@rohanpaul_ai: Taalas launched a beast of a c...
@rohanpaul_ai
56 views
Feb 21, 2026
1
Taalas launched a beast of a chip, boasting insane AI inference performance.
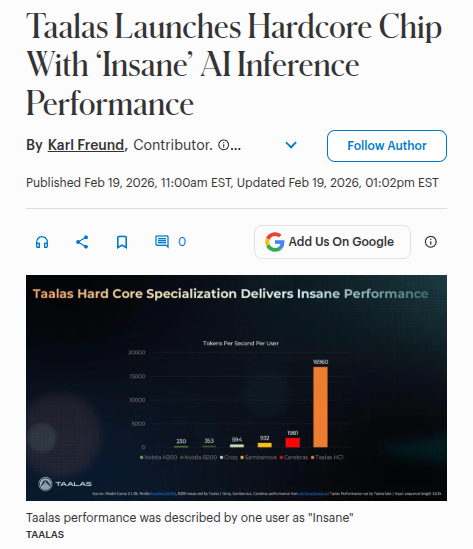
17,000 tokens per second. forbes reports.
About 10x faster than Cerebras wafer-scale engine, currently the fastest inference platform available, for this setting and about 2 orders of magnitude faster than GPUs, but those comparisons depend on matching prompts, batching, and latency targets.
And they just raised $169 mn.
Instead of using software to program (compile) and execute on a GPU or an ASIC such as a Google TPU, Taalas hardwires the model and its weights into a "Hardcore" ASIC (HC1) embedding the entire model into a bespoke application-specific chip.
Result is extreme inference speed and very low cost per token, at the price of giving up most general programmability.
The usual tradeoff in AI hardware is that GPUs are flexible but pay overhead for moving weights through memory and for supporting many different kernels, while ASICs get faster by specializing but still stay somewhat programmable.
It's ASIC HC1 pushes specialization further by “baking in” one target model, currently Meta’s Llama3.1-8B, so the chip is not a general accelerator in the way a GPU or TPU is.
Taalas says HC1 keeps a bit of flexibility via a configurable context window and fine-tuning through low-rank adapters (LoRAs), which add small trainable matrices on top of a frozen base model.
Reported demo numbers include about 0.138s for a long response at 14,357tokens/s, and upto 17,000tokens/s per user for Llama3.1-8B.
On cost and power, the same write-up claims roughly 0.75c per 1M tokens for Llama3.1-8B and 12-15kW per rack versus 120-600kW per GPU rack, with DeepSeek-R1 numbers partly simulated.
A key limitation is operations, because a data center would need different chips for different models and then refresh them as models change, even if Taalas can update by changing only 2 metal layers in about 2 months.
Quality is also a constraint today because the “Silicon Llama” is aggressively quantized with mixed 3-bit and 6-bit weights, and the roadmap points to 4-bit floating point formats on a future HC2 to reduce accuracy loss.
---
forbes. com/sites/karlfreund/2026/02/19/taalas-launches-hardcore-chip-with-insane-ai-inference-performance/
17,000 tokens per second. forbes reports.
About 10x faster than Cerebras wafer-scale engine, currently the fastest inference platform available, for this setting and about 2 orders of magnitude faster than GPUs, but those comparisons depend on matching prompts, batching, and latency targets.
And they just raised $169 mn.
Instead of using software to program (compile) and execute on a GPU or an ASIC such as a Google TPU, Taalas hardwires the model and its weights into a "Hardcore" ASIC (HC1) embedding the entire model into a bespoke application-specific chip.
Result is extreme inference speed and very low cost per token, at the price of giving up most general programmability.
The usual tradeoff in AI hardware is that GPUs are flexible but pay overhead for moving weights through memory and for supporting many different kernels, while ASICs get faster by specializing but still stay somewhat programmable.
It's ASIC HC1 pushes specialization further by “baking in” one target model, currently Meta’s Llama3.1-8B, so the chip is not a general accelerator in the way a GPU or TPU is.
Taalas says HC1 keeps a bit of flexibility via a configurable context window and fine-tuning through low-rank adapters (LoRAs), which add small trainable matrices on top of a frozen base model.
Reported demo numbers include about 0.138s for a long response at 14,357tokens/s, and upto 17,000tokens/s per user for Llama3.1-8B.
On cost and power, the same write-up claims roughly 0.75c per 1M tokens for Llama3.1-8B and 12-15kW per rack versus 120-600kW per GPU rack, with DeepSeek-R1 numbers partly simulated.
A key limitation is operations, because a data center would need different chips for different models and then refresh them as models change, even if Taalas can update by changing only 2 metal layers in about 2 months.
Quality is also a constraint today because the “Silicon Llama” is aggressively quantized with mixed 3-bit and 6-bit weights, and the roadmap points to 4-bit floating point formats on a future HC2 to reduce accuracy loss.
---
forbes. com/sites/karlfreund/2026/02/19/taalas-launches-hardcore-chip-with-insane-ai-inference-performance/
2
"Here’s a view of the economics afforded by the Hardcore approach. Inference queries for a single model cost 0.75 cents per million tokens for Llama 3.1 8B and 7.6 cents for the DeepSeek R1 reasoning model. The Llama results have been measured on the first-generation silicon, while the DeepSeek results are simulated. Compare that to 3.79 and 28.6 cents (throughput and latency optimized, respectively) and 20-49 cents for GPUs for Llama 8B and DeepSeek R1, respectively."

3
Taalas HC1 PCIe cards can be installed in virtually any server, and supports both Intel and AMD CPUs.

4
The downside is customers end up carrying several generations of a hardened model over time, plus multiple versions so they can run different models. No data center organization wants that many Stock Keeping Units in the mix; the operational complexity is almost unreal. But the economics still look compelling.
If a data center only depends on a small set of models that soak up most of its production AI inference cycles, the economics might come out very nicely. And that’s putting it mildly.
If a data center only depends on a small set of models that soak up most of its production AI inference cycles, the economics might come out very nicely. And that’s putting it mildly.

5
AGI will be 1 the biggest turning points in human history, on the level of fire or electricity. It could bring 10X the impact of the Industrial Revolution, at 10X the speed
Demis Hassabis, the DeepMind CEO & founder of GoogleDeep Mind
Demis Hassabis, the DeepMind CEO & founder of GoogleDeep Mind
View Tweet