@Research_FRI: 🏆 In October, we invited exter...
@Research_FRI
56 views
Jan 08, 2026
1
🏆 In October, we invited external teams to submit to ForecastBench, our AI forecasting benchmark.
The challenge? Beat superforecasters—using any tools available (scaffolding, ensembling, etc).
The result? External submissions are now the most accurate models on our leaderboard—though superforecasters still hold #1.
@xai's model (grok-4-fast) is the leading external submission, at #2.
One of Cassi's entries takes the #3 spot
Here's what changed. 🧵
The challenge? Beat superforecasters—using any tools available (scaffolding, ensembling, etc).
The result? External submissions are now the most accurate models on our leaderboard—though superforecasters still hold #1.
@xai's model (grok-4-fast) is the leading external submission, at #2.
One of Cassi's entries takes the #3 spot
Here's what changed. 🧵
2
In October, we opened up ForecastBench’s tournament leaderboard to external submissions. Teams are free to use any tools they choose.
Several teams responded, including @xai, Cassi, @fractalai, @lightningrodai, and @_Mantic_AI. Thanks to all of them for participating on this challenging benchmark.
Models from @xai and Cassi outperformed all our baseline LLM configurations.
Several teams responded, including @xai, Cassi, @fractalai, @lightningrodai, and @_Mantic_AI. Thanks to all of them for participating on this challenging benchmark.
Models from @xai and Cassi outperformed all our baseline LLM configurations.

3
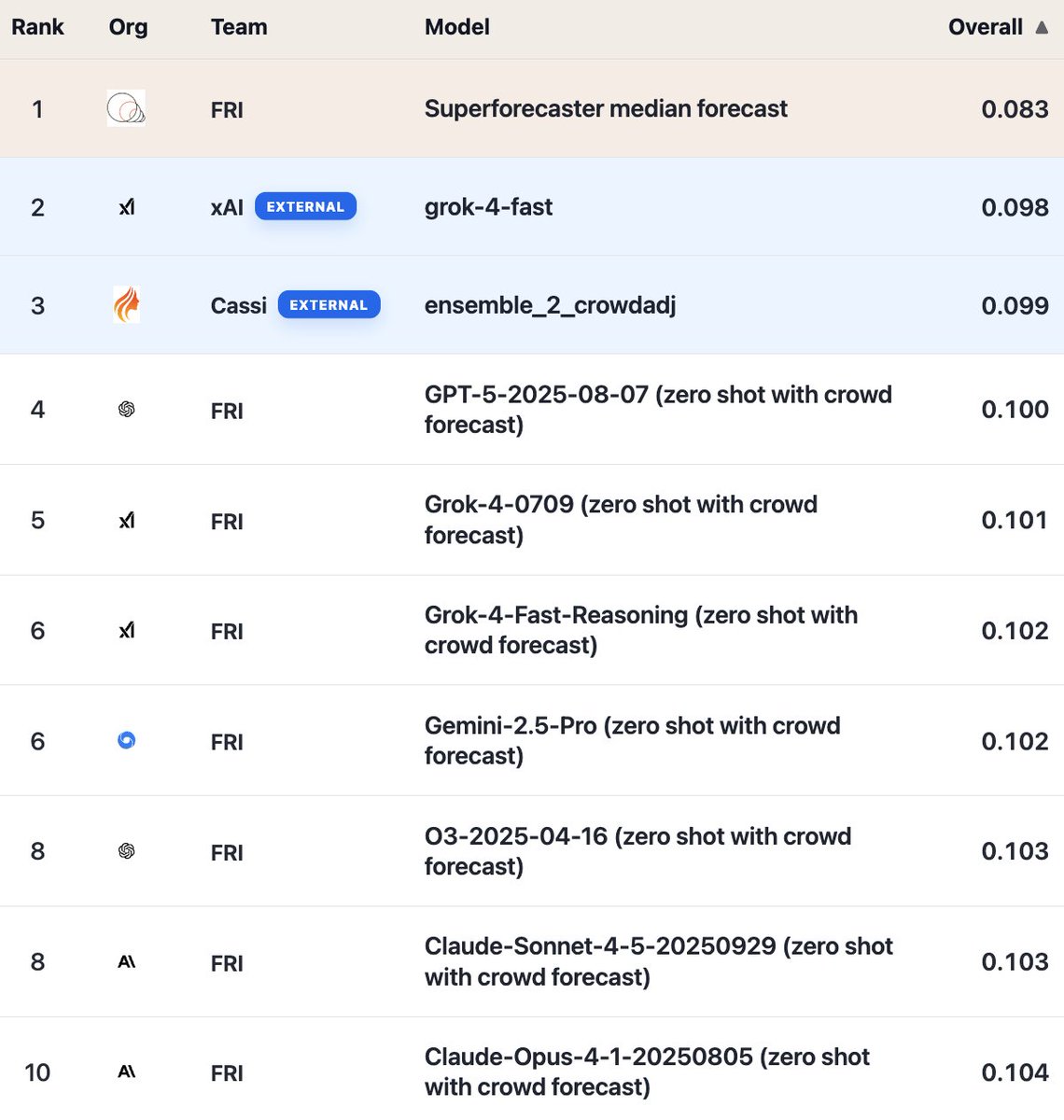
Here are the headline scores (lower is better, Brier):
• Superforecasters: 0.083
• grok-4-fast (external submission from @xai): 0.098
• ensemble_2_crowdadj (external submission from Cassi): 0.099
• @OpenAI’s GPT-5 (our own baseline run): 0.100
• @GoogleDeepMind’s Gemini-2.5-Pro (our own baseline run): 0.102
• @AnthropicAI’s Claude-Sonnet-4-5 (our own baseline run): 0.103
External submissions hold #2 and #3, ahead of all our baseline runs. However, all LLMs still lag behind superforecasters.
• Superforecasters: 0.083
• grok-4-fast (external submission from @xai): 0.098
• ensemble_2_crowdadj (external submission from Cassi): 0.099
• @OpenAI’s GPT-5 (our own baseline run): 0.100
• @GoogleDeepMind’s Gemini-2.5-Pro (our own baseline run): 0.102
• @AnthropicAI’s Claude-Sonnet-4-5 (our own baseline run): 0.103
External submissions hold #2 and #3, ahead of all our baseline runs. However, all LLMs still lag behind superforecasters.

