
Your Base Model is Smarter Than You Think
This paper proposes a way to beat the lack of generation diversity in RL without RL!
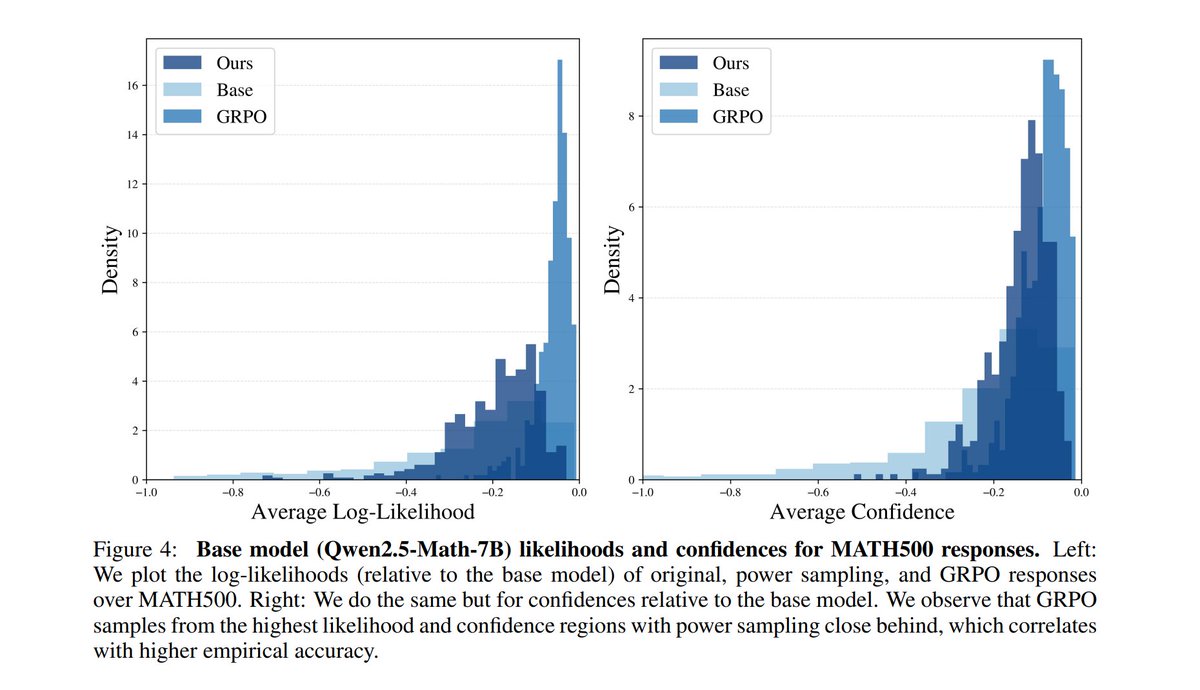
By using Markov Chain Monte Carlo’s ‘power sampling’ that reuses a base LLM’s own probabilities, it’s able to beat GRPO without training & verifiers

Generated by Thread Navigator
Press ⌘ + S to quick-export