Web scraping will never be the same!
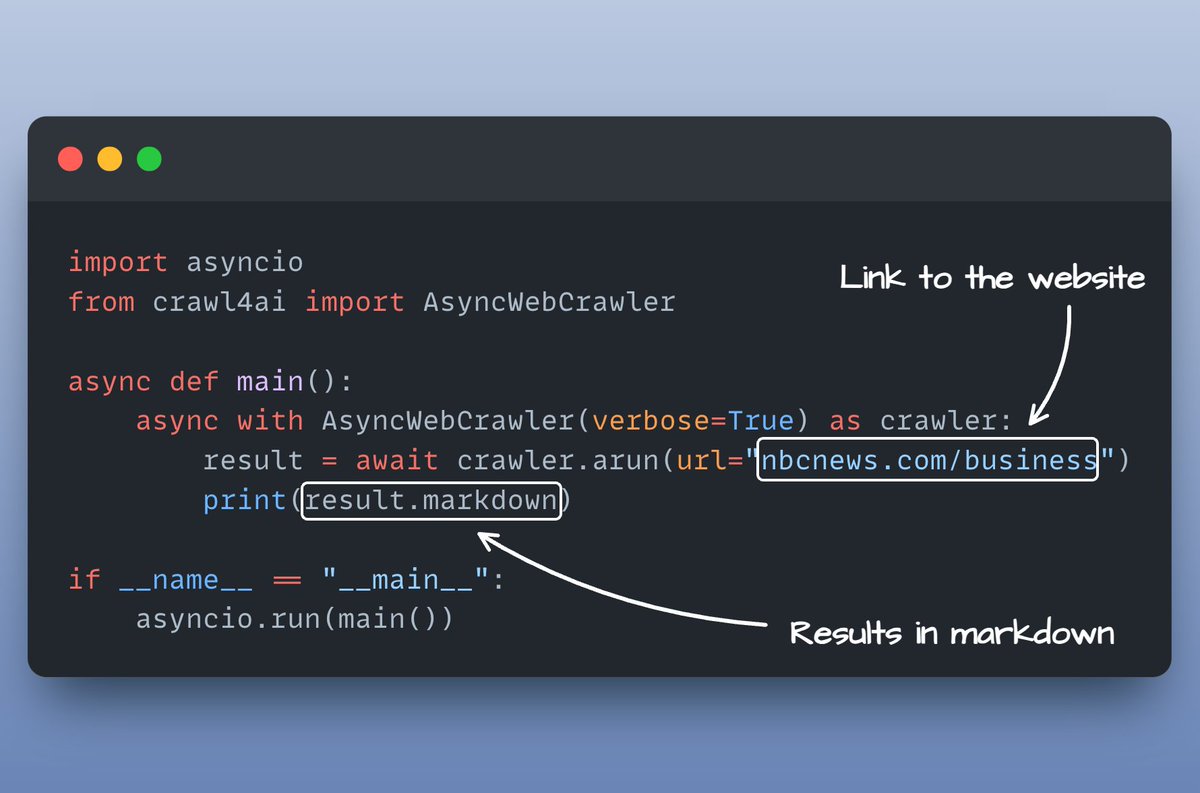
Crawl4AI simplifies web crawling and data extraction, making it ready to use for LLMs and AI applications.
Here’s why it’s a game-changer:
🆓 Completely free and open-source
🚀 Blazing fast performance, outperforming many paid services
🤖 LLM-friendly output formats (JSON, cleaned HTML, markdown)
🌍 Supports crawling multiple URLs simultaneously
🎨 Extracts all media tags (Images, Audio, Video)
🔗 Extracts all external and internal links
But that’s not all:
📚 Extracts metadata from pages
🔄 Custom hooks for auth, headers, and page modifications
🕵️ User-agent customization
🖼️ Takes screenshots of pages
📜 Executes custom JavaScript before crawling
Link to the GitHub repo in next tweet!
_____
Find me → @akshay_pachaar ✔️
For more insights & tutorials on AI and Machine Learning.

GitHub repo: github.com/unclecode/craw…
Generated by Thread Navigator
Press ⌘ + S to quick-export