@_avichawla: A new embedding model cuts vec...
@_avichawla
8 views
Aug 14, 2025
1
A new embedding model cuts vector DB costs by ~200x.
It also outperforms OpenAI and Cohere models.
Here's a complete breakdown (with visuals):
It also outperforms OpenAI and Cohere models.
Here's a complete breakdown (with visuals):
2
RAG is 80% retrieval and 20% generation.
So if RAG isn't working, most likely, it's a retrieval issue, which further originates from chunking and embedding.
Contextualized chunk embedding models solve this.
Let's dive in to learn more!
So if RAG isn't working, most likely, it's a retrieval issue, which further originates from chunking and embedding.
Contextualized chunk embedding models solve this.
Let's dive in to learn more!
3
In RAG:
- No chunking drives up token costs
- Large chunks lose fine-grained context
- Small chunks lose global/neighbourhood context
In fact, chunking also involves determining chunk overlap, generating summaries, etc., which are tedious.
There's another problem!
- No chunking drives up token costs
- Large chunks lose fine-grained context
- Small chunks lose global/neighbourhood context
In fact, chunking also involves determining chunk overlap, generating summaries, etc., which are tedious.
There's another problem!
4
Despite tuning and balancing tradeoffs, the final chunk embeddings are generated independently with no interaction with each other.
This isn't true with real-world docs, which have long-range dependencies.
Check this 👇
This isn't true with real-world docs, which have long-range dependencies.
Check this 👇
5
voyage-context-3 embedding model by @MongoDB solves this.
It is a contextualized chunk embedding model that produces vectors for chunks that capture the full document context without any manual metadata and context augmentation.
Check this visual 👇
It is a contextualized chunk embedding model that produces vectors for chunks that capture the full document context without any manual metadata and context augmentation.
Check this visual 👇
6
Technically, unlike traditional chunk embedding, the model processes the entire doc in a single pass to embed each chunk.
This way, it sees all the chunks at the same time to generate global document-aware chunk embeddings.
This gives semantically aware retrieval in RAG.
This way, it sees all the chunks at the same time to generate global document-aware chunk embeddings.
This gives semantically aware retrieval in RAG.
7
Across 93 retrieval datasets, spanning nine domains (web reviews, law, medical, long documents, etc.):
voyage-context-3 outperforms:
- all models across all domains
- OpenAI-v3-large by 14.2%
- Cohere-v4 by 7.89%
- Jina-v3 by 23.66%
Check this 👇
voyage-context-3 outperforms:
- all models across all domains
- OpenAI-v3-large by 14.2%
- Cohere-v4 by 7.89%
- Jina-v3 by 23.66%
Check this 👇

8
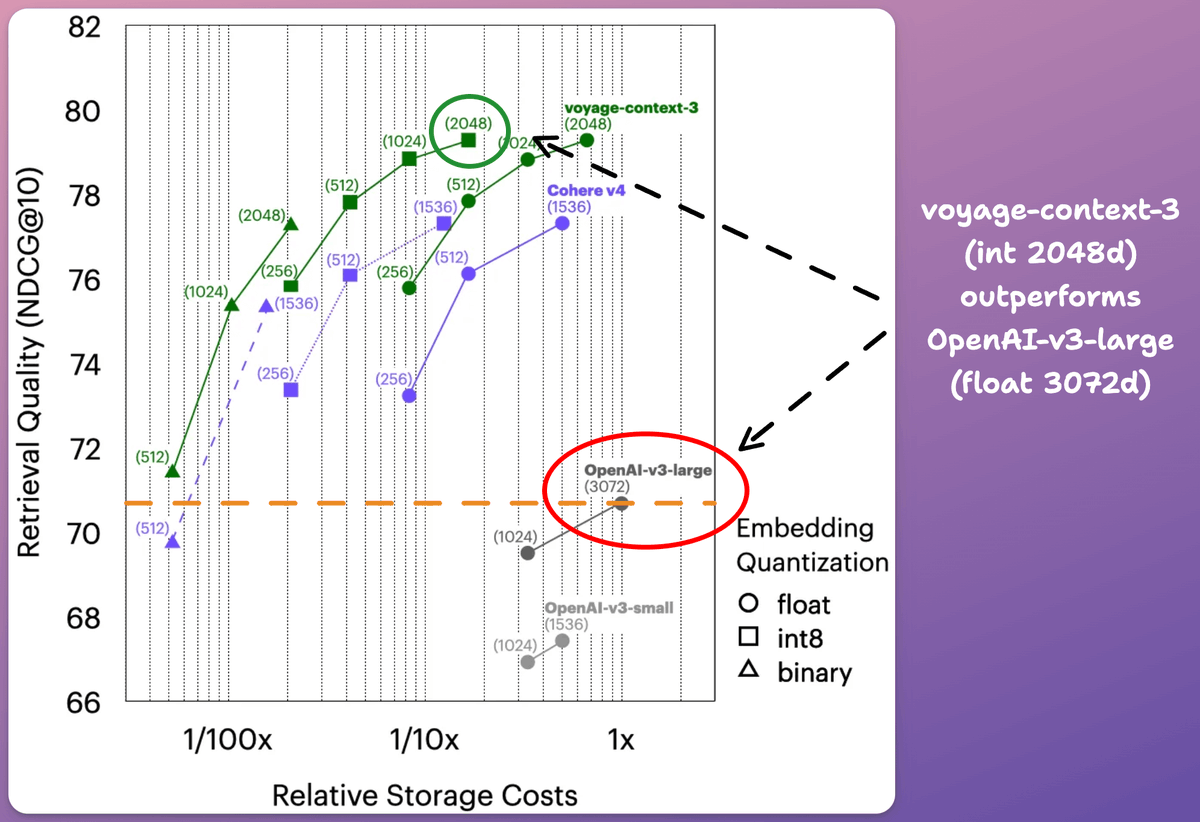
voyage-context-3 supports 2048, 1024, 512, and 256 dimensions with quantization.
