How To Save Over $100 Million Dollars Training An AI Model While Saving 90% On AI Workloads.
—
We see the whole page when we read, now AI sees it the same way and not one ASCII character at a time.
—
A significant evolution is underway that questions the dominance of text-based tokenization. Conventional LLMs depend on tokenized text inputs, which discretize linguistic elements into numerical representations for computational efficiency. However, vision and data encoding propose that pixels—the fundamental units of digital images—may serve as a more effective substrate for model inputs.
This transition could enhance data density, enable bidirectional contextual analysis, and mitigate inherent limitations in existing text-processing pipelines.
ChatGPT-type LLMs are linguistic simulator: they model how humans use language.
DeepSeek’s OCR-style pipeline is aiming for cognitive reconstruction: modeling how humans encode and organize meaning across media.
The distinction between:
“I read what they said.”
“I see how they thought.”
Optical Character Recognition and Data Compression in Visual Inputs
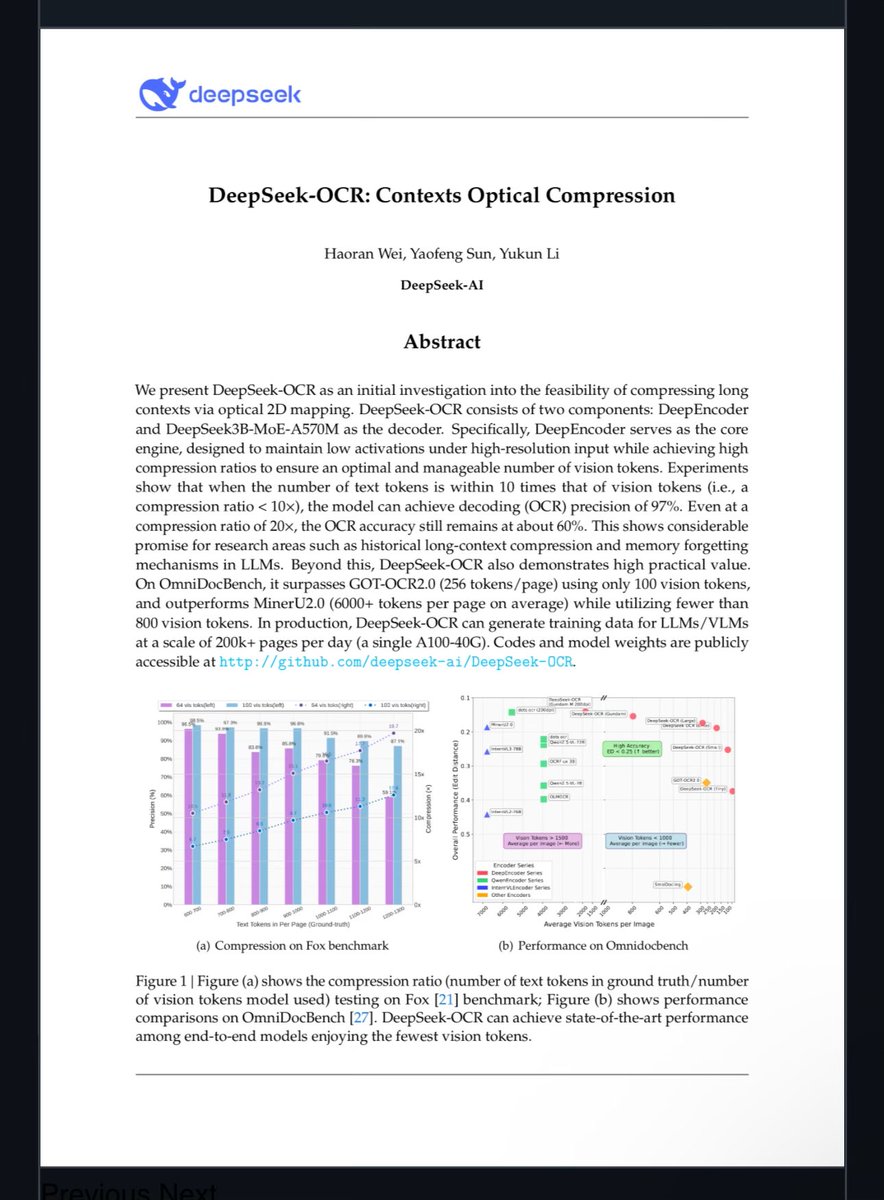
Contemporary optical character recognition (OCR) systems exemplify the advantages of visual data handling. Advanced models achieve compression ratios of up to 20:1 while preserving 97% accuracy across benchmarks such as document parsing and multimodal evaluations.
