The growth of LLM context length with time:
- GPT-3.5-turbo → 4k tokens
- OpenAI GPT4 → 8k tokens
- Claude 2 → 100k tokens
- Llama 3 → 128k tokens
- Gemini → 1M tokens
Let's understand how they extend the context length of LLMs:

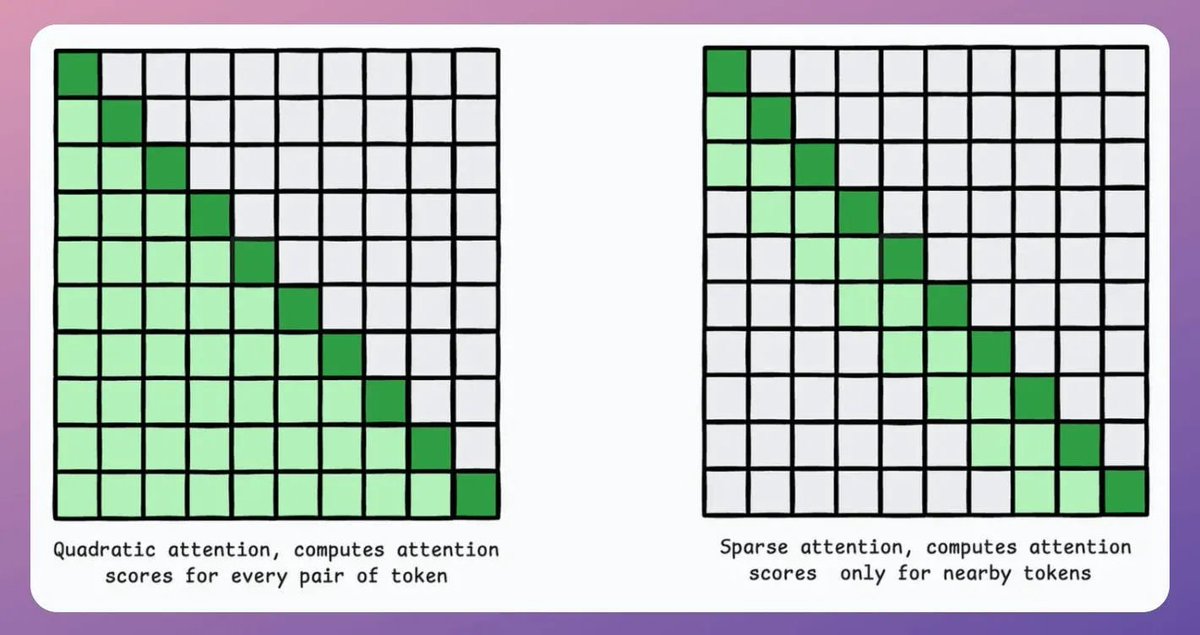
In a traditional transformer, a model processing "8x" tokens requires 64 times more computation (quadratic growth) than one handling "x" tokens.
Thus, having a longer context window isn't just as easy as increasing the size of the matrices, if you will.
Check this 👇
Thus, having a longer context window isn't just as easy as increasing the size of the matrices, if you will.
Check this 👇

1) Sparse Attention
It limits the attention computation to a subset of tokens by:
- Using local attention (tokens attend only to their neighbors).
- Letting the model learn which tokens to focus on.
But this has a trade-off between computational complexity and performance.
It limits the attention computation to a subset of tokens by:
- Using local attention (tokens attend only to their neighbors).
- Letting the model learn which tokens to focus on.
But this has a trade-off between computational complexity and performance.
A similar idea was used in ModernBERT.
It is an upgraded version of BERT with:
- 16x larger sequence length
- Much better downstream performance, and
- The most memory-efficient encoder
They used alternating attention.
Check this 👇
It is an upgraded version of BERT with:
- 16x larger sequence length
- Much better downstream performance, and
- The most memory-efficient encoder
They used alternating attention.
Check this 👇
Here's the idea:
- Use full global attention in every third layer.
- Use local attention otherwise, where a token attends to 128 tokens.
This allows ModernBERT to process longer sequences, while also being significantly faster than other encoder models.
Check this 👇
- Use full global attention in every third layer.
- Use local attention otherwise, where a token attends to 128 tokens.
This allows ModernBERT to process longer sequences, while also being significantly faster than other encoder models.
Check this 👇
Here's an intuitive explanation taken from the paper:
Picture yourself reading a book. For every sentence you read, do you need to be fully aware of the entire plot to understand most of it (full global attention)?
Or is awareness of the current chapter enough (local attention), as long as you occasionally think back on its significance to the main plot (global attention)?
In the vast majority of cases, it’s the latter.
Picture yourself reading a book. For every sentence you read, do you need to be fully aware of the entire plot to understand most of it (full global attention)?
Or is awareness of the current chapter enough (local attention), as long as you occasionally think back on its significance to the main plot (global attention)?
In the vast majority of cases, it’s the latter.
2) Flash Attention
This is a fast and memory-efficient method that retains the exactness of traditional attention mechanisms, i.e., it uses global attention but efficiently.
The whole idea revolves around optimizing the data movement within GPU memory.
Let's understand!
This is a fast and memory-efficient method that retains the exactness of traditional attention mechanisms, i.e., it uses global attention but efficiently.
The whole idea revolves around optimizing the data movement within GPU memory.
Let's understand!

Some background details:
- A thread is the smallest unit of execution.
- Several threads form a block.
Also:
- Threads in a block share a fast (but scarce) memory called SRAM.
- All blocks share a global memory called HBM (abundant but slow).
Check this 👇
- A thread is the smallest unit of execution.
- Several threads form a block.
Also:
- Threads in a block share a fast (but scarce) memory called SRAM.
- All blocks share a global memory called HBM (abundant but slow).
Check this 👇

Attention moves large matrices between SRAM and HBM:
To compute QK:
- distribute matrices to threads
- compute, and
- send the product to HBM
To compute softmax:
- distribute product to threads
- compute, and
- send output to HBM
Repeat for all layers.
Check this 👇
To compute QK:
- distribute matrices to threads
- compute, and
- send the product to HBM
To compute softmax:
- distribute product to threads
- compute, and
- send output to HBM
Repeat for all layers.
Check this 👇

Flash attention involves hardware-level optimizations wherein it utilizes SRAM to cache the intermediate results.
This way, it reduces redundant movements, offering a speed up of up to 7.6x over standard attention methods.
Check this 👇
This way, it reduces redundant movements, offering a speed up of up to 7.6x over standard attention methods.
Check this 👇

That's a wrap!
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
View Tweet
Generated by Thread Navigator
Press ⌘ + S to quick-export