@alex_prompter: 🚨 RAG is broken and nobody's t...
@alex_prompter
49 views
Jan 01, 2026
1
🚨 RAG is broken and nobody's talking about it.
Stanford just exposed the fatal flaw killing every "AI that reads your docs" product.
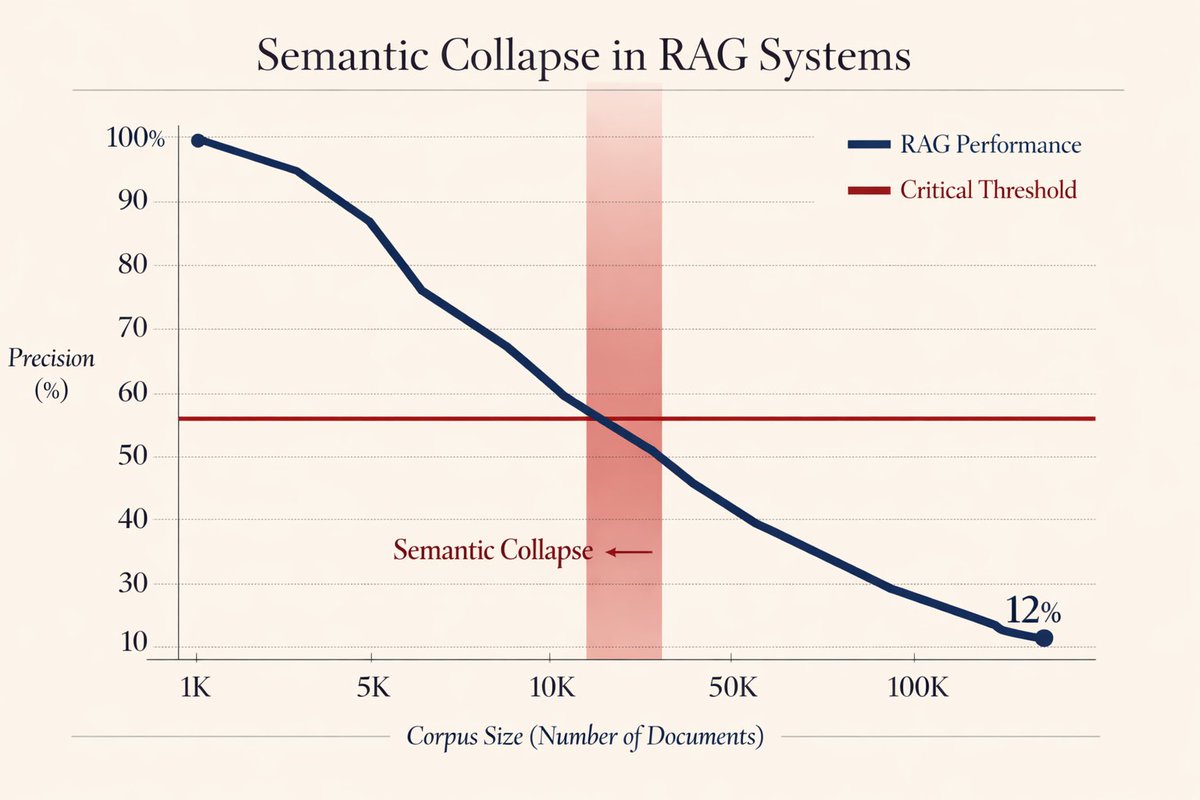
It's called "Semantic Collapse", and it happens the moment your knowledge base hits critical mass.
Here's the brutal math (and why your RAG system is already dying):
Stanford just exposed the fatal flaw killing every "AI that reads your docs" product.
It's called "Semantic Collapse", and it happens the moment your knowledge base hits critical mass.
Here's the brutal math (and why your RAG system is already dying):
2
The problem is simple but devastating.
Every document you add to RAG gets converted to a high-dimensional embedding vector (typically 768-1536 dimensions).
Past ~10,000 documents, these vectors start behaving like random noise.
Your "semantic search" becomes a coin flip.
Every document you add to RAG gets converted to a high-dimensional embedding vector (typically 768-1536 dimensions).
Past ~10,000 documents, these vectors start behaving like random noise.
Your "semantic search" becomes a coin flip.

