Did researchers at Tencent just kill fine-tuning?
A new paper called Training-Free GRPO shows you can get the same results as reinforcement learning for $18 instead of $10,000, with zero parameter updates.
The idea is surprisingly simple:
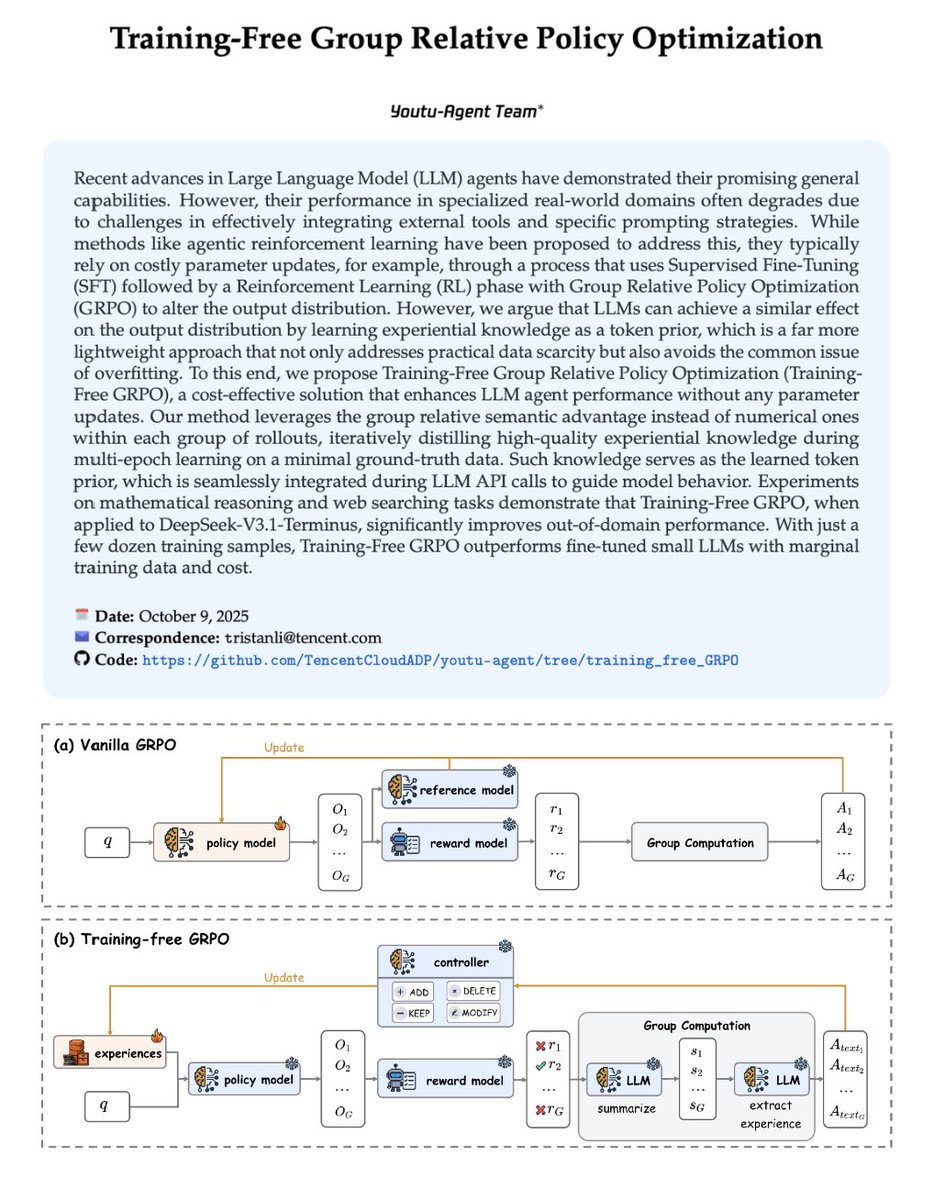
Instead of updating the model's weights through RL, you let the model practice on a few problems, compare what worked and what didn't across multiple attempts, and distill that into natural language "experiences" that get injected into the prompt.
The model stays completely frozen. All the learning happens in what the model reads, not what the model is.
Here's how it works:
↳ For each problem, generate multiple outputs and score them
↳ Compare the winners and losers within each group
↳ Ask the LLM to articulate WHY certain attempts succeeded
↳ Store those insights in an evolving experience library
↳ Inject the experiences into future prompts
The results are wild.
Training-Free GRPO applied to DeepSeek-V3.1-Terminus (671B) outperformed fine-tuned 32B models on the AIME math benchmarks.
It used 100 training samples instead of 17,000. It cost $18 instead of $10,000. And because the base model is never touched, it generalizes across both math AND web searching simultaneously.
Fine-tuned models can't do that. ReTool, trained on math, dropped from 67% to 18% when tested on web tasks. Worse than the baseline.
But I want to be clear on something:
This isn't just prompt engineering.
Directly asking an LLM to generate helpful tips doesn't work. Performance actually dropped when they tried that.
The experiences only become useful when they're distilled through the structured loop of trying, failing, comparing, and reflecting. That's what makes this different from self-reflection or few-shot prompting.
You might wonder: aren't we just bloating the context window?
Not really. Each experience is capped at 32 words. The math experiments produced 48 total. That's roughly 1,500 tokens for a model with a 128K context window.
And tool calls actually decrease after learning. The agent takes fewer wrong turns, so the small context cost saves tokens downstream.
I've shared link to the paper in the next tweet.

Generated by Thread Navigator
Press ⌘ + S to quick-export