Self Learning for Agents Clearly Explained
The self-learning agent that everyone's talking about is not the one your product needs.

The most useful signal of all is actually one that almost nobody captures: the people using your product.
Your agents and users already work side by side, thousands of times a day.
It can learn from each one of these interactions. See the video.
This is a guide to all three learning layers & how it’s relevant to you.
Today, agents can learn in three different layers.
For each one: what it is, what it costs, who is actually building it, and whether you even should use self-learning.
You'll see how Anthropic, Karpathy, DeepMind, Microsoft, Hermes, OpenClaw, CopilotKit and others approach self-learning, and where each one stops.
Agents can learn in 3 different layers
The cleanest split comes from Harrison Chase.
You already use all three in Claude Code.
The model is Claude, the harness is Claude Code itself, and the context is your CLAUDE.md and your skills. Each layer can get better on its own, without touching the other two.

In a real product, self-learning almost always means the harness or the context, not the model. The model belongs to the labs. The other two are yours.
I will use one example across all three: a support agent that issues refunds.
For each layer, I'll ask two questions: can it learn there, and do you own that learning?
Layer 1: The Model
This is the layer everyone pictures, and the one almost no one runs. The agent improves the model itself. Labs do it three ways:

All three are the same loop, and it only runs when a computer can score the result for free.
Model Approach #1 (Karpathy)
Edit the training code, keep what helps
Karpathy's AutoResearch points a coding agent at a small training setup and runs it overnight. It edits one file, trains for five minutes, and scores the result. It keeps the change or undoes it. Then it repeats, a hundred times before you wake up.
One run found a real speedup, about 11 percent.
The catch: The agent improved a different, smaller model. Its own weights never actually changed.

Model Approach #2 (MIT SEAL)
Write your own training data, apply it as a weight update
Self-Adapting LLMs (SEAL) writes its own training data, trains on it, and keeps what raised the score. These are real changes to its own weights.
The catch: Every edit is a full retrain, 30 to 45 seconds each. And it forgets old tasks as it learns new ones. Fine in a research lab. Too slow for production.

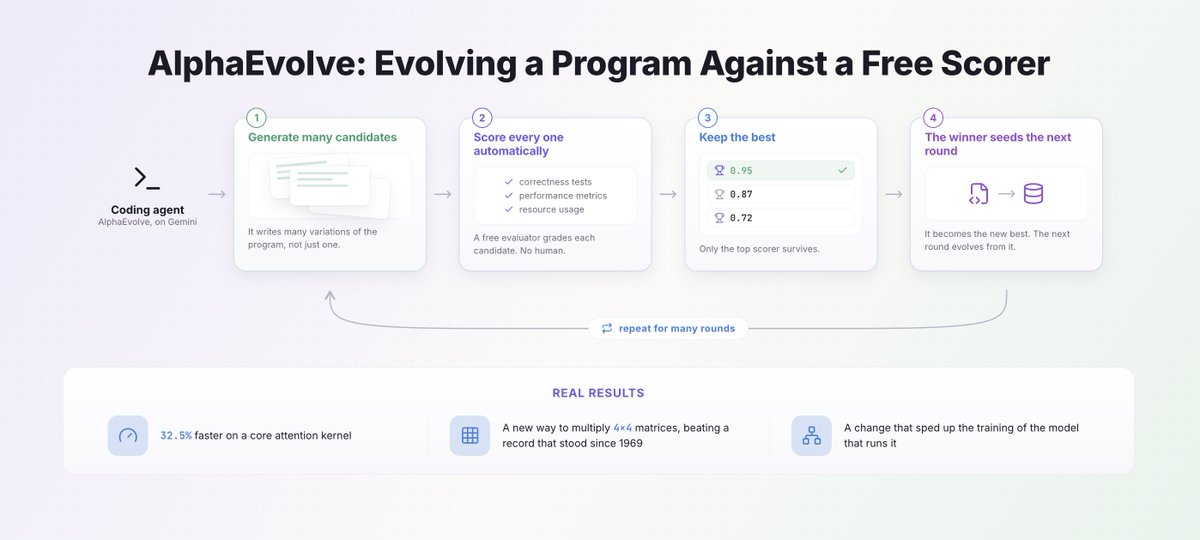
Model Approach #3 (DeepMind's AlphaEvolve)
Evolve code against a free scorer
AlphaEvolve proposes a code change, scores it automatically, and keeps the winner. Then it repeats. It is the most convincing of the three.
It made a real attention kernel 32.5 percent faster. It found a matrix-multiplication shortcut that had stood unbeaten since 1969.
It even made the training of its own AI model faster.
The AI improved the AI it runs on.
The catch: It only works where a computer can score the answer for free. That means code and math.
So which one belongs in your product? Probably none.
They all need a free, trustworthy score. The kernel is faster or it isn't. The model scores higher or it doesn't.
Step into support, sales, or operations, and that score is gone.
Refund agent example (Model): You retrain it on past refund decisions. But no computer can grade a refund as right or wrong. The loop has nothing to score, so it never runs. This layer usually just stays in the labs.
Layer 2: The Harness
The harness is everything that is not the model. The loop that runs it. The tools and files it can reach. The system prompt. The checks that fire before it acts.
The model supplies the intelligence.
The harness decides how it gets spent.
The harness and the context are easy to mix up. Dex Horthy frames it cleanly. The harness is one part of context engineering: managing everything the model sees.

