@rohanpaul_ai: MASSIVE claim in this paper. ...
@rohanpaul_ai
56 views
Jul 27, 2025
1
MASSIVE claim in this paper.
AI Architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process.
So it turns architecture discovery into a compute‑bound process, opening a path to self‑accelerating model evolution without waiting for human intuition.
The paper shows that an all‑AI research loop can invent novel model architectures faster than humans, and the authors prove it by uncovering 106 record‑setting linear‑attention designs that outshine human baselines.
Right now, most architecture search tools only fine‑tune blocks that people already proposed, so progress crawls at the pace of human trial‑and‑error.
🧩 Why we needed a fresh approach
Human researchers tire quickly, and their search space is narrow. As model families multiply, deciding which tweak matters becomes guesswork, so whole research agendas stall while hardware idles.
🤖 Meet ASI‑ARCH, the self‑driving lab
The team wired together three LLM‑based roles. A “Researcher” dreams up code, an “Engineer” trains and debugs it, and an “Analyst” mines the results for patterns, feeding insights back to the next round. A memory store keeps every motivation, code diff, and metric so the agents never repeat themselves.
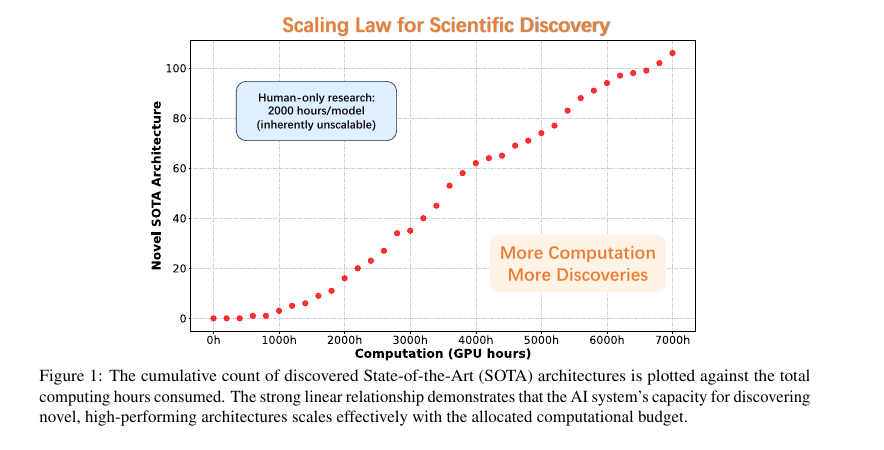
📈 Across 1,773 experiments and 20,000 GPU hours, a straight line emerged between compute spent and new SOTA hits.
Add hardware, and the system keeps finding winners without extra coffee or conferences.
AI Architectural breakthroughs can be scaled computationally, transforming research progress from a human-limited to a computation-scalable process.
So it turns architecture discovery into a compute‑bound process, opening a path to self‑accelerating model evolution without waiting for human intuition.
The paper shows that an all‑AI research loop can invent novel model architectures faster than humans, and the authors prove it by uncovering 106 record‑setting linear‑attention designs that outshine human baselines.
Right now, most architecture search tools only fine‑tune blocks that people already proposed, so progress crawls at the pace of human trial‑and‑error.
🧩 Why we needed a fresh approach
Human researchers tire quickly, and their search space is narrow. As model families multiply, deciding which tweak matters becomes guesswork, so whole research agendas stall while hardware idles.
🤖 Meet ASI‑ARCH, the self‑driving lab
The team wired together three LLM‑based roles. A “Researcher” dreams up code, an “Engineer” trains and debugs it, and an “Analyst” mines the results for patterns, feeding insights back to the next round. A memory store keeps every motivation, code diff, and metric so the agents never repeat themselves.
📈 Across 1,773 experiments and 20,000 GPU hours, a straight line emerged between compute spent and new SOTA hits.
Add hardware, and the system keeps finding winners without extra coffee or conferences.

2
📈 Across 1,773 experiments and 20,000 GPU hours, a straight line emerged between compute spent and new SOTA hits.
Add hardware, and the system keeps finding winners without extra coffee or conferences.
Add hardware, and the system keeps finding winners without extra coffee or conferences.
3
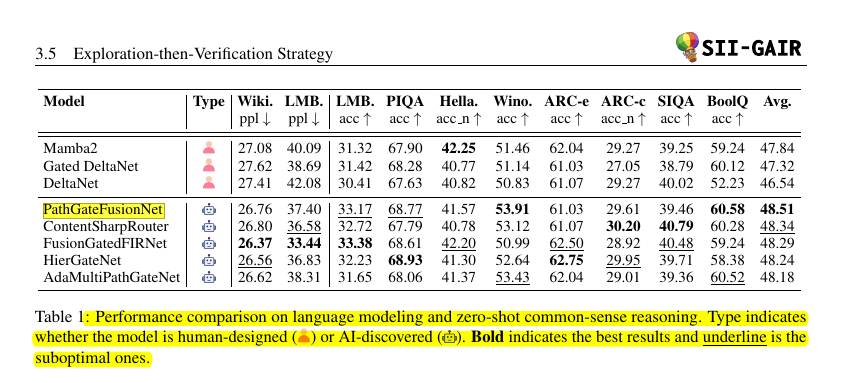
Examples like PathGateFusionNet, ContentSharpRouter, and FusionGatedFIRNet beat Mamba2 and Gated DeltaNet on reasoning suites while keeping parameter counts near 400M. Each one solves the “who gets the compute budget” problem in a new way, often by layering simple per‑head gates instead of a single softmax.
4
🔍 Patterns the agents uncovered
The chart compares how often each component shows up in 106 winning architectures versus 1,667 discarded ones.
Gating layers and small convolutions dominate both groups at roughly 14% and 12% usage, while staples like residual links and feature pooling follow close behind. Exotic pieces, such as physics‑inspired or spectral tricks, hardly appear in the successful set.
The pattern is clear, the top models lean on a tight, proven toolkit, whereas the larger pool experiments with a very long list of rare ideas that rarely pay off. In other words, focused refinement of well‑tested components beats wide exploration when the goal is higher benchmark scores and lower loss.
The chart compares how often each component shows up in 106 winning architectures versus 1,667 discarded ones.
Gating layers and small convolutions dominate both groups at roughly 14% and 12% usage, while staples like residual links and feature pooling follow close behind. Exotic pieces, such as physics‑inspired or spectral tricks, hardly appear in the successful set.
The pattern is clear, the top models lean on a tight, proven toolkit, whereas the larger pool experiments with a very long list of rare ideas that rarely pay off. In other words, focused refinement of well‑tested components beats wide exploration when the goal is higher benchmark scores and lower loss.

5