3
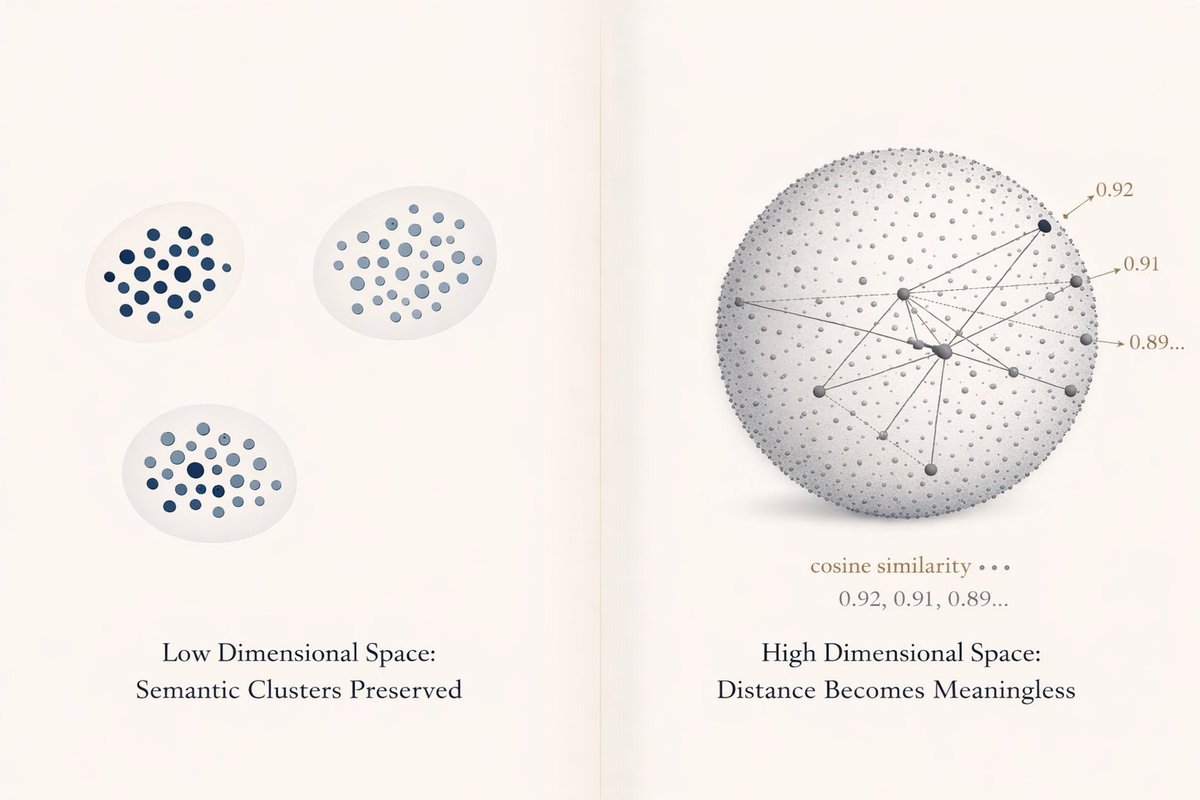
This is the Curse of Dimensionality rearing its ugly head.
In high-dimensional spaces, ALL points become equidistant from each other.
That "relevant" document? Same cosine similarity as 50 irrelevant ones.
Your retrieval just became a lottery.
In high-dimensional spaces, ALL points become equidistant from each other.
That "relevant" document? Same cosine similarity as 50 irrelevant ones.
Your retrieval just became a lottery.
4
Stanford's findings are brutal:
→ 87% precision drop at 50k+ documents
→ Semantic search worse than keyword search at scale
→ Adding more context makes hallucination WORSE, not better
We thought RAG solved hallucinations. It just hid them behind math.
→ 87% precision drop at 50k+ documents
→ Semantic search worse than keyword search at scale
→ Adding more context makes hallucination WORSE, not better
We thought RAG solved hallucinations. It just hid them behind math.

