
How LLMs understand relative positions of input words, clearly explained:
RoPE (Rotary Positional Embeddings) revolutionised the way positional information is encoded in LLMs and it's widely used by models like Llama-3.
Today, I'll clearly explain what they are & how positional embeddings evolved over time.
Let's go! 🚀
Today, I'll clearly explain what they are & how positional embeddings evolved over time.
Let's go! 🚀

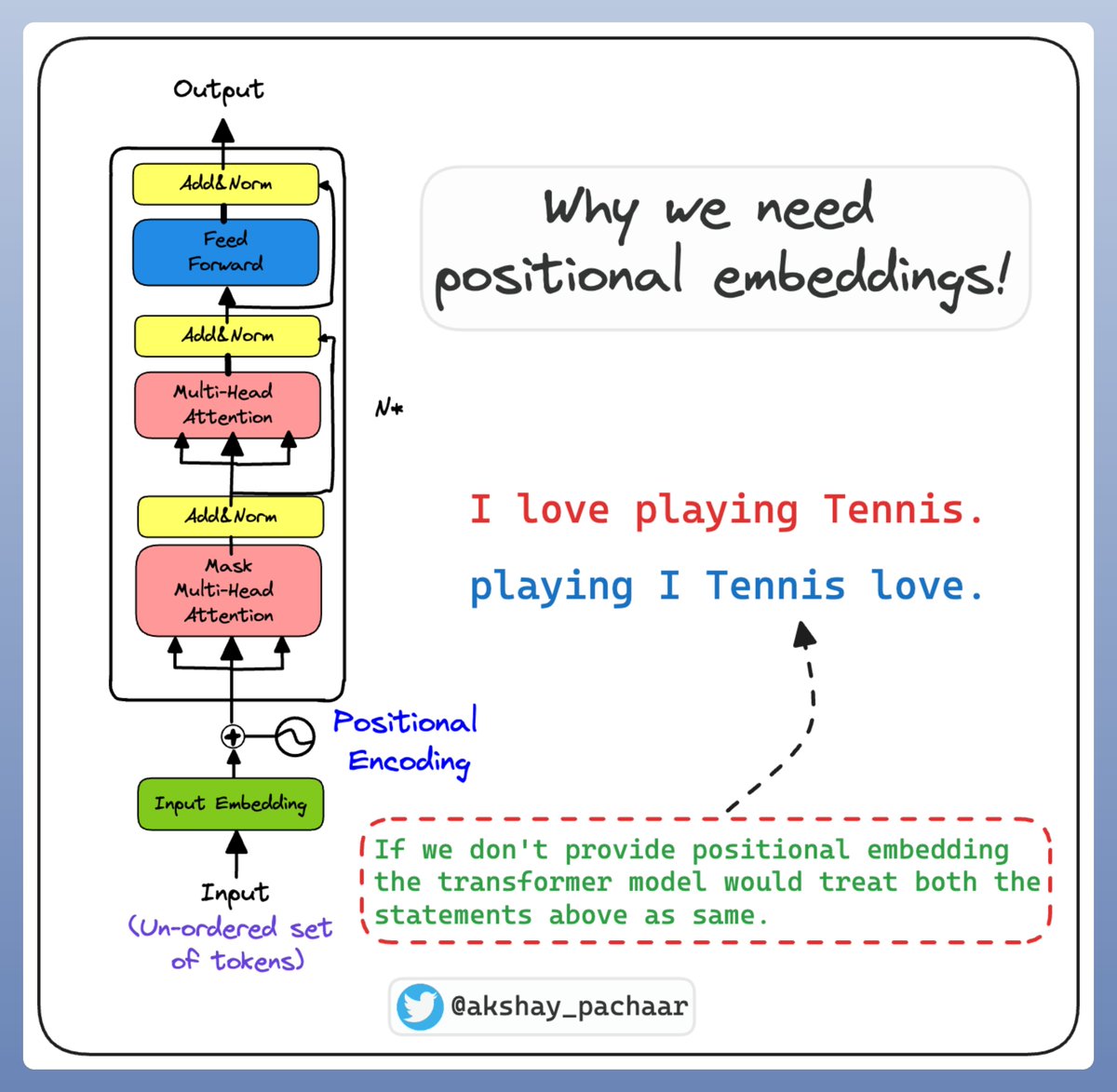
Why Positional embeddings❓
Let's first understand the concept of positional embeddings and why they are essential in the first place.
Without positional embeddings a transformer doesn't understand the relative arrangement of words in a sentence.
Let's first understand the concept of positional embeddings and why they are essential in the first place.
Without positional embeddings a transformer doesn't understand the relative arrangement of words in a sentence.
Absolute Positional embeddings
So, let's start with the simplest way to encode position of tokens (words) in an input.
So, let's start with the simplest way to encode position of tokens (words) in an input.

Problem with absolute positional embeddings! ⚠️
Each positional embedding is independent of each other, they don't capture relative arrangements/positioning.
Check this out👇
Each positional embedding is independent of each other, they don't capture relative arrangements/positioning.
Check this out👇

Next up, let's talk about relative positional embeddings!
They definitely overcome the limitations of absolute positional embeddings, but they come with the drawback of increased parameters.
For a sequence of length N, we require 2N+1 positional embeddings.
They definitely overcome the limitations of absolute positional embeddings, but they come with the drawback of increased parameters.
For a sequence of length N, we require 2N+1 positional embeddings.

Introducing Rotary Positional Embeddings (RoPE), the best of both worlds!
Instead of adding a token & its positional embedding, we rotate the token embedding by a fixed factor (theta) depending on its position in the sequence.
Imagine our token embeddings are 2-dimensional!
Instead of adding a token & its positional embedding, we rotate the token embedding by a fixed factor (theta) depending on its position in the sequence.
Imagine our token embeddings are 2-dimensional!

RoPE preserves relative position and relation.
For example, in the scenario below, the embedding vectors for the words 'love' and 'Tennis' will have the same cosine similarity as long as their relative positions stay the same, regardless of the sequence length.
Check this out👇
For example, in the scenario below, the embedding vectors for the words 'love' and 'Tennis' will have the same cosine similarity as long as their relative positions stay the same, regardless of the sequence length.
Check this out👇

Mathematical representation.
This can be easily generalised to N dimensions by taking a pair at a time.
(I have also shared my detailed blog on self-attention at the end)
Check this out👇
This can be easily generalised to N dimensions by taking a pair at a time.
(I have also shared my detailed blog on self-attention at the end)
Check this out👇

If you interested in:
- Python 🐍
- ML/AI Engineering ⚙️
1. Find me → @akshay_pachaar ✔️
2. Subscribe to our Newsletter → @DailyDoseOfDS_ and get a FREE eBook, covering 150+ core DS/ML lessons!
Cheers!
- Python 🐍
- ML/AI Engineering ⚙️
1. Find me → @akshay_pachaar ✔️
2. Subscribe to our Newsletter → @DailyDoseOfDS_ and get a FREE eBook, covering 150+ core DS/ML lessons!
Cheers!
Generated by Thread Navigator
Press ⌘ + S to quick-export