@Dr_Gingerballs: I wanted to put all of my crit...
I wanted to put all of my criticisms of AI as a potential replacement for humans into one place so people can understand how I evaluate new information about this space, and hopefully be able to critically evaluate things themselves.

What is AI?
There is no agreed upon definition of intelligence, and thus there is no rigorous definition of the artificial variety. Artificial intelligence is a marketing term coined by Assistant Professor John McCarthy in the 1950s in an attempt to "zazz up" his research funding requests. Vaguely, this area of research aims to develop computer systems that can learn, reason, perceive the external world and respond to it, pursue goals, etc. It essentially aims to recreate the human (which would make the creators a "god" of sorts).
I think a better way to define AI is based on what researchers are doing in the field, not what their aim happens to be. In that regard, most of the research involves developing algorithms to optimize some objective function. Imagine you are standing in a valley, surrounded by hills and mountains. Your task is to find the tallest peak. Now you may think this is simple: just look for the highest point and walk to it. Once you get there, look for yet higher points and then walk there. Keep going until you don't see any higher points. Or even better, just look at the map on your phone, locate the highest point, and walk directly to it.
This is great if you have an easy way to measure the landscape: your eyes, your phone map, etc. But this requires two things: 1) a way to acquire lots of data about the landscape (your eyes), and 2) the capacity to store and read all of the data. Further, you also need an efficient strategy to get from where you are to your objective. In practice, accomplishing these 3 things in a general sense is very hard to do.
So AI is the field of optimizing the traversal through a parameter space to reach an optimum. This optimum can be a wide variety of things: searching for websites, assembling a car, getting driving directions, etc. In this sense, the applications of AI are unbelievably broad, making it a hard field to talk about. AI means something different to many different people, but at the core is task optimization.
So to recap, to accomplish efficient task optimization you need:
Statistics Disguised as Intelligence
With few exceptions, most of the AI strategies to accomplish the 3 task optimization requirements are statistical (expert systems were a notable exception, using large if-then statement algorithms).

Although statistics are great at giving you uncertainty information about a prediction, they are expensive (require a lot of data) and require a strong "expected" behavior, or average.
Think of a normal distribution, which measures the probability that some outcome will occur. The peak is the most probable event, which in this case is both the median and the average value. Given no other information, you would expect to get that value most of the time. Given the shape of the curve, you can also predict the probability that less common outcomes will occur. The key here is that, given the model, you can predict a range of outcomes for a given event.

This brings me to my first criticism of statistics as AI:
Criticism 1: If the future is not normally distributed, statistics will never be able to predict it.
I'm not sure how to hammer this point home harder. This is the assumption on which the entire AI field currently rests. It's the foundation of sand, or the rug waiting to be pulled. There is no universal rule that requires that the future be statistically predictable, and in fact, lots of evidence exists to suggest it is not.
A great place to look is in the financial markets. People have been trying to apply statistics to accurately predict market returns for decades. One universal truth is that it rarely works, and when it does, it doesn't work for very long.
The reason for this is simple: the financial markets are largely made up by actors who themselves are not statistical. Humans are superstitious and causal. We are so superstitious that we created something called "technical analysis," where people look for patterns in the chaos and ascribe outcomes to them. And in fact, so many people use these patterns, they start to become actual predictive tools. This is the equivalent of looking into the heavens and seeing a horse or a crab in the stars (and actually the constellations we have created are one of the most bizarre features of our intelligence I can think of).
So if humans are not statistically driven, the output of humans cannot be predicted by statistics. This is true for art, driving, financial markets, social connection, etc.
Anything that requires human decision making cannot be completely captured by statistics, because we do not appear to be statistical.
Then the natural criticism to my statement is that many human behaviors and actions can be approximated using statistics. Also, the rules governing the universe at the atomic level are statistical. The line of thought then is "if the fundamental building blocks of the universe are statistical, how can anything emerge that is not statistical?"
I do not have an answer to this question, nor do I think you need one to call statistical AI a dead end. Even if humans are computable, they don't appear to be computable, meaning we lack the fidelity and throughput to decompose human behavior into a series of computable processes. We are millennia away from, for example, figuring out how your specific DNA causes some population of your proteins to fold in a particular way, which determines how much you cry as a baby, which determines how caring your mother is, which cascades into a string of endless "tipping points," which eventually determines why you were likely to choose to have lasagna for dinner tonight.
I asked ChatGPT to illustrate my point by superimposing enough normal distributions to create a horizontal line. It couldn't do it, but this, I hope, gets my point across well enough. As many normal distributions are bunched closer and closer together, the prediction starts to get "lumpy" and "broad." As you continue this process, eventually you would get a flat surface, which seemingly has no expected value. So while my decision to have lasagna may be composed of a huge set of computable events, all I see is a flat surface, and so I cannot work backwards from the observation that I had lasagna for dinner to determine my genome.