5
Here's what's actually happening:
Your embedding model projects documents into 768D space. At small scale, semantically similar docs cluster together. Perfect.
But add enough documents and the space fills up. Clusters overlap. Distances compress. Everything looks "relevant."
Your embedding model projects documents into 768D space. At small scale, semantically similar docs cluster together. Perfect.
But add enough documents and the space fills up. Clusters overlap. Distances compress. Everything looks "relevant."

6
The math is unforgiving:
Volume of a hypersphere concentrates at its surface as dimensions increase.
Translation: In 1000D space, 99.9% of your corpus lives on the outer shell, equidistant from any query.
Your "nearest neighbor search" finds... everyone.
Volume of a hypersphere concentrates at its surface as dimensions increase.
Translation: In 1000D space, 99.9% of your corpus lives on the outer shell, equidistant from any query.
Your "nearest neighbor search" finds... everyone.

7
Real-world impact:
- Enterprise RAG systems hallucinate MORE than base models
- Legal AI citing wrong precedents at scale
- Medical RAG mixing patient contexts
- Customer support bots pulling random articles
All because retrieval stopped working past 10k docs.
- Enterprise RAG systems hallucinate MORE than base models
- Legal AI citing wrong precedents at scale
- Medical RAG mixing patient contexts
- Customer support bots pulling random articles
All because retrieval stopped working past 10k docs.

8
The current "solutions" are bandaids:
→ Re-ranking (adds latency, still noisy)
→ Hybrid search (keyword + semantic, marginally better)
→ Chunking strategies (delays the problem)
None address the core issue: embeddings don't scale.
→ Re-ranking (adds latency, still noisy)
→ Hybrid search (keyword + semantic, marginally better)
→ Chunking strategies (delays the problem)
None address the core issue: embeddings don't scale.

9
What actually works:
Hierarchical retrieval with compression. Instead of flat embedding space, build a tree structure with progressive summarization.
Think: Encyclopedia → Chapter → Section → Paragraph
Reduces search space from 50k to ~200 at each hop.
Hierarchical retrieval with compression. Instead of flat embedding space, build a tree structure with progressive summarization.
Think: Encyclopedia → Chapter → Section → Paragraph
Reduces search space from 50k to ~200 at each hop.

10
Or the nuclear option: graph-based retrieval.
Model documents as nodes with explicit relationships. Query traverses edges instead of embedding space.
More complex. Way more effective. What next-gen RAG will look like.
Model documents as nodes with explicit relationships. Query traverses edges instead of embedding space.
More complex. Way more effective. What next-gen RAG will look like.

11
If you're building on RAG today:
→ Benchmark retrieval quality at YOUR scale
→ Don't trust vendor claims about "unlimited knowledge"
→ Implement hierarchical retrieval NOW
→ Monitor precision/recall, not just "it returned something"
Semantic collapse is real.
→ Benchmark retrieval quality at YOUR scale
→ Don't trust vendor claims about "unlimited knowledge"
→ Implement hierarchical retrieval NOW
→ Monitor precision/recall, not just "it returned something"
Semantic collapse is real.

12
Your premium AI bundle to 10x your business
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
→ Prompts for marketing & business
→ Unlimited custom prompts
→ n8n automations
→ Pay once, own forever
Grab it today 👇
godofprompt.ai/complete-ai-bu…
13
I hope you've found this thread helpful.
Follow me @alex_prompter for more.
Like/Repost the quote below if you can:
Follow me @alex_prompter for more.
Like/Repost the quote below if you can:
View Tweet