:
Native Multimodal Fusion: Deep fusion of text and vision begins at pre-training, with multimodal collaborative optimization during post-training. We developed the next-generation CogViT visual encoder, reaching SOTA in general object recognition, fine-grained understanding, and geometric/spatial perception. We also designed an inference-friendly MTP structure to ensure high efficiency.
30+ Task Collaborative RL: The RL stage optimizes over 30 task types simultaneously, covering STEM, grounding, video, and GUI Agents. This improves perception and reasoning while mitigating the instability often found in single-domain training.
Agentic Data and Task Construction: To solve the challenge of scarce Agent data, we built a multi-level system ranging from element perception to sequence-level action prediction. We use synthetic environments to generate verifiable training data and inject "Agentic Meta-capabilities" during pre-training (e.g., adding GUI Agent PRM data to reduce hallucinations).
Multimodal Toolchain Extension: Beyond text tools, the model supports multimodal search, drawing, and web reading. This expands the perception-action loop into visual interaction. Synergies with Claude Code and OpenClaw are enhanced to support full-loop task execution.
Native Multimodal Fusion: Deep fusion of text and vision begins at pre-training, with multimodal collaborative optimization during post-training. We developed the next-generation CogViT visual encoder, reaching SOTA in general object recognition, fine-grained understanding, and geometric/spatial perception. We also designed an inference-friendly MTP structure to ensure high efficiency.
30+ Task Collaborative RL: The RL stage optimizes over 30 task types simultaneously, covering STEM, grounding, video, and GUI Agents. This improves perception and reasoning while mitigating the instability often found in single-domain training.
Agentic Data and Task Construction: To solve the challenge of scarce Agent data, we built a multi-level system ranging from element perception to sequence-level action prediction. We use synthetic environments to generate verifiable training data and inject "Agentic Meta-capabilities" during pre-training (e.g., adding GUI Agent PRM data to reduce hallucinations).
Multimodal Toolchain Extension: Beyond text tools, the model supports multimodal search, drawing, and web reading. This expands the perception-action loop into visual interaction. Synergies with Claude Code and OpenClaw are enhanced to support full-loop task execution.
Here comes AutoClaw. We offer a new solution to run OpenClaw locally on your own machine.
- Download and start immediately. No API key required.
- Bring any model you like, or use GLM-5-Turbo, optimized for tool calling and multi-step tasks.
- Fully local. Your data never leaves your machine.
We're giving data control back to Claw users.
Meet AutoClaw → autoglm.z.ai/autoclaw/
Join the conversation → discord.gg/jvrbCRSF3x
- Download and start immediately. No API key required.
- Bring any model you like, or use GLM-5-Turbo, optimized for tool calling and multi-step tasks.
- Fully local. Your data never leaves your machine.
We're giving data control back to Claw users.
Meet AutoClaw → autoglm.z.ai/autoclaw/
Join the conversation → discord.gg/jvrbCRSF3x

VIDEO
Generated by Thread Navigator
Press ⌘ + S to quick-export