These systems process images to extract textual and structural information, allowing LLMs to manage extended contexts with reduced computational demands. By encoding documents, interfaces, or archival materials as images, the approach retains critical visual attributes including font variations, chromatic distinctions, and spatial arrangements that are often discarded in text-only formats.
Empirical assessments indicate superior performance in comprehensive tasks compared to legacy OCR methods, positioning visual inputs as a versatile foundation for heterogeneous data ingestion.
Limitations of Tokenization and Advantages of Pixel-Based Architectures
The tokenizer component in LLMs introduces systemic inefficiencies rooted in Unicode standards and byte-pair encoding schemes. These mechanisms can produce inconsistent representations for visually similar characters and abstract away perceptual elements like emojis or formatting cues. And autoregressive processing, wherein predictions occur sequentially constrains the model's ability to leverage full contextual interdependencies.
In contrast, pixel inputs facilitate bidirectional attention, permitting simultaneous evaluation of all data elements. This mirrors human visual cognition and supports end-to-end training without intermediary abstractions.
Rendering textual content as images prior to input eliminates tokenizer vulnerabilities, such as encoding-based exploits, and unifies processing across modalities. This symmetry extends to adapting vision-centric tasks to linguistic outputs, addressing the current imbalance where text adaptations predominate.
Photonic Scaling and Future AI Interfaces
Projections in AI infrastructure foresee a predominance of photonic data pathways, with over 99% of inputs and outputs mediated by optical signals for their superior bandwidth and energy efficiency relative to electronic counterparts. This aligns with pixel-oriented inputs, as images inherently suit photonic transmission and parallel computation.
Queries could be ingested as rasterized representations, such as screen captures or synthetically generated visuals, with textual outputs for human interpretability. Output generation in pixel form remains challenging due to the complexity of synthesizing coherent images, yet exploratory prototypes of vision-exclusive interfaces suggest feasibility for specialized applications, including real-time environmental interpretation.
1 of 2

2 of 2
Economic Implications: Quantifying Monetary Savings
The adoption of visual compression techniques in LLMs can lead to significant cost reductions by minimizing the number of tokens processed, thereby lowering computational requirements.
For training large models, where compute expenses dominate, estimates place the cost of frontier LLMs like GPT-4 at over $100 million, with some reports citing $78 million specifically for computational resources.
By compressing input data 10-20 times, the effective context length shortens proportionally, potentially reducing training compute needs by a similar factor.
This could yield savings of $50-90 million per training run for equivalent model scales, assuming baseline costs of $100 million, as fewer GPU-hours are required for processing compressed datasets. Inference costs also benefit; with average LLM queries costing fractions of a cent but scaling to billions, a 10x efficiency gain could lower operational expenses for high-volume services from millions to hundreds of thousands annually.
Also, integrating photonic processors, which offer 10-100x cost efficiencies through reduced energy and hardware demands, amplifies these savings, potentially cutting data center operational budgets by 50-90% for AI workloads.
Environmental Impact: Energy Conservation Metrics
Energy consumption in AI remains a critical concern, with training a model like GPT-3 requiring approximately 1,287 megawatt-hours (MWh)—equivalent to the annual electricity use of 120 average U.S. households—and GPT-4 escalating to over 50,000 MWh due to its scale.
Visual input paradigms mitigate this through compression, enabling up to 90% energy reductions via optimized model architectures and quantization techniques that align with pixel-based processing. For instance, a 20x compression ratio could slash energy use by 80-95% for long-context tasks, saving 1,000-40,000 MWh per training cycle for large models.