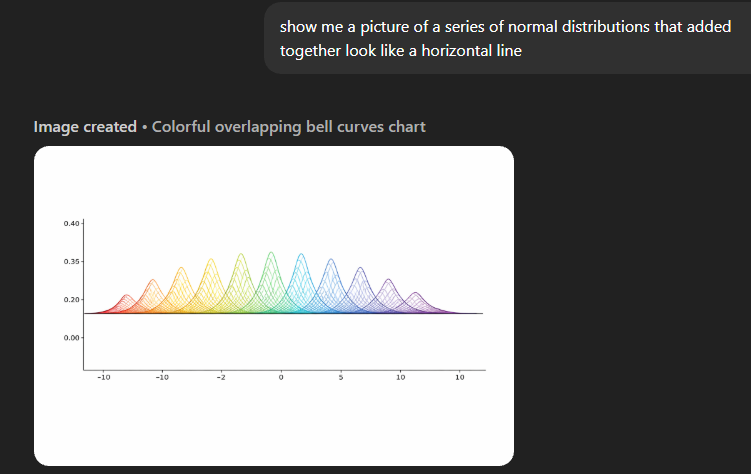
This brings me to my second criticism of AI...
Criticism 2: Observing human output can never uncover the nature of human intelligence.
This criticism is why all statistical AI output from general models like ChatGPT seemingly output things that the kids might call "mid." All of these models apply statistics to human output, inevitably producing "something that looks like a human output but never quite right and never exceptional."
This outcome is not a limitation of the implementation, it's a limitation of the basic assumptions baked into the strategy itself. It cannot be fixed with more data and better statistical models. Using any statistics at all to describe human outputs is the source of the problem. Thus, training these models on human output will never lead to a human like intelligence. It will always be relegated to a mere mimic, a shadow of the thing it wants to achieve. It will always be a parlor trick.
LLMs are a great example of this. The most surprising insight from training these models is that human speech output is statistical. But that does not mean that the statistics observed are able to uncover the underlying structure that lead to written communication. Like the overlapping gaussians above, we are seeing the statistics of the aggregate output of all humans, but not the statistics of the underlying fundamental processes. And we never can by only training on output.
The only hope that statistical methods have for creating human like intelligence is to train on human inputs and the corresponding outputs. But as we will see in my third criticism, this is not at all practical.
Importantly, this issue shows up in things like Tesla Full Self Driving and Google DeepMind AlphaFold, where the size of the outputs they were trained on was so massive, they appear to accurately predict the domains they sought to optimize. But because they are seeing only the result of the underlying mechanisms, they always seem to struggle when met with rare events.
The solution to rare event handling in a statistical framework is, of course, MORE DATA. Which leads me to my third criticism of statistical AI and the title of this piece...
Criticism 3: Capturing variance statistically blows up as models become more general.
A well known relationship in statistics is that the number of samples required to increase confidence goes up with the square of your confidence level. This makes creating highly confident models of anything very expensive.
By contrast, humans require much fewer data points to marginally increase their confidence. Why this is so is still a mystery, but it is why our general intelligence runs on 20-100 W (and why we are so terrible at mental statistics). This observation was the motivation for creating the ARC Prize, where models are only given a few sample transformations and are asked to generalize it. Inevitably, models exposed to a problem for the first time do terribly at it, because they cannot rely on statistics alone to capture the transformations occurring. Now the models always do better over time, which is something I'll get into later on (training on the test), but it's important to note they all do very badly at first.
So we have a situation where statistical intelligence does not scale competitively to human intelligence. This can be summarized in the following simple chart.
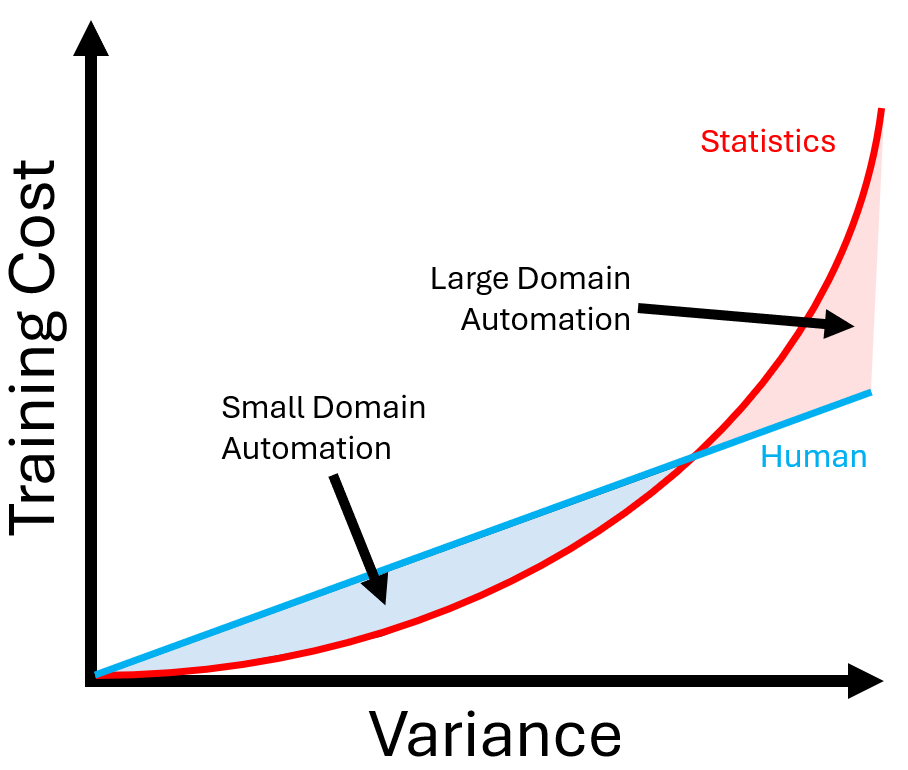
When variance is small, i.e. the situation is well controlled, it can be very cost effective to train a statistical model. Think of a machine arm that sprays insulation into the shell of a fridge on a conveyer belt. Or a robot arm that welds two pieces of a car frame together. The variance is highly controlled, and the robot is very economical to train. This has been the dominant value proposition of the automation age, and what has already eliminated most human jobs that can be eliminated.
