@alex_prompter: 🚨 DeepSeek just did something ...
@alex_prompter
59 views
Dec 02, 2025
1
🚨 DeepSeek just did something unthinkable.
They dropped DeepSeek-V3.2, and it quietly rewrites what “open-source frontier model” even means.
Instead of scaling params or throwing more GPUs, they redesigned how an LLM thinks and trains and the results feel unreal for an open model.
V3.2 shows huge jumps in reasoning, long-context stability, tool use, and RL efficiency without any mystery data or closed-weight tricks.
The wild part? The architecture stays lean, but the training pipeline is where the magic is: better gradient flow, deeper RL, smarter sampling, and a stability system that looks like something out of a private lab.
This thing matches (and occasionally dents) closed models built on 10× more compute.
Open-source isn’t “catching up” anymore.
It’s landing clean hits.
huggingface. co/deepseek-ai/DeepSeek-V3.2/
They dropped DeepSeek-V3.2, and it quietly rewrites what “open-source frontier model” even means.
Instead of scaling params or throwing more GPUs, they redesigned how an LLM thinks and trains and the results feel unreal for an open model.
V3.2 shows huge jumps in reasoning, long-context stability, tool use, and RL efficiency without any mystery data or closed-weight tricks.
The wild part? The architecture stays lean, but the training pipeline is where the magic is: better gradient flow, deeper RL, smarter sampling, and a stability system that looks like something out of a private lab.
This thing matches (and occasionally dents) closed models built on 10× more compute.
Open-source isn’t “catching up” anymore.
It’s landing clean hits.
huggingface. co/deepseek-ai/DeepSeek-V3.2/

2
1/ Stability Engineering: The Silent Breakthrough
Everyone talks about benchmarks.
V3.2’s real flex is training stability over long runs.
DeepSeek built a stabilization pipeline that fixes:
• gradient spikes
• attention drift
• late-stage collapse
• RL reward imbalance
This is why the model keeps improving deep into training while others plateau.
It isn’t luck. It’s engineering.
Everyone talks about benchmarks.
V3.2’s real flex is training stability over long runs.
DeepSeek built a stabilization pipeline that fixes:
• gradient spikes
• attention drift
• late-stage collapse
• RL reward imbalance
This is why the model keeps improving deep into training while others plateau.
It isn’t luck. It’s engineering.

3
2/ RL That Actually Scales
Instead of shallow RLHF, V3.2 pushes multi-stage RL with verifiable signals.
They use:
• answer-graded RL for math/coding
• self-verification passes
• multi-trajectory rollouts
• reward shaping tuned on real-task distributions
This gives you reasoning patterns that look deliberate:
retrying, backtracking, checking intermediate steps the stuff usually seen only in giant private models.
Instead of shallow RLHF, V3.2 pushes multi-stage RL with verifiable signals.
They use:
• answer-graded RL for math/coding
• self-verification passes
• multi-trajectory rollouts
• reward shaping tuned on real-task distributions
This gives you reasoning patterns that look deliberate:
retrying, backtracking, checking intermediate steps the stuff usually seen only in giant private models.
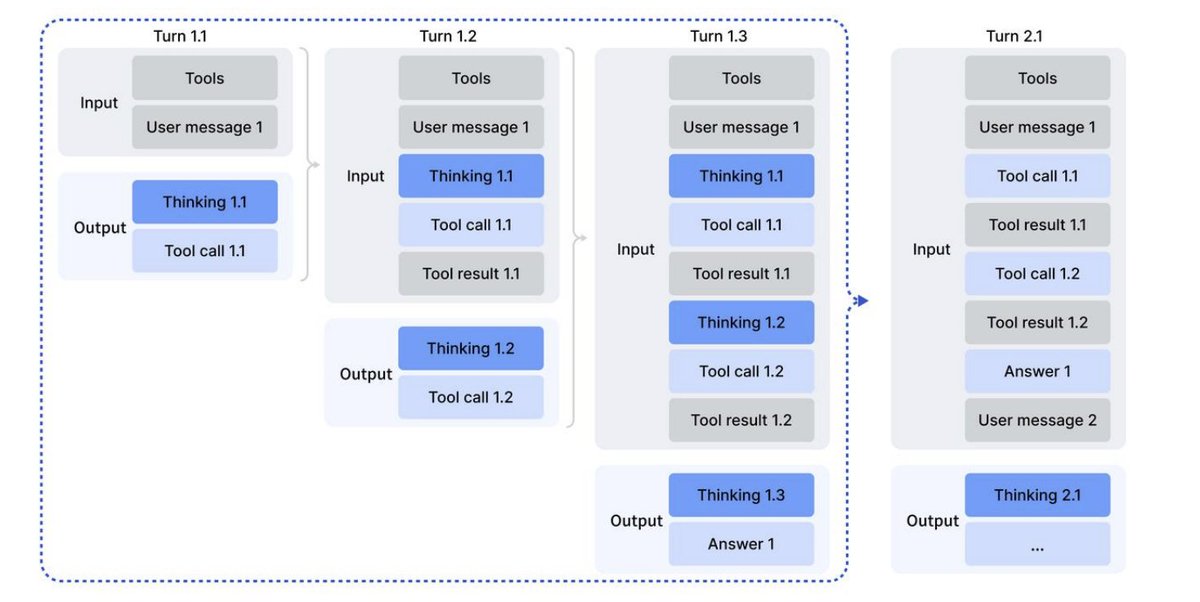
4
3/ Long-Context Without Paying the Blood Price
DeepSeek didn’t just “extend context.”
They redesigned the attention patterns so long sequences don’t torch compute.
The result:
128k+ context
Stable logits
No quality collapse
Lower cost per token compared to V3.1
This is the closest the open world has gotten to realistic long-context usability without resorting to hacks.
DeepSeek didn’t just “extend context.”
They redesigned the attention patterns so long sequences don’t torch compute.
The result:
128k+ context
Stable logits
No quality collapse
Lower cost per token compared to V3.1
This is the closest the open world has gotten to realistic long-context usability without resorting to hacks.