Photonic integration further enhances efficiency, providing 10-100 fold improvements over electronic systems, potentially reducing AI data center energy demands from terawatt-hours annually to gigawatt-hours, while curbing associated carbon emissions by hundreds of tons per deployment.
These savings are particularly pronounced when digitizing vast historical datasets, where image-based ingestion avoids energy-intensive manual transcription.
Integration with High-Quality Historical Data Archives
This visual input strategy synergizes with efforts to digitize high-protein offline data from the 1870-1970 era, comprising undigitized literature and archival records estimated at exabytes scales.
Such curated, provenance-rich sources—often in printed or analog formats—can be efficiently scanned and processed as images, reducing hallucinations in LLMs by providing dense, accurate training material.
The pixel approach preserves original layouts and artifacts, enhancing model fidelity over tokenized alternatives and accelerating the incorporation of this untapped reservoir into modern AI systems.
When this is tied to Analog AI Attention Rails, you will have a full GPU data center AI compute on a desktop.
The adoption to pixel inputs signifies a foundational reconfiguration in AI data pipelines, fostering denser encodings, streamlined architectures, and scalable photonic integrations.
The world is changing rapidly and we live in increasingly interesting times.

DeepSeek-OCR paper at arxiv.org/abs/2510.04871.
Economic Implications: Quantifying Monetary Savings
The adoption of visual compression techniques in LLMs can lead to significant cost reductions by minimizing the number of tokens processed, thereby lowering computational requirements.
For training large models, where compute expenses dominate, estimates place the cost of frontier LLMs like GPT-4 at over $100 million, with some reports citing $78 million specifically for computational resources.
By compressing input data 10-20 times, the effective context length shortens proportionally, potentially reducing training compute needs by a similar factor.
This could yield savings of $50-90 million per training run for equivalent model scales, assuming baseline costs of $100 million, as fewer GPU-hours are required for processing compressed datasets. Inference costs also benefit; with average LLM queries costing fractions of a cent but scaling to billions, a 10x efficiency gain could lower operational expenses for high-volume services from millions to hundreds of thousands annually.
Also, integrating photonic processors, which offer 10-100x cost efficiencies through reduced energy and hardware demands, amplifies these savings, potentially cutting data center operational budgets by 50-90% for AI workloads.
Environmental Impact: Energy Conservation Metrics
Energy consumption in AI remains a critical concern, with training a model like GPT-3 requiring approximately 1,287 megawatt-hours (MWh)—equivalent to the annual electricity use of 120 average U.S. households—and GPT-4 escalating to over 50,000 MWh due to its scale.
Visual input paradigms mitigate this through compression, enabling up to 90% energy reductions via optimized model architectures and quantization techniques that align with pixel-based processing. For instance, a 20x compression ratio could slash energy use by 80-95% for long-context tasks, saving 1,000-40,000 MWh per training cycle for large models.
Photonic integration further enhances efficiency, providing 10-100 fold improvements over electronic systems, potentially reducing AI data center energy demands from terawatt-hours annually to gigawatt-hours, while curbing associated carbon emissions by hundreds of tons per deployment.
These savings are particularly pronounced when digitizing vast historical datasets, where image-based ingestion avoids energy-intensive manual transcription.
Integration with High-Quality Historical Data Archives
This visual input strategy synergizes with efforts to digitize high-protein offline data from the 1870-1970 era, comprising undigitized literature and archival records estimated at exabytes scales.
Such curated, provenance-rich sources—often in printed or analog formats—can be efficiently scanned and processed as images, reducing hallucinations in LLMs by providing dense, accurate training material.
The pixel approach preserves original layouts and artifacts, enhancing model fidelity over tokenized alternatives and accelerating the incorporation of this untapped reservoir into modern AI systems.
When this is tied to Analog AI Attention Rails, you will have a full GPU data center AI compute on a desktop.
The adoption to pixel inputs signifies a foundational reconfiguration in AI data pipelines, fostering denser encodings, streamlined architectures, and scalable photonic integrations.
The world is changing rapidly and we live in increasingly interesting times.

DeepSeek-OCR paper at arxiv.org/abs/2510.04871.
Generated by Thread Navigator
Press ⌘ + S to quick-export