How Quants Use Loop Engineering to Build Alpha (Full Framework)
Your backtest looked flawless. You went live. Two weeks later, the strategy was bleeding. Every quant has lived this. The answer is a loop: generate a strategy, test it, score it, feed the result back, and run it again until one survives out-of-sample.

Let's get straight to it.
Bookmark this. We are the team behind Horizon, the platform that lets you type a trading strategy in plain English, backtest it in minutes, and deploy it live to your exchange. Loop engineering is the method behind that flow. Currently in closed beta. Join the waitlist at horizon.trade or DM @horizon_trade_x for early access.
That strategy died because it was one guess with nothing iterating on it. A single pass gives you a single attempt, and the first attempt is rarely the edge. The loop turns that one attempt into a search: each round keeps the variants that scored well and feeds the rest back in for refinement. We are going to break down how that loop works, the math that closes it, and the one step that separates a real edge from faster overfitting.
Here is the roadmap:
Why one-shot prompting stalls
A single prompt gives you a single guess. The model returns a generic factor, you backtest it, and it usually fails, because the first idea is rarely the edge. Without a loop, every attempt starts from scratch and nothing compounds. The whole edge is in the iteration, and one-shot prompting has none of it.
What loop engineering actually is
Loop engineering is a closed cycle: generate a hypothesis, test it, score it against a clear objective, read why it failed, and feed that back into the next generation. The shape is perceive, reason, act, observe, repeat. Each pass is cheap, and the system gets sharper because every result narrows the search. What matters is the process, because it turns dozens of mediocre attempts into one that holds up. This is the loop we built Horizon to run end to end.
The metric that closes the loop
A loop without a scoring function just wanders. The standard objective in factor research is the information coefficient: the correlation between a factor's values today and the returns that follow, IC = corr(factorₜ, returnₜ₊₁). A single IC reading is noisy, so the number that actually matters is its consistency over time, the ICIR: ICIR = mean(IC) / std(IC). A factor with a modest but steady IC beats a flashy one that works once and breaks. The ICIR is what the loop optimizes toward.
The decay check most people skip
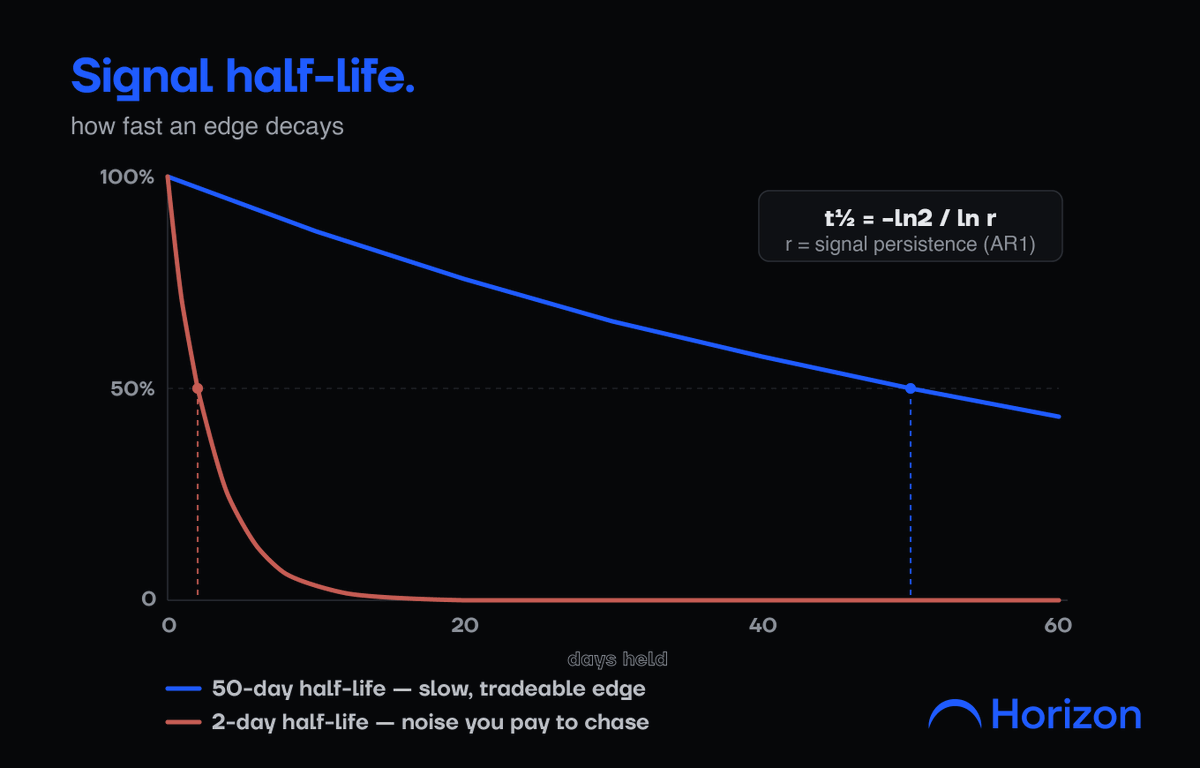
Even a real factor has a shelf life. You can measure it: fit the signal's persistence as an AR(1) process and read its half-life, t½ = -ln(2) / ln(ρ), where ρ is how strongly the factor carries from one period to the next. A half-life of 50 days is a slow, tradeable edge. A half-life of two days means you are paying costs to chase noise. A good loop rejects short-half-life factors automatically.
The step that separates edge from overfitting
Here is the part the hype skips. A loop that optimizes on the same data it was built on does not find alpha faster. It finds prettier noise faster. Every extra iteration is another chance to fit the past. The only thing that turns a loop into a research engine is an out-of-sample gate: each surviving candidate gets tested on data it never saw, and the ICIR has to hold there too. Count your attempts honestly, because the more variants you try, the higher your bar should climb. Skip this, and loop engineering is just automated curve fitting.

Where Horizon runs this loop
This is the cycle Horizon is built around, with every beat handled in one flow. You describe a strategy in plain English, and instead of one answer, it proposes a few variants to compare

It backtests each, scores them on what matters (returns, Sharpe, drawdown), and shows you what held and what broke.

You read the failures, refine, and run it again. When a candidate looks real, it gets gated on out-of-sample data before anything goes live, and only then is it deployed to your exchange. The generate, test, score, refine, deploy loop that a quant desk runs by hand, in one place, with the honest steps kept in. Type it, test it, keep what survives.
How traders get loop engineering wrong
Looping on in-sample data. Faster iteration on the same history just overfits faster. The loop needs fresh data at the gate.
Running with no scoring function. Without a clear objective like ICIR, the loop optimizes for nothing and drifts.
Chasing high IC, ignoring stability. One great month of IC is wearing a costume. Consistency is the edge.
Mistaking the model for the method. A better model speeds up generation. The loop, the scoring, and the out-of-sample gate are what actually produce alpha.
The checklist
Define the objective before you start: IC and ICIR on a held-out window. Generate a handful of variants each pass. Score every candidate, read the failures, and feed them back. Check the half-life so you trade durable signals. Gate every survivor on out-of-sample data, and raise the bar as your attempt count grows. Keep only what holds.
A model can write a thousand factors.
Only the loop tells you which one was ever real.
Before you go. We are the team behind Horizon, the platform that lets you type a trading strategy in plain English, backtest it in minutes, and deploy it live to your exchange. The loop you run around the prompt is what produces the edge. Currently in closed beta. Join the waitlist at horizon.trade or DM @horizon_trade_x for early access.