5
4/ Tool use
Most “open agent demos” die the moment you add real tasks.
V3.2 survives because DeepSeek trained it on actual tool-interaction traces, not synthetic roleplay.
Code tools, search tools, planning tools the model wasn’t just shown examples; it was taught workflows.
That’s why it routes steps sensibly instead of hallucinating tool calls.
Most “open agent demos” die the moment you add real tasks.
V3.2 survives because DeepSeek trained it on actual tool-interaction traces, not synthetic roleplay.
Code tools, search tools, planning tools the model wasn’t just shown examples; it was taught workflows.
That’s why it routes steps sensibly instead of hallucinating tool calls.
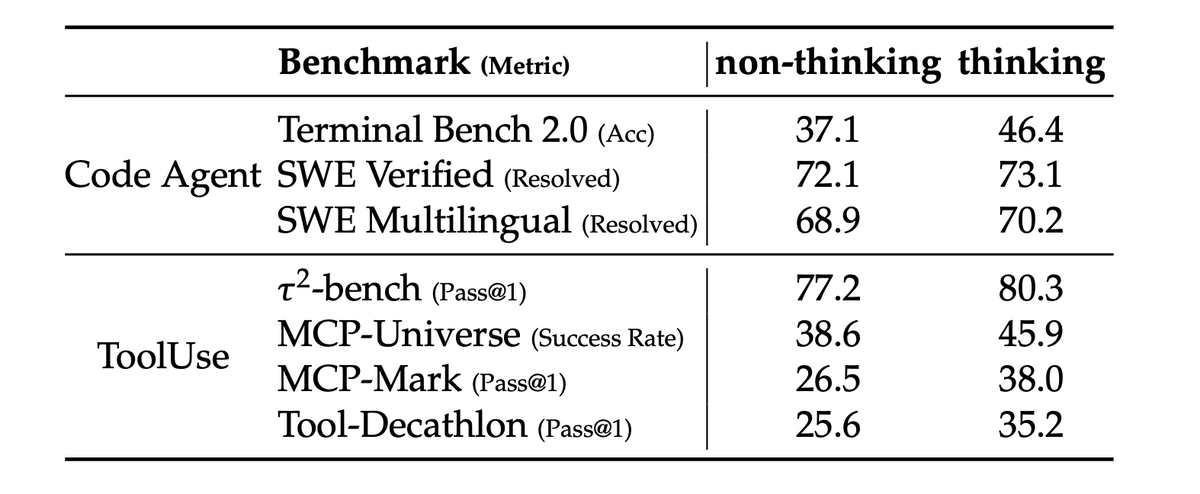
6
5/ DeepSeek-V3.2 isn’t just a model. It’s a literally a statement.
If open labs can consistently deliver this level of engineering, the moat around closed-source frontier models shrinks fast.
We might be heading toward a world where “frontier capabilities” aren’t locked behind NDAs and trillion-token budgets they’re openly published, reproducible, and accessible to anyone.
Open-source just leveled up again.
If open labs can consistently deliver this level of engineering, the moat around closed-source frontier models shrinks fast.
We might be heading toward a world where “frontier capabilities” aren’t locked behind NDAs and trillion-token budgets they’re openly published, reproducible, and accessible to anyone.
Open-source just leveled up again.

7
The AI prompt library your competitors don't want you to find
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing
→ Biggest collection of text & image prompts
→ Unlimited custom prompts
→ Lifetime access & updates
Grab it before it's gone 👇
godofprompt.ai/pricing