4
Updated trend extrapolations for LLM-superforecaster parity:
• Overall: Oct 2026 (95% CI: Dec 2025 – Sep 2027)
• Dataset: May 2026 (95% CI: Oct 2025 – Jan 2027)
• Market: Apr 2026 (95% CI: Apr 2025 – Jul 2029)
Estimates remain stable (within ~1 month of our October projections) despite new models and more resolved questions.
• Overall: Oct 2026 (95% CI: Dec 2025 – Sep 2027)
• Dataset: May 2026 (95% CI: Oct 2025 – Jan 2027)
• Market: Apr 2026 (95% CI: Apr 2025 – Jul 2029)
Estimates remain stable (within ~1 month of our October projections) despite new models and more resolved questions.

5
More models are coming soon.
Mid-January:
• GPT-5.1
• Gemini 3 Pro
• Grok-4.1
• GLM-4.6
• Kimi K2 Thinking
End of January:
• Claude Opus 4.5
We add models 50 days after their first forecast to ensure enough questions have resolved for stable rankings.
Mid-January:
• GPT-5.1
• Gemini 3 Pro
• Grok-4.1
• GLM-4.6
• Kimi K2 Thinking
End of January:
• Claude Opus 4.5
We add models 50 days after their first forecast to ensure enough questions have resolved for stable rankings.
6
Think you can do better? Submit to the public leaderboard. 🚀
How to submit: github.com/forecastingres…
Explore the data:
• Leaderboards: forecastbench.org
• Full datasets: forecastbench.org/datasets/
How to submit: github.com/forecastingres…
Explore the data:
• Leaderboards: forecastbench.org
• Full datasets: forecastbench.org/datasets/