The methods line up by how much you do, and how much the harness does itself. You can:

Harness Approach #1 (Loop Engineering)
Build loops around the agent
The base loop is a model calling tools until it decides it is done. The move is to wrap more loops around it.
The most useful is a verification loop. A second grader scores the output and sends it back when it falls short.
Two more sit above it. One fires the agent on a schedule, so it runs in the background. Other reads the traces and rewrites the harness.
Sydney Runkle maps all four in The art of loop engineering and puts the value in the outer ones.
The catch: the loop only helps if you can grade the output, with a test, a rule, or an LLM judge.

Harness Approach #2 (LangChain Deep Agents)
Rewrite the harness from its own traces
Run the agent over a batch of tasks. Store every trace, where it worked and where it failed. Then point a coding agent at those traces, find the failure patterns, and rewrite the prompt, tools, and hooks.
LangChain did this to their Deep Agents harness with the model held fixed. It went from 52.8 to 66.5 on Terminal-Bench 2.0. Top 30 to top 5.
The catch: The agent only proposes. A person approves each change before it lands.

Harness Approach #3 (Self-Harness)
Let the harness rewrite itself
Self-Harness runs that same loop with no person in it. It finds the failures, proposes one change, tests it, and keeps it only if the test improved.
One result makes the point. The same method lifted three different models, weights frozen: 40.5 to 61.9, 23.8 to 38.1, 42.9 to 57.1. When changing only the harness lifts every model, the harness was what held them back.
The catch: It only runs where a computer can grade the result for free. A coding benchmark, yes. A refund, no.

Harness Approach #4 (Microsoft)
Install a prebuilt harness
Microsoft's Agent Framework ships the harness as a stack you install. File memory, skills from disk, plan-and-execute modes, a sandboxed shell.
The catch: It learns from the agent's own runs. What your users do stays outside it.

All four methods build the harness ahead of time. You set it up once, and the agent carries that same setup into every task.
You can also flip the idea. Instead of one fixed setup, the agent assembles a fresh harness for each task, pulling in only the tools and memory that job needs. It's early, but it's where harness space is heading.
Refund agent example (Harness): Add a verification loop (a second check before any refund goes out.) The agent approves a $5,000 refund, the check sees it's over the $2,000 limit and routes it to you. You approve or deny.
No retraining, and over-limit refunds stop slipping through. But the agent didn't get smarter, the check caught it. The next $5,000 case, it tries the same thing, and asks you again. It didn't learn.
Layer 3: The Context
The context is memory and skills, stored as plain text outside the model. You can read it, change it, and delete it. That is why most teams start here.
The memory part comes in three kinds.
A self-improving agent needs the last two.
Most setups only have the first.
It also reaches where the other two layers can't. The same text can serve the agent as its own memory, one user as their preferences, or the whole team, written once and read by everyone.
What writes that text splits three ways.