Compared to OpenAI-v3-large (float, 3072d), voyage-context-3 (int8, 2048):
- delivers 83% lower vector DB costs
- provides 8.60% better retrieval quality
Check this 👇
Compared to OpenAI-v3-large (float, 3072d), voyage-context-3 (int8, 2048):
- delivers 83% lower vector DB costs
- provides 8.60% better retrieval quality
Check this 👇
9
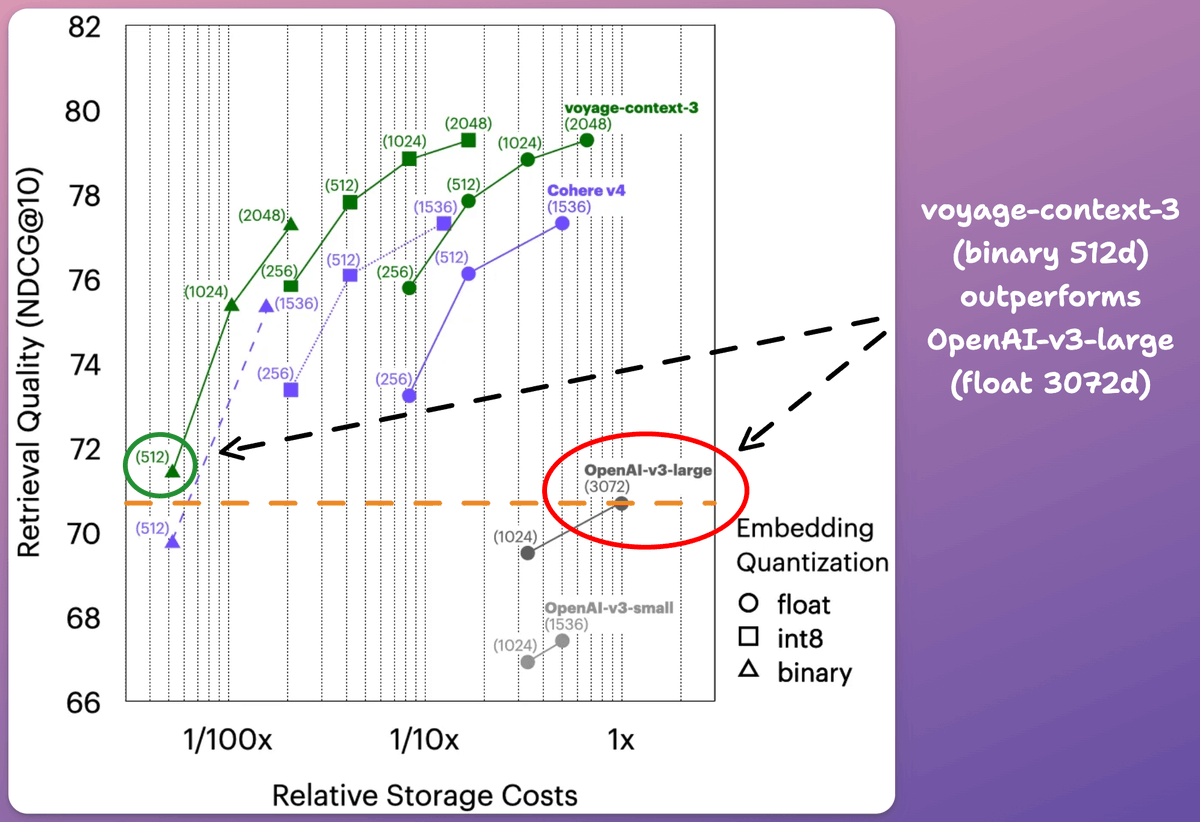
Compared to OpenAI-v3-large (float, 3072d). voyage-context-3 (binary, 512):
- 99.48% lower vector DB costs.
- 0.73% better retrieval quality.
Check this 👇
- 99.48% lower vector DB costs.
- 0.73% better retrieval quality.
Check this 👇
10
In terms of practical usage...
voyage-context-3 is a drop-in replacement for standard embeddings without downstream workflow changes.
So you can start using it by just changing the model name.
Find the docs here: fnf.dev/4m4bW1H
voyage-context-3 is a drop-in replacement for standard embeddings without downstream workflow changes.
So you can start using it by just changing the model name.
Find the docs here: fnf.dev/4m4bW1H
11
To recap, instead of producing independent chunk embeddings, contextualized chunk embedding models like voyage-context-3 process the entire doc in a single pass to embed each chunk.
This leads to document-aware chunk embeddings that generate semantically aware retrieval in RAG.
Check the visual below 👇
Thanks to the #MongoDB team for working with me on this thread!
This leads to document-aware chunk embeddings that generate semantically aware retrieval in RAG.
Check the visual below 👇
Thanks to the #MongoDB team for working with me on this thread!
12
If you found it insightful, reshare it with your network.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
Find me → @_avichawla
Every day, I share tutorials and insights on DS, ML, LLMs, and RAGs.
View Tweet