But now that the low hanging fruit is gone, automation folks are trying to expand the variance envelope that robots can tolerate to more closely match a human. Yet progress here is slow because the training required to expand the variance grows quadratically. More data, more control, more cost, in a way that explodes quickly relative to humans. Again, the problem here is that all of AI is supported by statistical methods, which do not scale.
Does this mean automation is over? Not at all, but it will inevitably be slower. Thus, we have entered an economic regime where automation delivers diminished returns, which is not good for productivity growth. We have already thrown an ungodly amount of money at this problem trying to scale it to general automation and no one can really describe what the transformative impact actually has been.
LLMs, and statistical generation methods in general, have the same problem. When variance is tightly controlled (like answering the question "how many r's are in strawberry?"), it's trivial to create a statistical algorithm that nearly always returns the correct value. But creating a generative model that is general and accurate is extremely costly. This is why hallucinations are a problem with generative models and always will be. They can never anticipate all future possible requested outputs statistically.
The strategy then has shifted to "post-training," where they essentially latch on iterative modules to the models that allow them to guess an answer over and over and get feedback. But this is only effective where there is a known "correct" answer which has been given to the model beforehand. For example, code something that takes x and makes y can be iterated by guessing code outputs and verified with a local compiler before returning an answer. But now you have taken an expensive statistical model, and "squared the square" so to speak. The compute cost explodes.
I promised to return to the fact that models are always getting better at tests, and this is a good time to do so. Because test performance is a good marketing tool, they can also create iterative modules that train on test examples. Essentially they expend large amounts of compute to reverse engineer the tests statistically, and then deploy that inverted space on "unseen" versions of the test. Yet, the model has not learned anything general, it has only learned that particular test. And so every time a new test comes out, the models are terrible until they perform that process again. This makes all intelligence tests useless. There is an unintelligent "brute force guessing" solution to every test given enough time and compute.
You will also hear people discuss "synthetic data" to train models, where they create artificial data and environments to train the models where real world data is sparse. Again, fine for systems where variance is controlled and well defined, but in general will always underestimate variance. This again leads to brittle models that are hard to generalize.
All of these tricks arose from the same problem: statistical learning doesn't scale.
This has ultimately forced all of the model builders to continuously devote more compute focused on smaller and smaller domains, as they try to find a sweet spot between generalizability and cost. In a way, it's an open admission that they have all given up on AGI, because a fully general model will never be economical. The scale they thought they needed to achieve AGI has doomed them to never find it.
Cost is the Name of the Game
AI labs have a situation where fundamentally they cannot deliver the outcome they promised with statistical models. So they are now playing tricks to make the models less general over time, which saves them some money (I assume). But the iterative modules that improve accuracy of their less general statistical systems have gobbled up any cost savings. And none of the labs have figured out how to deliver accurate outputs in any domain economically. And this is the danger: they are highly secretive of their costs.
But cost is the entire name of the game. If they cannot produce outputs in some domain competitively to human labor, they are sunk. I think the probability that they find this sweet spot is extremely low, and they can likely never recover from the cost spent overshooting on scale.
Beyond the AI labs and their statistical models, the entire AI field likely will continue to make no progress on intelligence, because they are all boxing themselves into statistical methods. And I can't blame them for that, they are using the best tools available at the time. The thing I can blame them for is not recognizing that it's a lost cause.
We have spent nearly $1T on AI buildout so far and plan to spend hundreds of billions more to pursue statistical methods of intelligence that do not scale. It's a dead end, and it is doomed to fail economically.
And we are all going to feel the fallout from the largest misallocation in world history.