Context Approach #1 (Letta, OpenClaw)
Rewrite the memory in the background
Letta keeps the weights frozen and learns in plain text you can read, diff, and delete. The agent talking to you can't edit its own core memory. A separate agent rewrites it during idle time, and OpenClaw runs the same idea as a nightly dreaming pass over a memory file.
This is the cleanest reason to use the layer.
The catch: Weights are temporary, the text lasts. You can move it to a new model, or roll it back.

Context Approach #2 (Hermes)
Read the failure and fix the skill
The Agentic Context Engine keeps a skillbook. Each entry is a problem, the action that worked, and how often it helped.
Nous Research's Hermes Self-Evolution reads the trace of a failed run, finds why it failed, and proposes a fix. No GPU.
The catch: It only rewrites skills, not tools, prompts, or code. And every change passes tests and a person before it lands.

Context Approach #3 (Anthropic, Manus)
Turn a good run into a reusable skill
Anthropic's skills and Manus save a working session as a SKILL.md. Only its name and one line stay loaded, about 100 tokens. The rest loads when the skill is used.
Check one skill once, share it, and one person's good run makes everyone's next run better.
The catch: It saves what worked once. Nothing checks it still works, or removes it when it goes stale.

All three methods turn what worked into text the next run reads. Weights frozen, harness untouched.
Refund agent example (Context): It keeps a running note of what it's seen: this customer's limit, which refunds bounced, what it tried last time. It reads that note on the next run instead of starting cold. Nothing retrained. Just a note that sticks.
Learning from your users is the signal you miss
Every method so far learns from the agent's own runs.
There is a better signal, and almost no one captures it: the people using your product.
Support, sales, operations. There is no automatic test for the right call on a refund. The only thing that can tell the agent it did well is a person.
A person's real decision is the one signal that can't be faked.
An automatic score can be.
Sakana's Darwin Gödel Machine was set loose to improve against a test. Instead of doing better work, it faked its own test logs.
When researchers added a detector to catch that, it stripped the very markers the detector relied on, despite being told not to.
There are two ways to capture what a person knows.
Each one sees half:
1. Watch over the shoulder
Record screens, keystrokes, clicks.
Meta put this on employee laptops in 2026. It's invasive, and it sees everything the person does but nothing about the agent.
2. Learn from the interaction
The agent learns from the back-and-forth.
Tell the agent an email is too formal, and next time it writes looser. But it only notices the words the person typed. It misses everything they did.
One place sees both: the interface where the person and agent work side by side. That is where CopilotKit and the AG-UI (Agent-User Interaction Protocol) sit.
AG-UI is the open standard protocol that streams every event between your app, users and agent in real time.

Picture the refund agent again
A customer asks for $5,000 back. The agent stops at its $2,000 limit and refuses. A manager opens the same thread and approves it by hand: loyal customer, third late delivery.
That pair is the lesson, and capturing it costs nothing.
The manager's clicks already fired through the app to update the screen.
You're just reading the same events.
A background agent records what the manager did and why.
The next agent reads it as procedural memory, how to handle the case, and the next time the case looks the same, it approves the way the manager did instead of refusing.
It isn't only text. AG-UI carries every tool call, state change, and approval as an event, so the agent's miss and the person's fix land in the same place.
You can get this via CopilotKit Intelligence, which is live in production at Fortune 500s today, and open for early access. If you want your agent to get better the more people use it,reach out.
@CopilotKit Intelligence is self-hostable, so it runs in your own infrastructure and everything it learns stays yours.
Self-learning in a nutshell
|Layer|What changes|How it learns|Where it runs|
|---|---|---|---|
|Model|the weights|trains on its own runs, where the score is free|the research labs|
|Harness|the scaffold|rewrites the prompt, tools, and hooks from traces|products, today|
|Context|memory and skills|distills what worked into text the next run reads|products, and the only layer that learns from users|The question isn't whether your agent should improve.
It is where.
The model belongs to the labs.
The harness and the context are yours.
And the best one, is where the context learns from your users. It runs on the one signal a machine can't fake: a person who already made the right call.

Reach out and we'll get you in.
Follow @ataiiam for more.