🚨 Google just dropped the most advanced self-improving video AI ever built.
It’s called VISTA, and it literally rewrites its own prompts to make every new generation better than the last.
No retraining. No fine-tuning. Just pure test-time self-reflection.
Here’s how it works:
→ Turns your idea into a full scene-by-scene storyboard
→ Generates multiple video candidates
→ Runs a tournament to find the best one
→ Then critiques itself visually, audibly, contextually before trying again
Each loop = sharper visuals, tighter storytelling, more aligned motion.
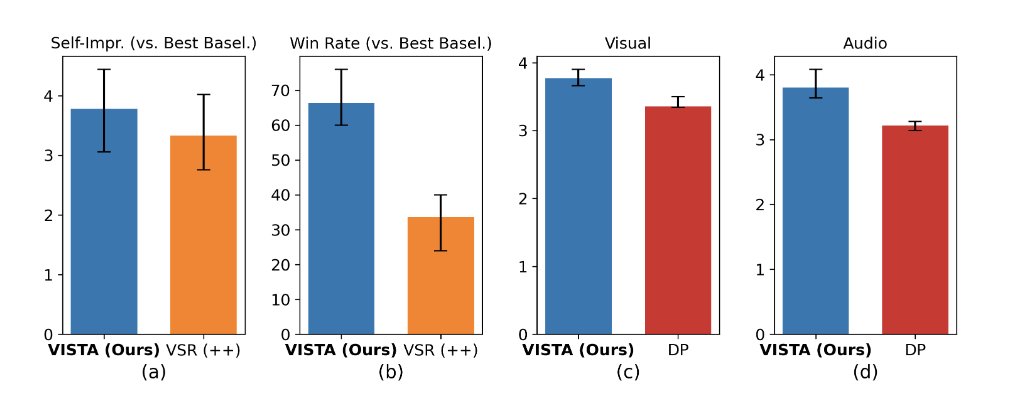
The results? 60% win rate vs Veo 3 and 66.4% human preference.
This isn’t “text-to-video.”
This is video that learns from itself.


Text-to-video models like Veo 3 and Sora are incredible but fragile.
Change one word in your prompt and your video falls apart.
VISTA fixes that.
It doesn’t just generate video, it plans, judges, and iterates like a director reviewing takes on set.
Change one word in your prompt and your video falls apart.
VISTA fixes that.
It doesn’t just generate video, it plans, judges, and iterates like a director reviewing takes on set.

VISTA breaks your idea into scene-by-scene plans with full details camera angles, mood, sounds, transitions.
Then it generates multiple versions and picks the best one in a pairwise tournament judged by an MLLM.
Think of it like AI video “survival of the fittest.”
Then it generates multiple versions and picks the best one in a pairwise tournament judged by an MLLM.
Think of it like AI video “survival of the fittest.”
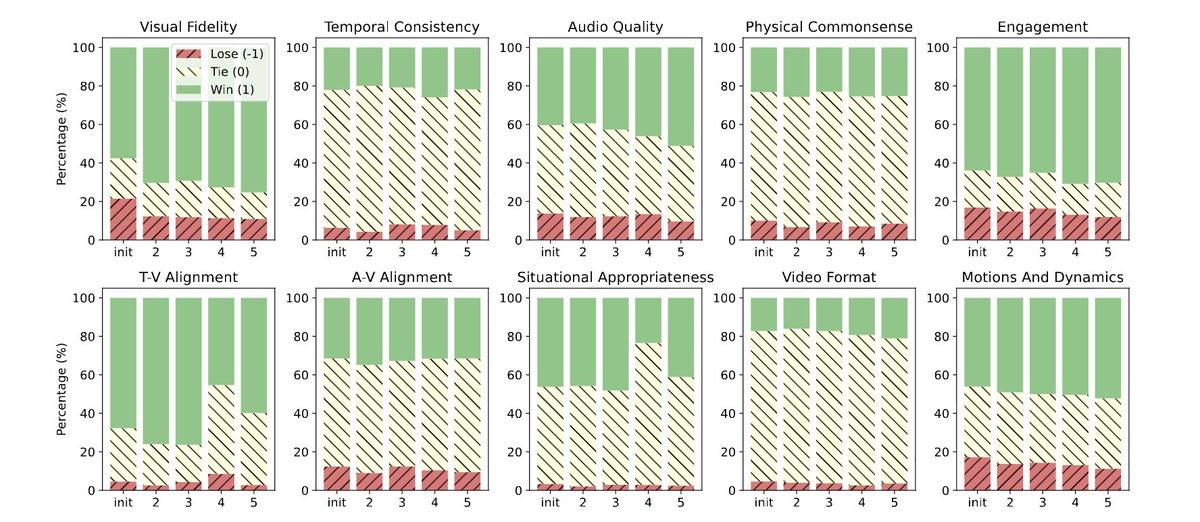
The self-critique loop...
After picking the best video, three specialized agents critique it:
• Visual agent → checks motion, lighting, focus
• Audio agent → checks sound sync and clarity
• Context agent → checks story flow and coherence
Then a “reasoning agent” rewrites the prompt to fix what went wrong.
After picking the best video, three specialized agents critique it:
• Visual agent → checks motion, lighting, focus
• Audio agent → checks sound sync and clarity
• Context agent → checks story flow and coherence
Then a “reasoning agent” rewrites the prompt to fix what went wrong.

VISTA improves without ever retraining the model.
It uses feedback from its own outputs to rewrite future prompts like an AI director learning with every take.
The results?
60% pairwise win rate vs state-of-the-art
66.4% preference by human evaluators
It uses feedback from its own outputs to rewrite future prompts like an AI director learning with every take.
The results?
60% pairwise win rate vs state-of-the-art
66.4% preference by human evaluators
This might be the moment AI video generation grows up.
Not “one-shot magic,” but self-improving creativity the same loop that makes humans better at their craft.
AI is now learning to direct itself.
We’re entering the era of autonomous creative systems.
Demos: g-vista.github.io
Not “one-shot magic,” but self-improving creativity the same loop that makes humans better at their craft.
AI is now learning to direct itself.
We’re entering the era of autonomous creative systems.
Demos: g-vista.github.io

If you’re building with AI, you need an edge.
The Shift shares 5-minute reads packed with new tools, prompts, and real-world AI strategies — every weekday.
Subscribe free: theshiftai.beehiiv.com/subscribe
Includes access to 2k+ AI tools and free AI courses.
The Shift shares 5-minute reads packed with new tools, prompts, and real-world AI strategies — every weekday.
Subscribe free: theshiftai.beehiiv.com/subscribe
Includes access to 2k+ AI tools and free AI courses.
Generated by Thread Navigator
Press ⌘ + S to quick-export